上一篇我們已將伊甸基金會的口罩臉孔資料集上傳到 nilvana 的 Vision Studio 中, 在真正執行標註之前, 我們先來認識一下標註格式與常用的標註工具.
在圖檔之上想要做標註, 做法是針對每一個圖檔產生一個metadata, 這個metadata用來說明該圖檔的標註內容, 格式通常為XML或JSON. 因此做完標註之後會有兩個檔案
常見的標註格式如下:
以下說明COCO的標註操作方式(ps:Nilvana也支援COCO), 讓我們了解一下標註在做些什麼
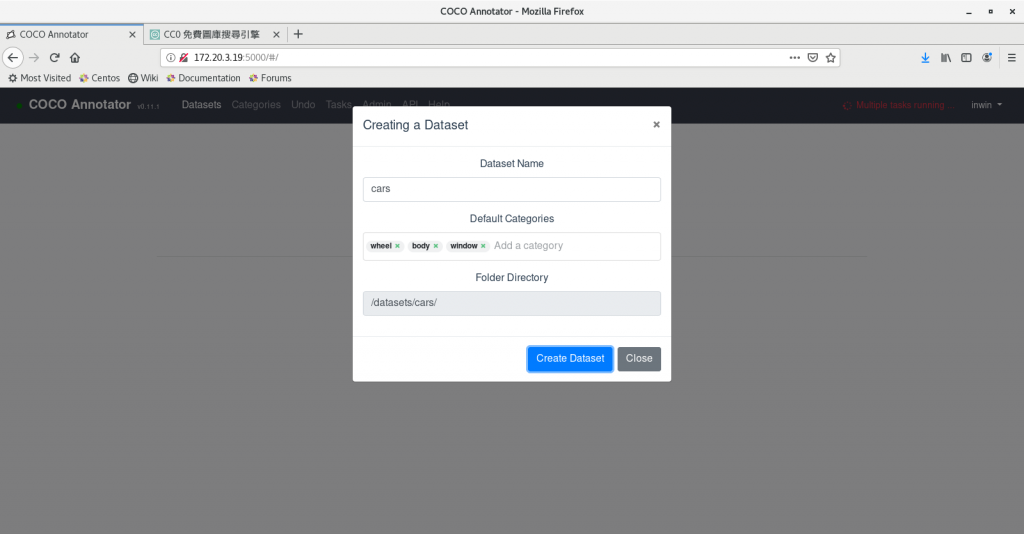
首先我們使用CoCo annotator建立一個dataset, dataset的名稱是cars, 而且我們建立三個label, 分別是wheel、body與window.
然後在這個dataset之中加入一張圖片, 我們要在這張圖片加張一個標註框, 來看看標註檔會如何記錄我們加入的標註框資訊
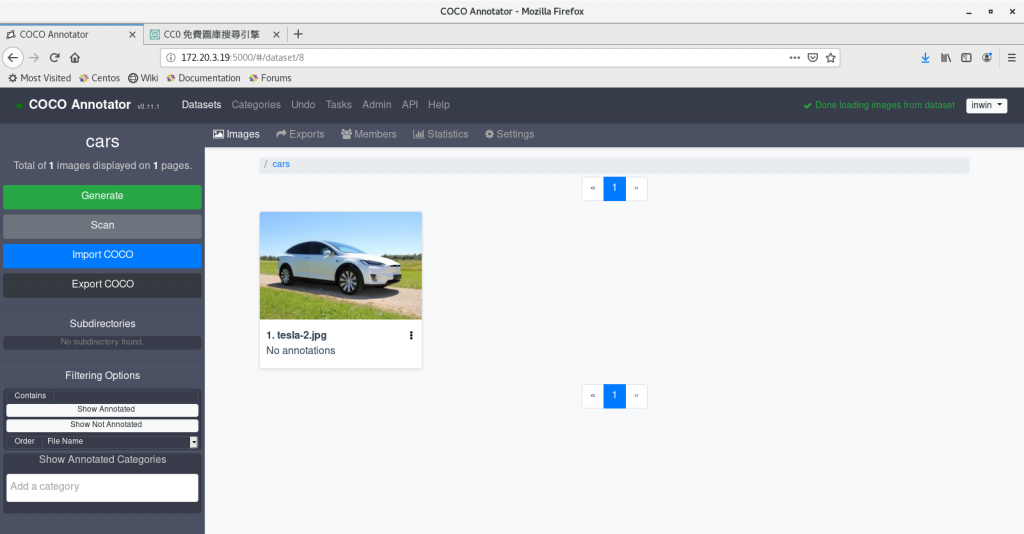
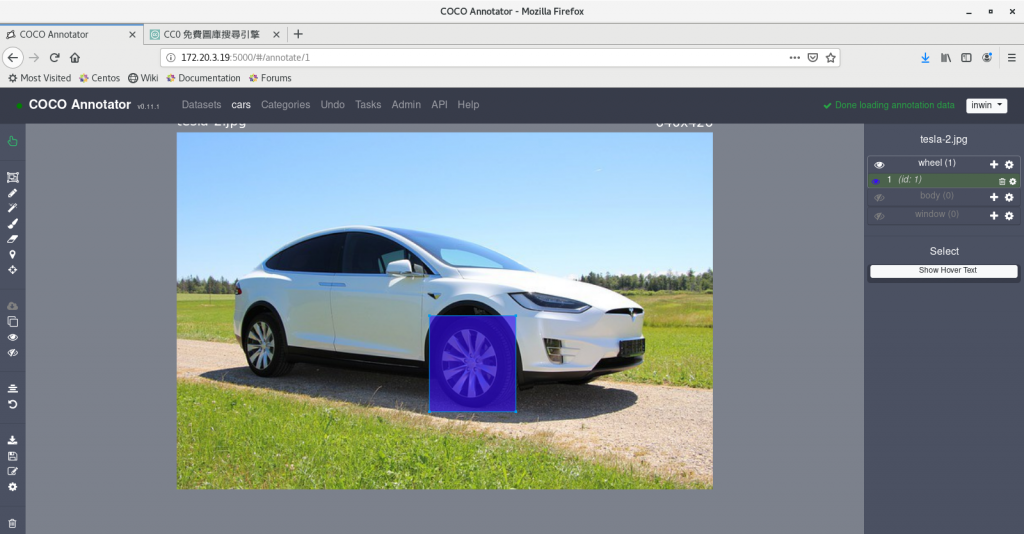
我們在這張圖上加上一個BBox(bounding box).
標註好之後, 將資料匯出, 我們要下載標註資料
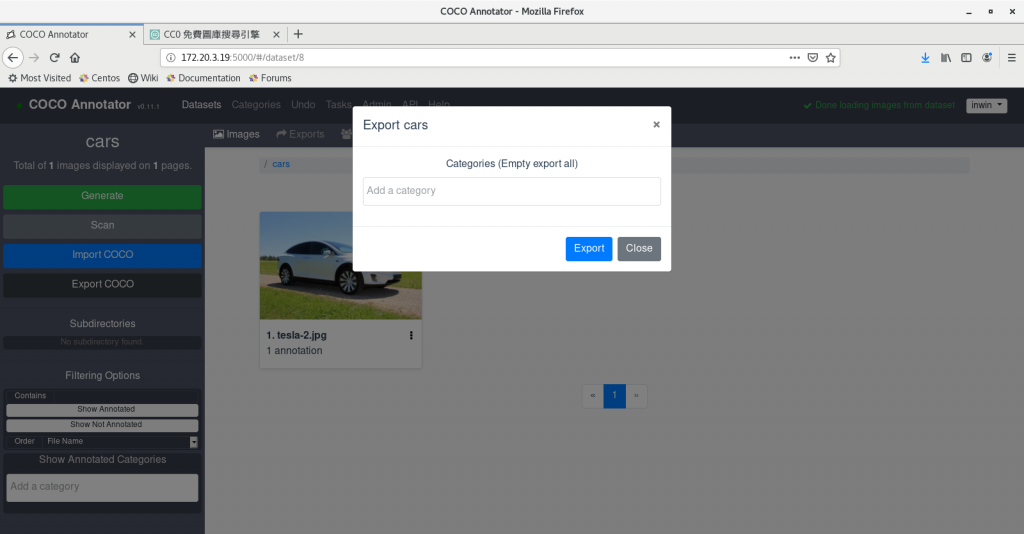
下圖點擊Donwload即可下載標註資料
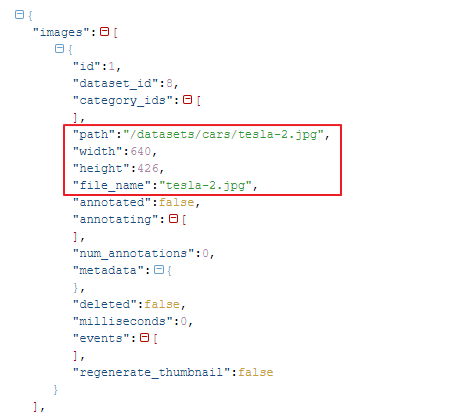
下載下來的標註資料是JSON格式, 分為三段說明(這個JSON可以在github下載)
圖檔資訊(images)
圖檔資訊用來描述圖檔本身的內容, 例如
標籤資訊(categories)
標籤資訊顯示的是我們在建立dataset時所設定的label(wheel, body, window), 而且也包含不同label會呈現的顏色.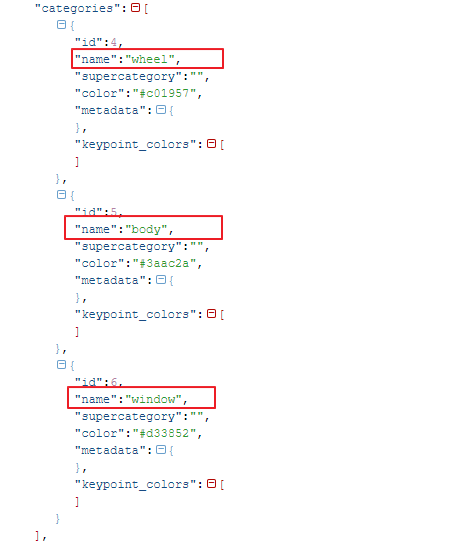
標註資訊(annotations)
標註資訊呈現我們所拉的標註框資訊, 在前面我們只拉了一個BBox(bounding box), 所以在標註資訊中也呈現一個bbox, 這個bbox由四個點所組成.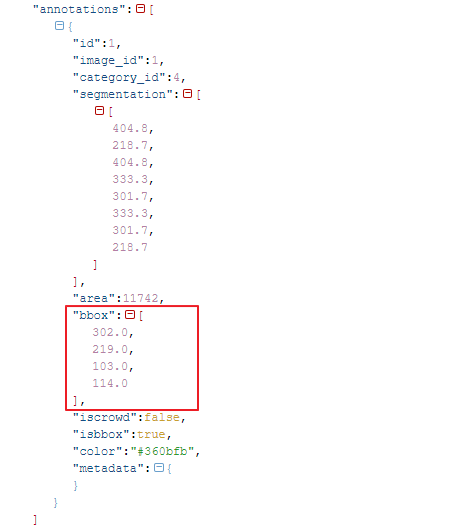
在範例中, 以一張圖檔加上標註框產生一個標註檔(JSON), 這是最基本的組成, 希望能協助大家了解標註檔的內容與功能.
https://github.com/jsbroks/coco-annotator
https://www.robots.ox.ac.uk/~vgg/software/via/
http://host.robots.ox.ac.uk/pascal/VOC/
http://dlib.net/
https://cocodataset.org/#format-data

