各位早安,書接上回我們將程式碼改得更方便閱讀,還加上抓取連結的功能,今天我們要來把這些抓到的資料存起來方便我們去使用
我們經過前天的優化是讓資料的內容更方便使用
今天我們要來讓它變成可以存放也可以單獨使用的檔案
而這就要用到昨天介紹過的 python 的檔案讀寫
file = open(檔名, 模式, 編碼)
file.write()
file.close()
要把資料存起來首先面對的第一個難題是要把開關寫入檔案放在哪
最後我選擇把它放在最外面的 for 迴圈內 因為如果放在 getData() 裡面
會開關檔比較多次 對運算的負擔比較大
第二個難題是 getData() 原本是 return 下一頁網址也就是一個字串而已
但是現在有整頁的標題加上 URL 所以很明顯不能再 return 一個字串而已了
所以我最後選擇使用 list 來當作 return 的對象 能完美放入大量資料
原本的 URL 我選擇放在 list 的第一格 也就是 [0] 的位置
所以首先我把所有 url 變數都改成 infor 並把第一頁的網址存成 list
接下來
把 request 裡的 infor 加上 [0]
因為我們的 list infor 內第一個位置 infor[0] 就是專門用來放 URL 的
再來是把原本印出所有標題加連結的 for 迴圈
for title in titles:
if title.a != None:
if "兔" not in title.a.text:
print("https://www.ptt.cc"+title.a["href"],title.a.text)
改成這樣
i = 1
for title in titles:
if title.a != None:
if "兔" not in title.a.text:
infor.insert(i, "https://www.ptt.cc"+title.a["href"]+" "+title.a.text+"\n")
i = i+1
就是把原本印出的功能換成 infor.insert 也就是新增進 infor 內
insert(位置編號, 資料)
i 是設計用來讓資料被依序放入從 [1] 開始的位置內 (因為 [0] 用來放翻頁用的 URL 了)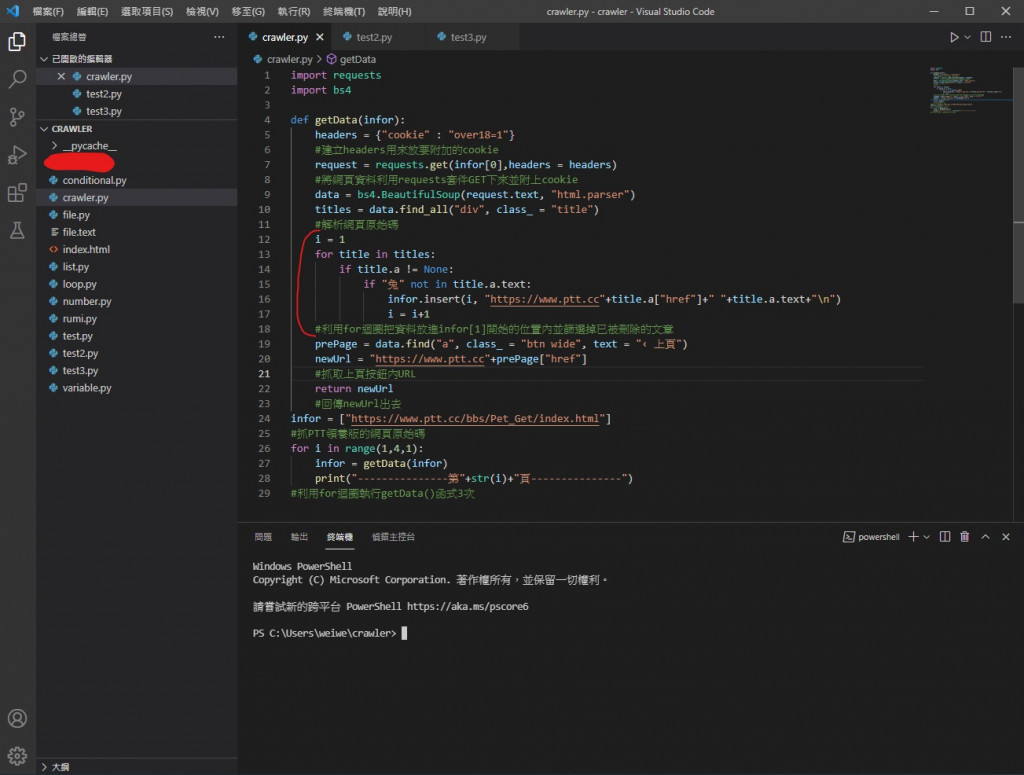
再來就是要處理輸出的部分
我們要把 newUrl 放到 infor[0] 裡
return newUrl
把它改成
infor[0] = newUrl
return infor
最後就是改外面的 for 迴圈並加上 把資料存檔的功能
for i in range(1,4,1):
infor = getData(infor)
print("---------------第"+str(i)+"頁---------------")
改成
file = open("Pet_Get.txt", "w", encoding="utf-8")
for i in range(1,4,1):
infor = getData(infor)
file.write("--------------------第"+str(i)+"頁--------------------\n")
for inf in infor:
file.write(inf)
file.close()
print("爬完了")
首先第一行開檔 模式是寫入 編碼 utf-8 特別編碼是因為沒指定編碼系統讀不懂
再來第二第三行 for 迴圈是讓他跑進 getData() 內執行功能
並帶出我們要的 infor (裝著滿滿資料)
第四行是用來隔頁方便閱讀的
第五第六行是用來寫入的 for 迴圈 它會把 infor 內的資料都寫進去
第七行關檔
第八行用來顯示執行完成
可以看到跑出我們寫入的檔案了 (系統建立的)
把它打開來看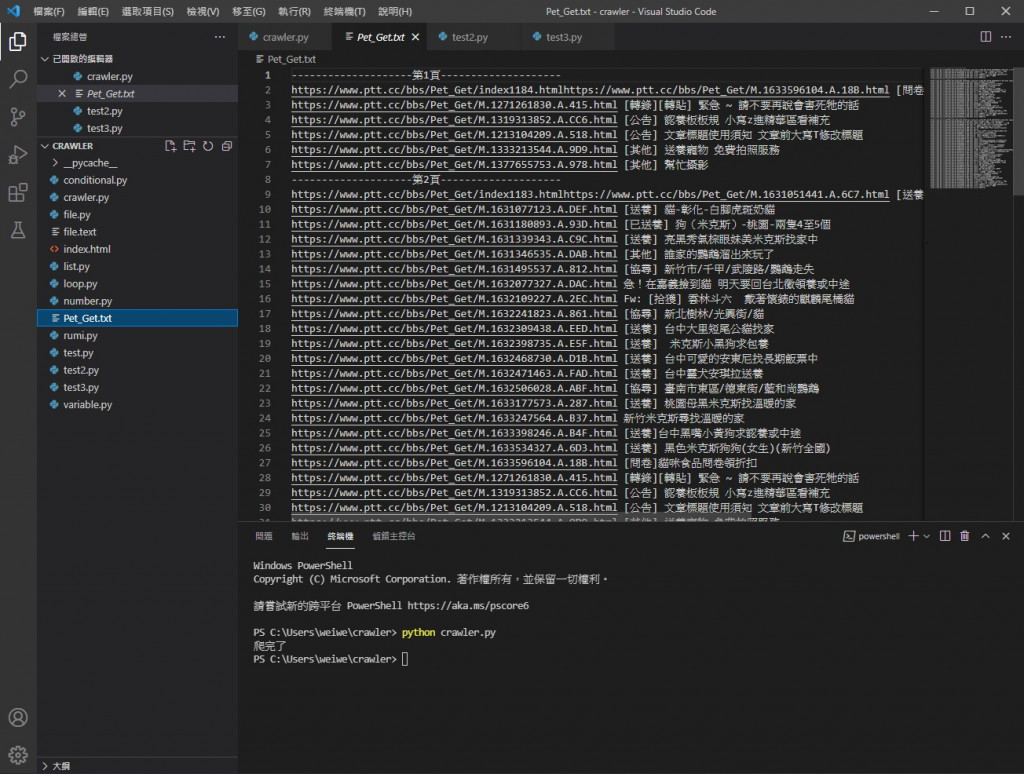
可以看到我們爬取的資料都寫進來了
也可以直接從外面看
它被建立在跟我們python檔案同一個資料夾裡
也就是終端執行的位置 C:\Users\你的名字\crawler
打開來看看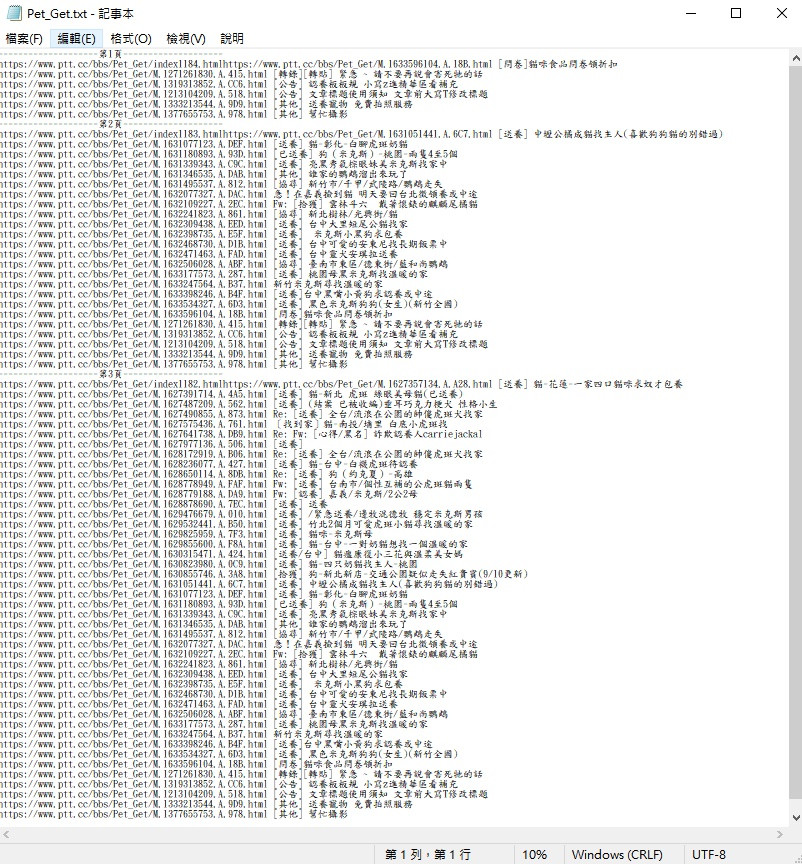
我們爬蟲抓到的資料都在這裡
太好了大成功~
今天的程式碼
import requests
import bs4
def getData(infor):
headers = {"cookie" : "over18=1"}
#建立headers用來放要附加的cookie
request = requests.get(infor[0],headers = headers)
#將網頁資料利用requests套件GET下來並附上cookie
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析網頁原始碼
i = 1
for title in titles:
if title.a != None:
if "兔" not in title.a.text:
infor.insert(i, "https://www.ptt.cc"+title.a["href"]+" "+title.a.text+"\n")
i = i+1
#利用for迴圈把資料放進infor[1]開始的位置內並篩選掉已被刪除的文章
prePage = data.find("a", class_ = "btn wide", text = "‹ 上頁")
newUrl = "https://www.ptt.cc"+prePage["href"]
#抓取上頁按鈕內URL
infor[0] = newUrl
return infor
#將newUrl放進infor[0]再把infor傳出去
infor = ["https://www.ptt.cc/bbs/Pet_Get/index.html"]
#抓PTT領養版的網頁原始碼
file = open("Pet_Get.txt", "w", encoding="utf-8")
for i in range(1,4,1):
infor = getData(infor)
file.write("--------------------第"+str(i)+"頁--------------------\n")
for inf in infor:
file.write(inf)
file.close()
print("爬完了")
#寫入資料
今天我們成功把文章標題跟連結抓下來存起來了 明天我們要再優化我們的爬蟲
參考資料
https://medium.com/ccclub/ccclub-python-for-beginners-tutorial-bf0648108581
https://selflearningsuccess.com/python-for-loop/
http://kaiching.org/pydoing/py/python-return.html
https://www.runoob.com/python/att-list-insert.html
https://segmentfault.com/q/1010000007854405/a-1020000007854709
https://oxygentw.net/blog/computer/python-file-utf8-encoding/
https://www.itread01.com/content/1549631901.html
https://www.runoob.com/python/file-methods.html
法國人做出了會飛的雨傘喔
如果必須選你會選擇超熱大晴天還是傾盆大雷雨呢

