各位早安,書接上回我們介紹了如何抓取圖片 URL 並儲存圖片,今天我們要結合之前的爬蟲功能從網站上抓到圖片連結再把圖片存下來
我今天程式的邏輯是
先把網頁原始碼 GET 下來分析後 再把圖片連結所在的 < img > src 內的資料提出來
這個資料就是圖片的 URL
之後再對圖片的 URL 做 GET 的動作並轉成二進位制
最後開檔把這筆二進位制的圖片資訊存進去 再關檔
最後是把這些過程加上正確位置的迴圈就能把網頁上所有圖片都存下來
程式碼
import requests #用來對網站發出請求的套件
import os #用來處理資料夾的套件
import bs4 #用來解析HTML的套件
def saveImage(postUrl): #建立函式方便使用
request = requests.get(postUrl) #對網頁發出請求
data = bs4.BeautifulSoup(request.text, "html.parser") #以HTML格式解析網頁原始碼
imageData = data.find_all('img') #抓取所有有<img>標籤內的資料
path = r"C:\Users\weiwe\crawler\pet_get" #存放照片的路徑
if (os.path.exists(path) == False): #判斷主資料夾是否存在
os.makedirs(path) #不存在就建立一個
imgList = [] #建立LIST用來放圖片URL
lenth = len(imageData) #建立變數紀錄imageData內有幾筆資料
for x in range(lenth): #建立用來迴圈放全部圖片URL 有幾個就放幾次
imgList.insert(x,imageData[x].attrs["src"]) #抓到src內的圖片連結並新增進imgList內
for i in range(lenth): #用來印出全部圖片
getImage = requests.get(imgList[i]) #抓取圖片URL
image = getImage.content #將圖片資訊轉成二進位制
imageSave = open(path+"\img"+str(i)+".png","wb") #建立檔案
imageSave.write(image) #將圖片資訊寫入檔案內
imageSave.close() #關檔
print("img"+str(i)+".png"+"下載成功") #告知該圖片儲存成功
postUrl = "https://www.ptt.cc/bbs/Pet_Get/M.1631051441.A.6C7.html" #欲抓取圖片之網頁的URL
saveImage(postUrl) #執行函式
print("下載完成") #告知程式結束
執行結果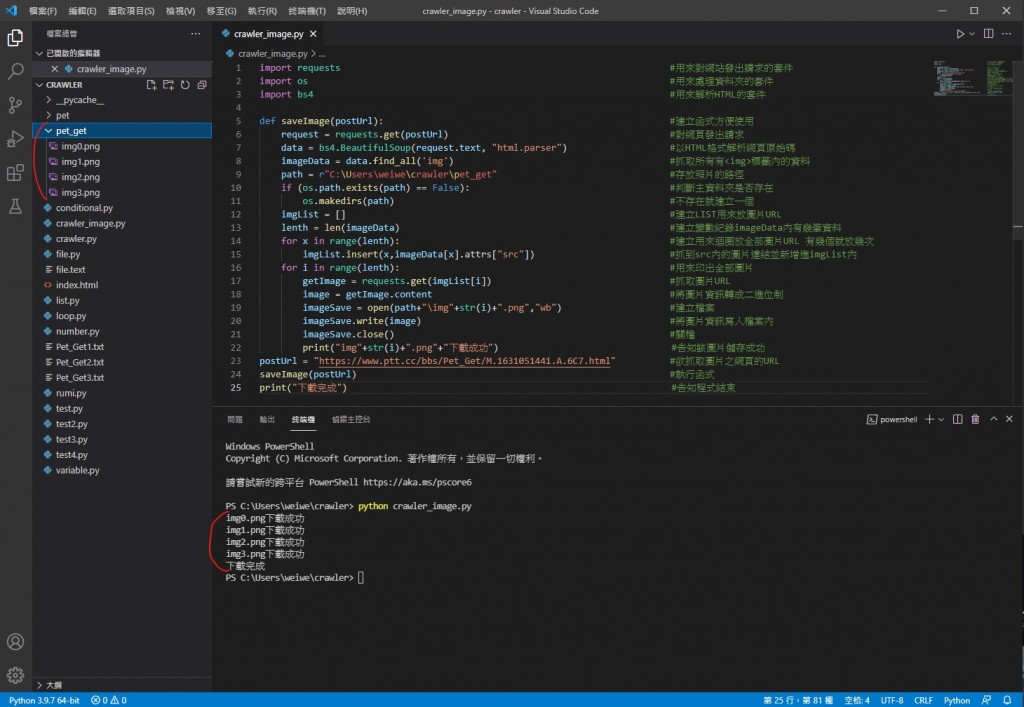
可以看到圖片都儲存成功了
接著我們看裡面的檔案
img0
img1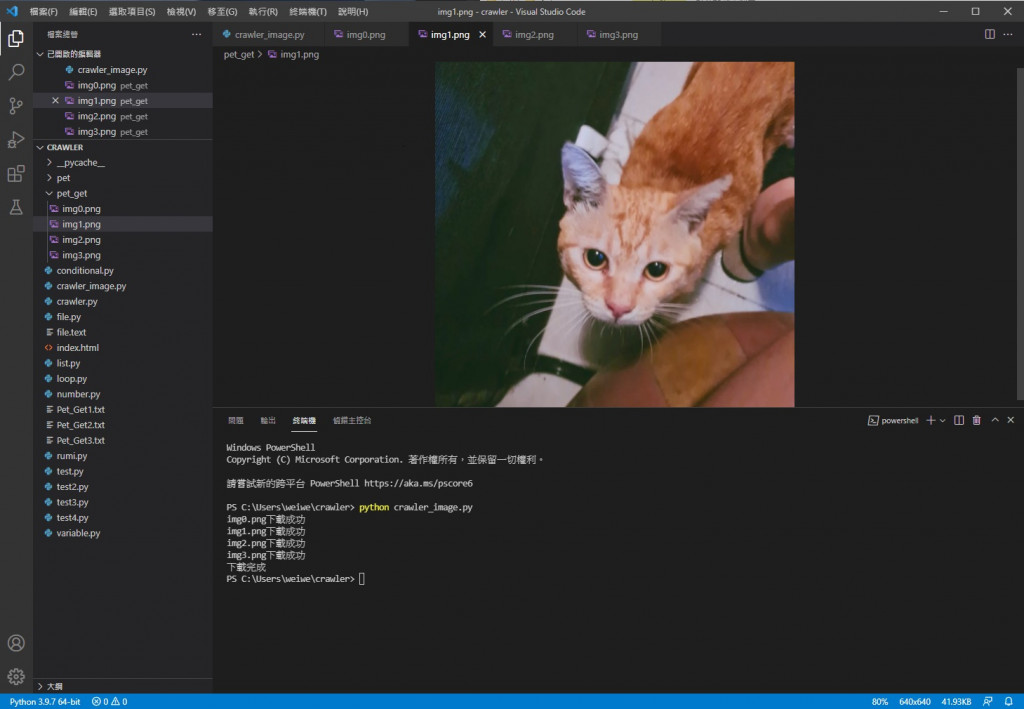
img2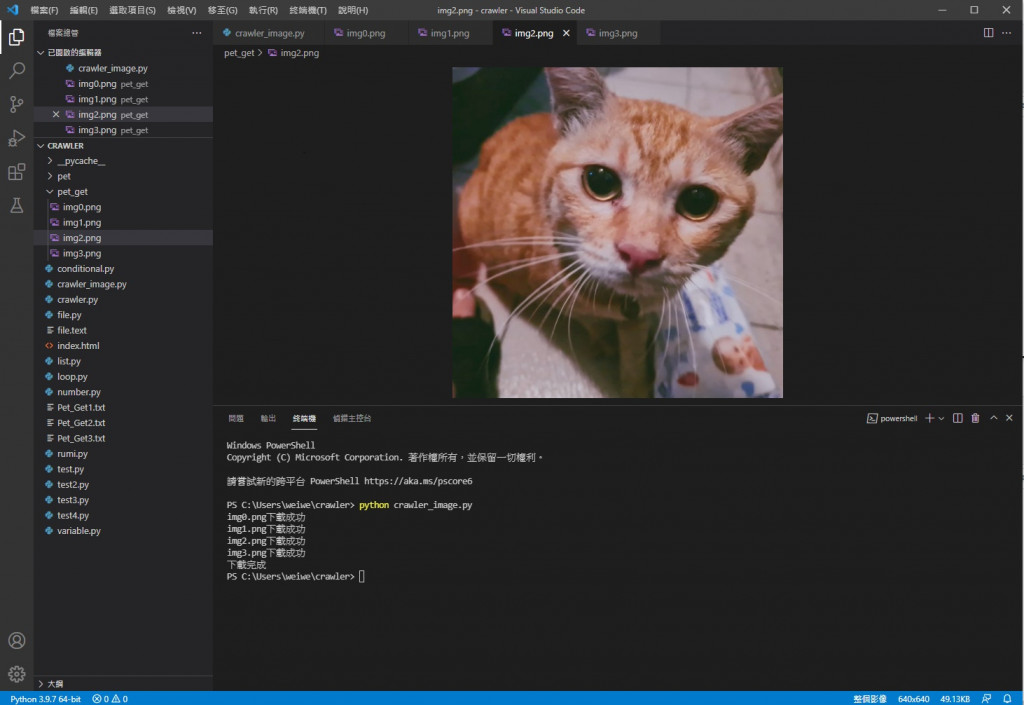
img3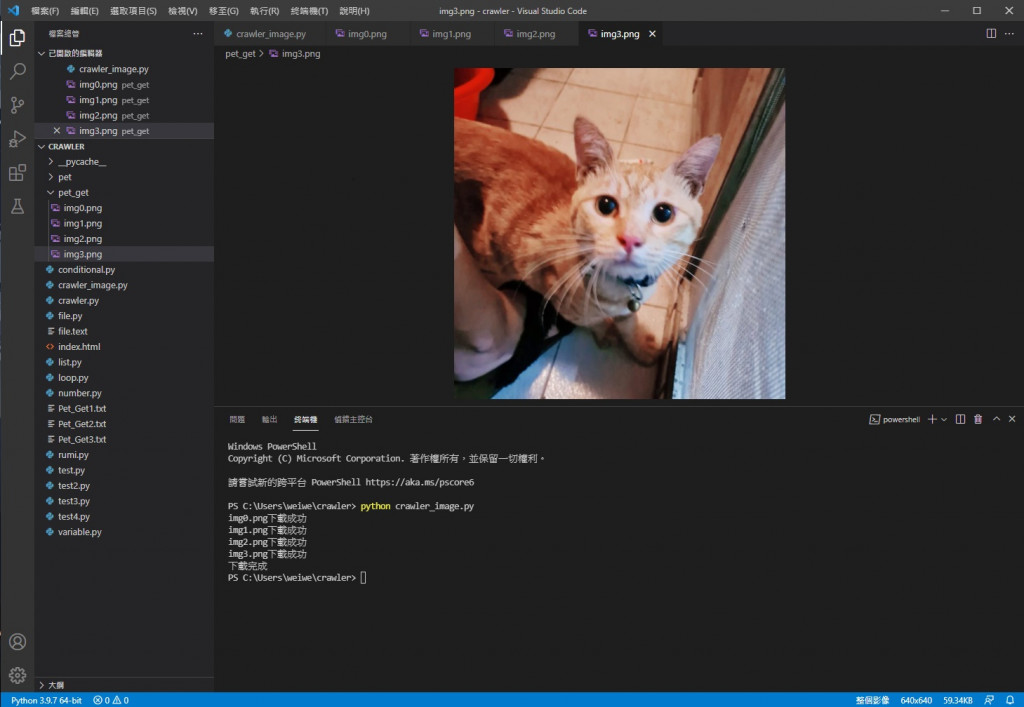
可以看到都儲存成功也能正常顯示
img0 會那樣是因為那張圖片已經被移除 存圖片的網站就發一個圖片已被移除的圖來告知
我們可以去網頁上看看
文章網址 https://www.ptt.cc/bbs/Pet_Get/M.1631051441.A.6C7.html
的確圖片就是這些 第一張圖也沒東西
爬圖成功
今天我們成功利用網頁連結抓取網頁上的圖片了
明天是鐵人賽最後一天 要來分享一下這次鐵人賽的心得
參考資料:
http://jasonyychiu.blogspot.com/2019/10/python-syntaxerror-unicode-error.html
https://www.itread01.com/content/1549998217.html
https://www.itread01.com/content/1525927207.html
https://ithelp.ithome.com.tw/articles/10185694
https://www.cnblogs.com/zhaijiahui/p/8391701.html
https://blog.csdn.net/icydust/article/details/53113906
https://www.itread01.com/content/1548776360.html
非洲有個國王竟然為了建設自己的國家在別國打工賺錢喔
如果有人對你態度不好你會保持風度還是以同樣態度應對呢

