上篇回顧
分布式可觀測性 Logging 淺談
分布式可觀測性 Structured Log
分布式可觀測性 Metrics 淺談
繼續淺談Observability的最後一個基石
單體架構下, 基本上調用關係僅在同一個process的記憶體內做調用, 通常都是透過stack trace做調用鍊路的trace.
將這些資訊給匯出後, 再通過類似Flame Graph的工具, 進行可觀測性的分析. 也可透過圖, 來得知調用關係.
但是在Distributed System下常常, 服務之間相互調用, 其調用的機器與網路甚至不是同一個.
一樣也是要透過調用鍊路收集的工具, 把Distributed System的調用鍊路整成一個跟stack trace很像的結構與資訊. 其中也包含每個調用鍊路的耗時時長.
這就是Distributed Tracing, 能參考去年我的文章Distributed Tracing & OpenTelemetry介紹
前面兩個維度講的資料, 都是以Time Series Data的方式呈現.
Time Series Data反應的是Metric指標在某一個時間點上的狀態.
這種資料與MySQL這類的OLTP資料有所不同.
Time Series Data會有一些獨特的概念
所以 Metric+Label決定了一個計量的單位.
如果以MySQL來存放, 那一個Metric就會是一張表了, Label則是裡面的欄位, 可能還會有其他欄位像是Timestamp.
再來MySQL這類的資料庫, 通常以B+Tree做資料存儲結構, 通常會以讀取的順序依序做排序,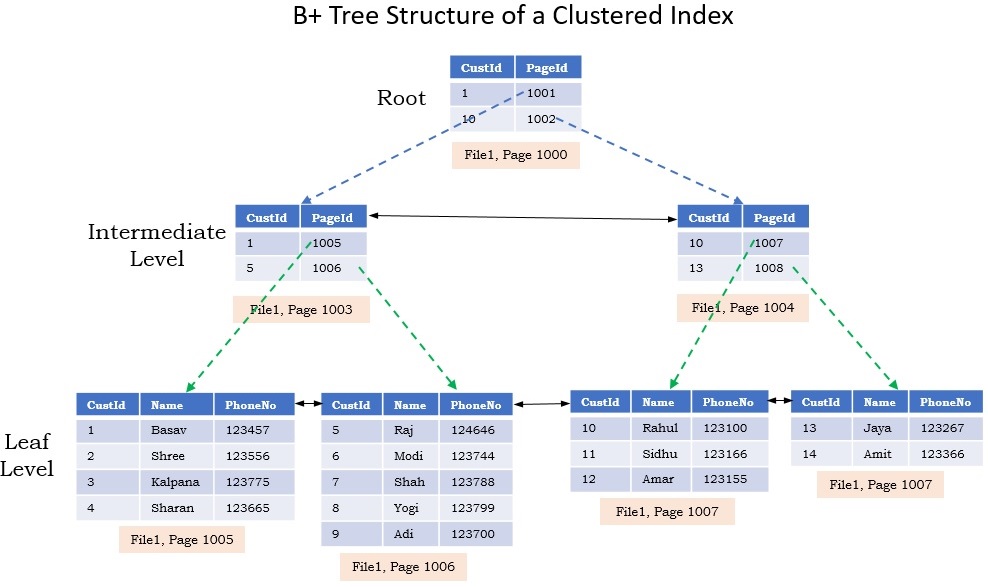
因為B+Tree預設是為了對磁碟做存取操作的, 它所有資料都存在Leaf葉子節點中.
每次查詢時, 需要從Root節點查詢到Leaf節點, 在從Leaf節點對應的位子進行讀取, 其存放的順序剛好跟讀取所需要的順序是一致的. 然後Leaf節點的資料是放在磁碟內的Page, 讀取一整個page出來後放到Memory中.
但沒人說物理Page剛好位子都是相鄰的.
這樣的結構好處是插入刪除的時間複雜度是O(log2N), 查詢要看情況, 可以非常好也能很不好.
這種隨機讀寫的場景蠻常見的, 會導致時間大多花在磁盤尋址上.
大家應該組機很常去跑CrystalDisskMark這工具, 來看磁碟的隨機讀寫與順序讀寫的速度快慢.
可以發現順序讀寫的效率跟俗機讀寫的效率不是一個量級的
哪怕你是SSD
但Time Series Data的另一個特徵是海量的資料量, 這些資料量在寫入是挑戰,
如果幾十萬筆, Log2N才多少, 但若是1億筆就可怕了
所以有下面結構的資料庫
所以有令一種資料庫很適合存放Time Series Data, 它叫LSM-Tree (Log Structured Merge Tree)
核心思想是 將離散的隨機寫入請求都轉成批量的順序寫入請求
透過在記憶體整理後, 只要確保在記憶體時, 資料是按照順序排列的,
當記憶體的資料累積到一個量時, 會做一些歸併整理, 在直接寫到硬碟中.
這樣子就不用一直的寫入了, 畢竟寫到記憶體是非常高效率的.
為了避免資料在資料庫當機後遺失, 也是會採取WAL(Write Ahead Log)的機制.
雖然它沒解決掉查找還是隨機位置的問題,
但記得 監控在意的是過去短時間內的聚合資料而已. 近期的資料會在記憶體中, 查詢依然非常高效率.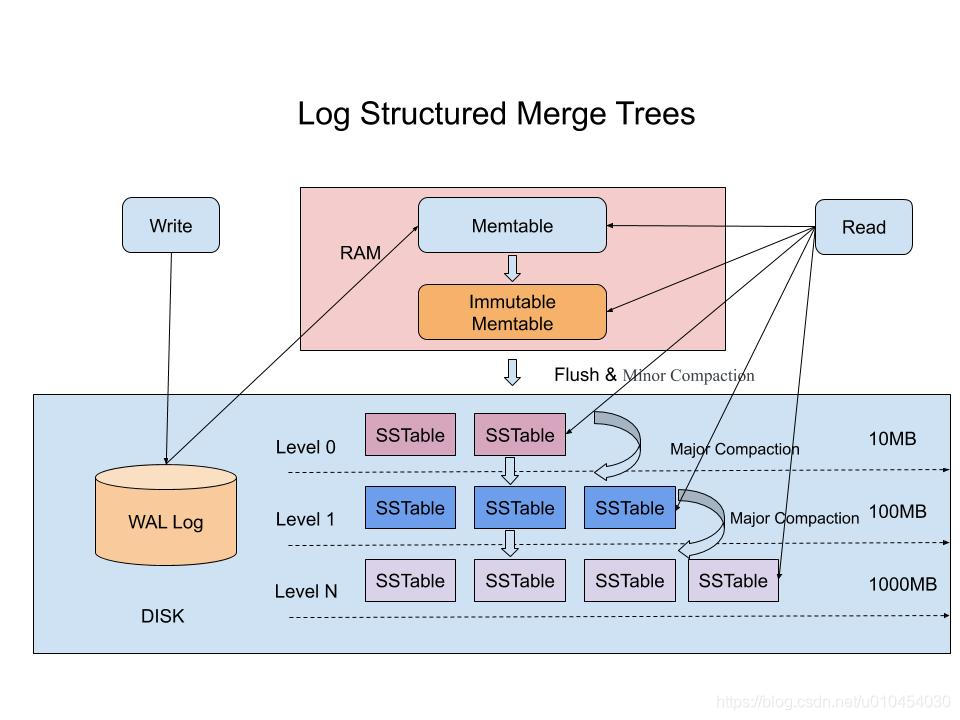
這類的介紹, 明年看有否機會深入.


 iThome鐵人賽
iThome鐵人賽