各位早安,書接上回我們將程式碼的規模擴大成多檔案的規模,也發現了三個大問題,今天我們就要來解決它並順便小小優化一下程式碼
昨天我發現的三個問題
1.第一行文章的原網址沒有換行 導致第一篇文章被往後擠不好看
2.文章原網址竟然是下一頁的...
3.標題竟然越來越多???
今天我們要來一一解決它
這個問題不能簡單在放入 infor 時加上 "\n" 就好
因為輸出網址時多一個 "\n" 就會找不到網頁
當然可以利用字串的新增刪除來解決
但是那樣就必須在寫入時加進去又在讀出來時刪掉很麻煩
所以我想了更好的方法來解決 跟第二個問題一起處理
這個問題就是我的程式結構有問題 本來以為很難處理
結果在想怎麼解決第一個問題時就順便解決了
因為原本是在 getData(infor) 內就先抓到下一頁連結並存入 infor 內一起丟出去
所以外面得到的文章原網址已經是下一頁的了
我想到的方法是把文章的原網址跟其他資料分開寫入
並且改變一下順序在進去跑 getData(infor) 之前先寫入文章原網址進去
之後再寫入文章標題跟 URL
做法是把
for x in range(1,4,1):
file = open("Pet_Get"+str(x)+".txt", "w", encoding="utf-8")
for i in range(1,6,1):
infor = getData(infor)
file.write("--------------------第"+str(i)+"頁--------------------\n")
for inf in infor:
file.write(inf)
file.close()
改成
for x in range(1,4,1):
file = open("Pet_Get"+str(x)+".txt", "w", encoding="utf-8")
for i in range(1,6,1):
file.write("--------------------第"+str(i)+"頁--------------------\n")
file.write(infor[0]+"\n")
infor = getData(infor)
for inf in infor[1:]:
file.write(inf)
file.close()
把寫入頁數提到前面
再將文章的原網址跟其他資料分開寫入並改到 getData(infor) 前寫入
寫入文章的原網址改在這裡寫入也就可以只在寫入檔案時加上 "\n" 而不用
然後第二層迴圈才把剩下的部分也就是文章標題跟 URL 寫入
這樣就能解決了
改之前的檔案內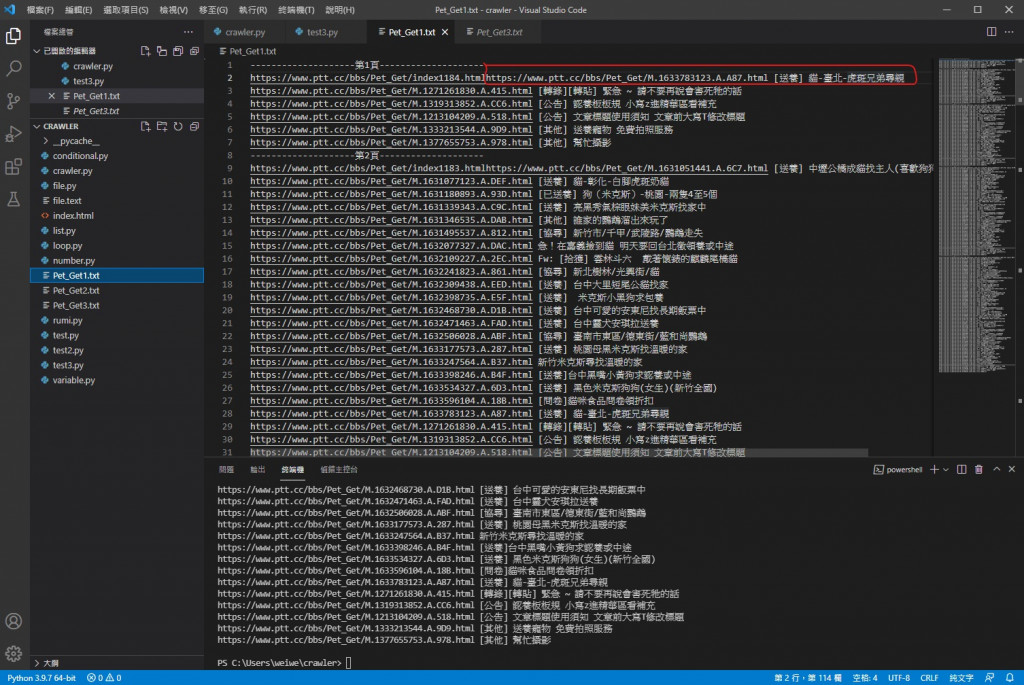
改完之後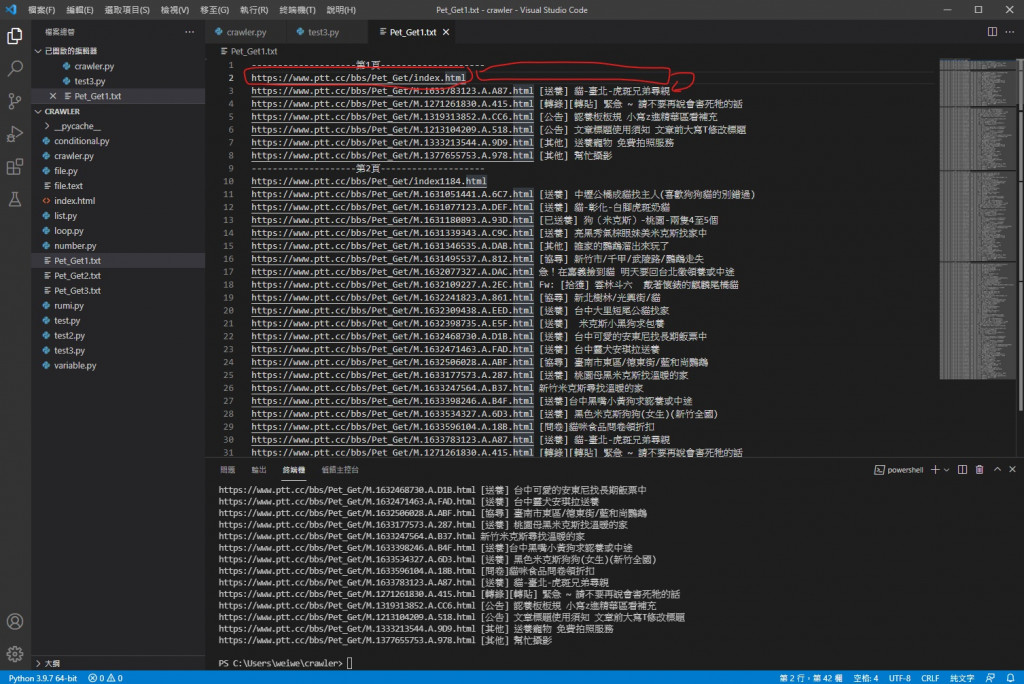
可以看到換行跟文章原網址錯頁的問題解決了
經過多次觀察跟分析比對 我最終發現文章標題越來越多是因為我使用的 insert( )
我忘記它是新增元素不是取代了
所以導致 infor 內元素越來越多
所以只要在合適的位置清空它即可
正確的位置是在 request 用完上一頁的 URL 之後清空它
簡單的 infor = [""] 就可以處理了
改之前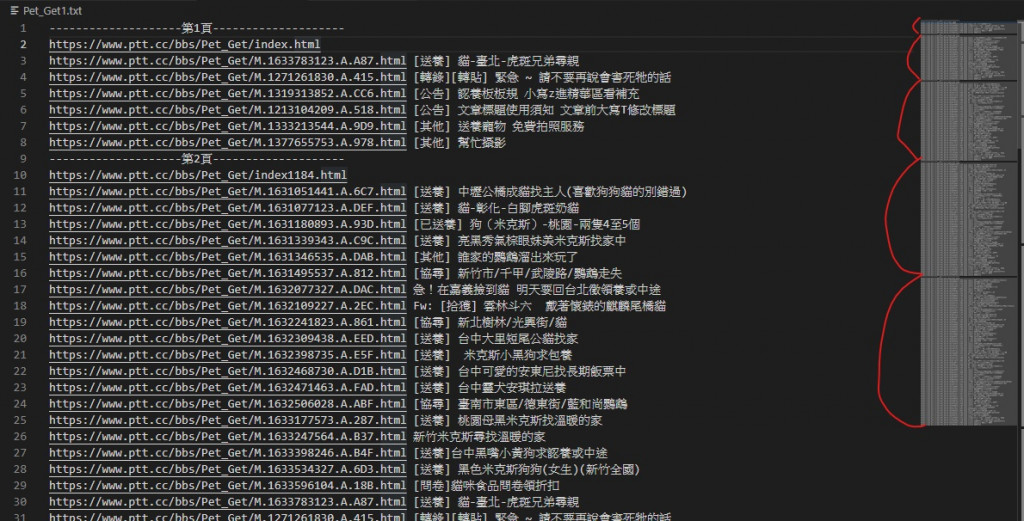
改之後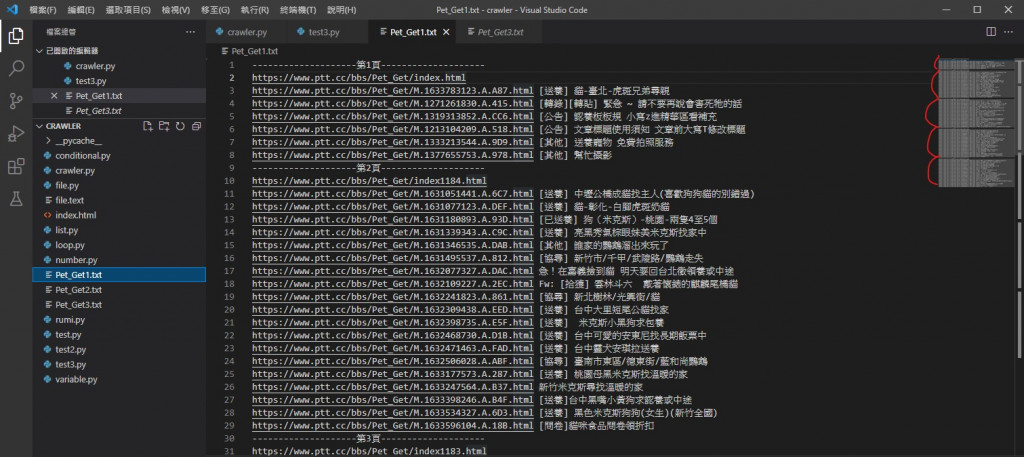
可以看到明顯變少也不再遞增而是差不多了
文章數量也跟網站上一致
把for迴圈內建立變數讓我們能更直觀的設定檔案數量跟每個檔案放內幾頁
再加上能檔案間疊加顯示爬到第幾頁的小小功能
for x in range(1,4,1):
file = open("Pet_Get"+str(x)+".txt", "w", encoding="utf-8")
for i in range(1,6,1):
file.write("--------------------第"+str(i)+"頁--------------------\n")
file.write(infor[0]+"\n")
infor = getData(infor)
for inf in infor[1:]:
file.write(inf)
file.close()
for x in range(1,4,1):
read = open("Pet_Get"+str(x)+".txt", encoding="utf-8")
print(read.read())
read.close()
Number_of_files = 3
Number_of_pages = 5
for x in range(1,Number_of_files+1,1):
file = open("Pet_Get"+str(x)+".txt", "w", encoding="utf-8")
for i in range(1,Number_of_pages+1,1):
file.write("--------------------第"+str(Number_of_pages*(x-1)+i)+"頁--------------------\n")
file.write(infor[0]+"\n")
infor = getData(infor)
for inf in infor[1:]:
file.write(inf)
file.close()
for x in range(1,Number_of_files+1,1):
read = open("Pet_Get"+str(x)+".txt", encoding="utf-8")
print(read.read())
read.close()
可以看到不再都是1~5頁了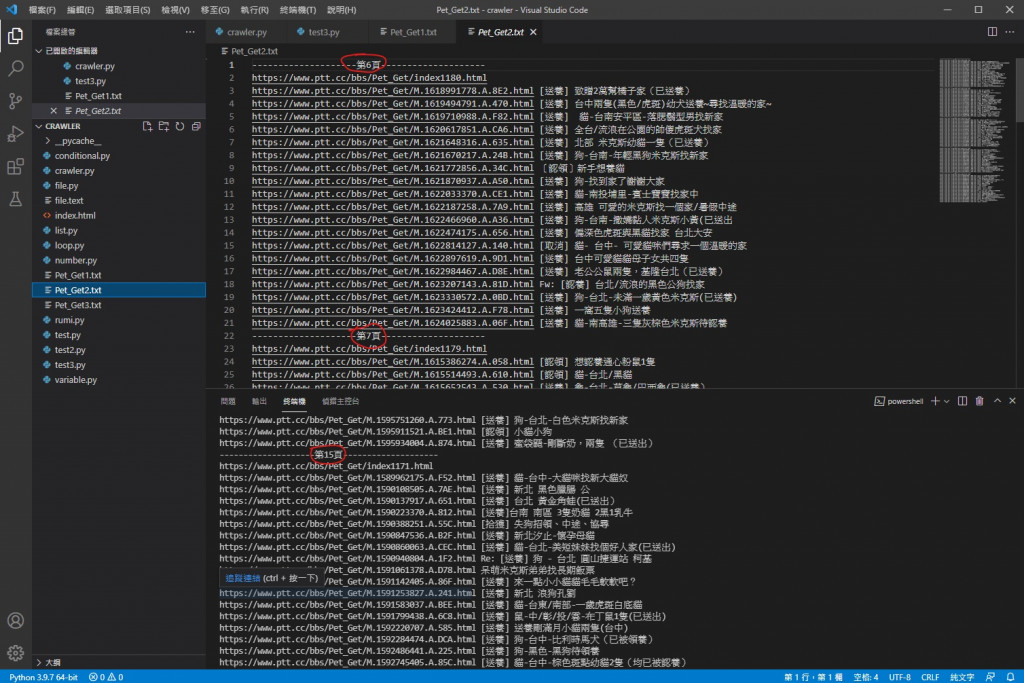
讚讚
import requests
import bs4
def getData(infor):
headers = {"cookie" : "over18=1"}
#建立headers用來放要附加的cookie
request = requests.get(infor[0],headers = headers)
#將網頁資料利用requests套件GET下來並附上cookie
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析網頁原始碼
infor = [""]
#將infor內清空
i = 1
for title in titles:
if title.a != None:
if "兔" not in title.a.text:
infor.insert(i, "https://www.ptt.cc"+title.a["href"]+" "+title.a.text+"\n")
i = i+1
#利用for迴圈把資料放進infor[1]開始的位置內並篩選掉已被刪除的文章
prePage = data.find("a", class_ = "btn wide", text = "‹ 上頁")
newUrl = "https://www.ptt.cc"+prePage["href"]
#抓取上頁按鈕內URL
infor[0] = newUrl
return infor
#將newUrl放進infor[0]再把infor傳出去
infor = ["https://www.ptt.cc/bbs/Pet_Get/index.html"]
#抓PTT領養版的網頁原始碼
Number_of_files = 3
Number_of_pages = 5
#設變數方便設定檔案數跟頁數
for x in range(1,Number_of_files+1,1):
file = open("Pet_Get"+str(x)+".txt", "w", encoding="utf-8")
for i in range(1,Number_of_pages+1,1):
file.write("--------------------第"+str(Number_of_pages*(x-1)+i)+"頁--------------------\n")
file.write(infor[0]+"\n")
infor = getData(infor)
for inf in infor[1:]:
file.write(inf)
file.close()
#寫入資料
for x in range(1,Number_of_files+1,1):
read = open("Pet_Get"+str(x)+".txt", encoding="utf-8")
print(read.read())
read.close()
#讀取檔案中資料並印出
持續改進到今天它已經是一隻功能相對完整的程式了
希望大家可以利用它在PTT上找到更多有用的資訊 也能遇見合適的浪浪給牠們一個溫暖的家
當然也能用在其他任何需要的地方 那實作皆屬個人行為 筆者不付任何法律責任
希望大家能把爬蟲用在好的地方讓生活更方便
羅馬帝國可能是因為在供水管線大量使用鉛而導致鉛中毒而衰敗的喔
如果必須選你會吃花生醬味道的大便還是大便味道的花生醬呢

