上一篇我們已經為資料集做好資料前處理、資料擴增與資料集版本建立, 接下來我們要開始執行training.
請在eden_mask資料集中點選Versions頁籤, 然後點擊3.0.0版號的training圖示, 如下圖紅框所示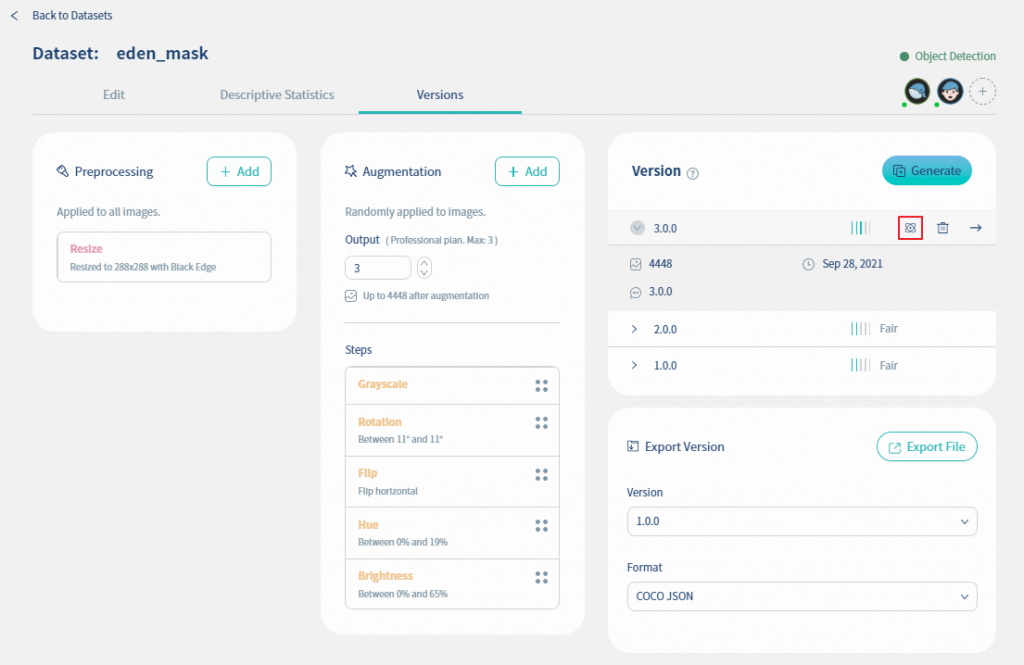
這時只要輸入Model Name就好, 而Select file欄位會自動帶入.
需要說明一下的是訓練的方法與資料切分的比例這二個欄位, 因為兩個選項會影響訓練的品質.
訓練方法我們選擇Faster detction & Small size, 就先以小尺寸進行說明 .而資料切分保留原本的設定, 也就是8:2.
接著點擊Create鍵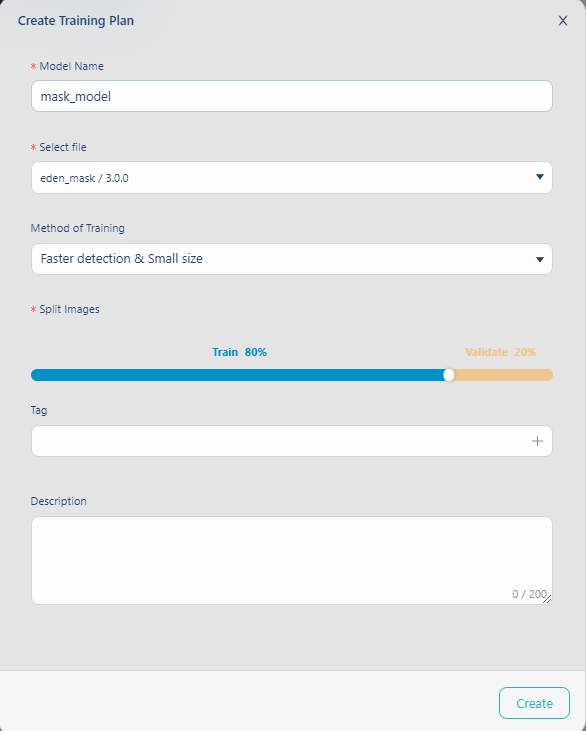
Nilvana根據資料集版本的統計量,預先為你設定了理想的最大訓練迭代次數,不需要調整太多的參數就可以完成訓練設定。然而,若你發現訓練過程中的曲線已經收斂到理想情況,你可以隨時中斷訓練工作,不用等到所有迭代都執行完畢。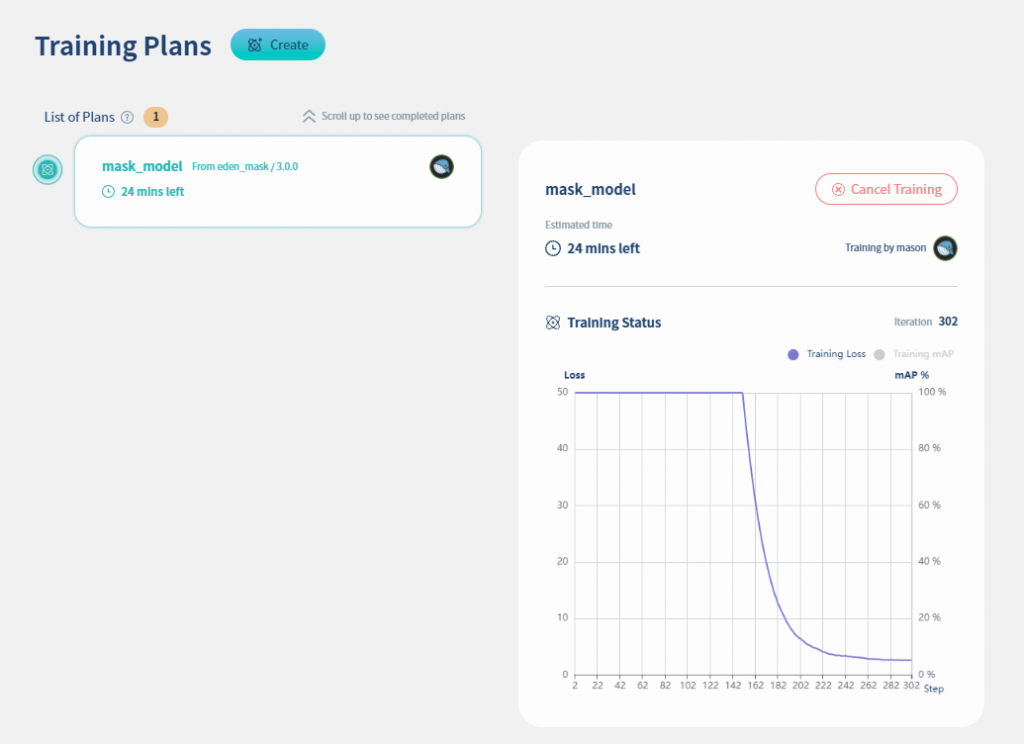
當完成訓練之後, 可以在第三個功能(Models)中看到已產生的model, 如下圖.
我們再點mask_model進去看看.
下圖顯示的是訓練出來的model內容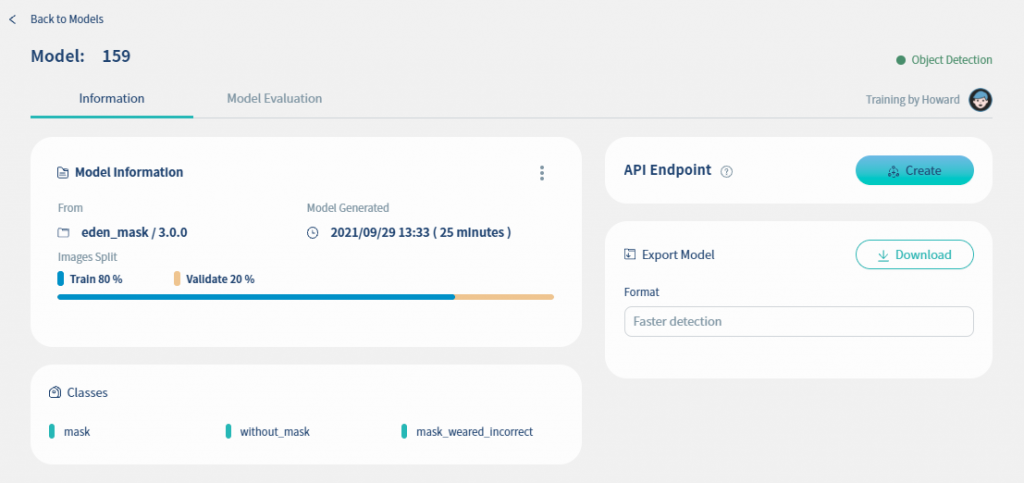
我們先來評估/測試一下我們訓練出來的模型準不準, 請點擊下圖的Model Evaluation頁籤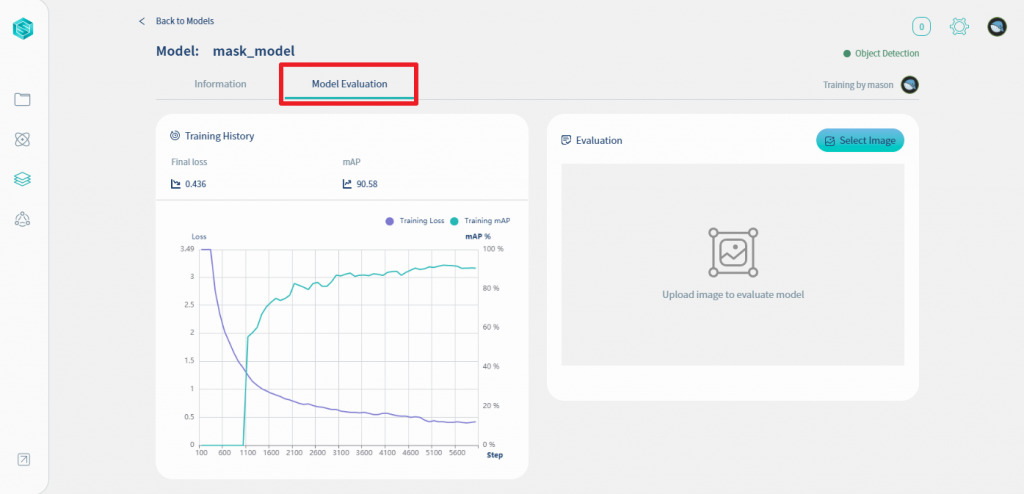
在Model Evaluation頁籤後, 左側顯示訓練的記錄, 右側你可以上傳一張圖片試試看訓練出來的model準不準. 現在就讓我們來試試這個功能, 請點擊Select Image鍵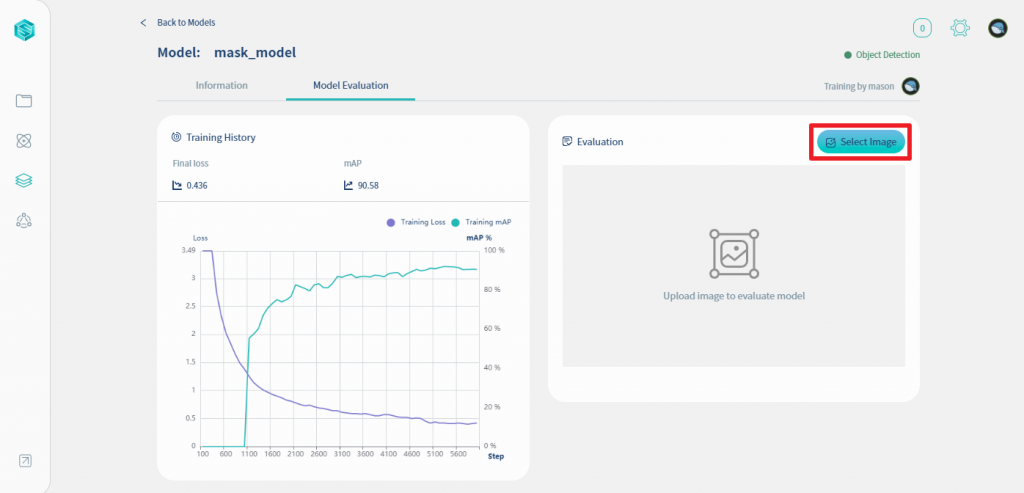
上傳一張圖片後,就可以確認辨識結果,如下圖中系統辨識有戴口罩的機率是97.8%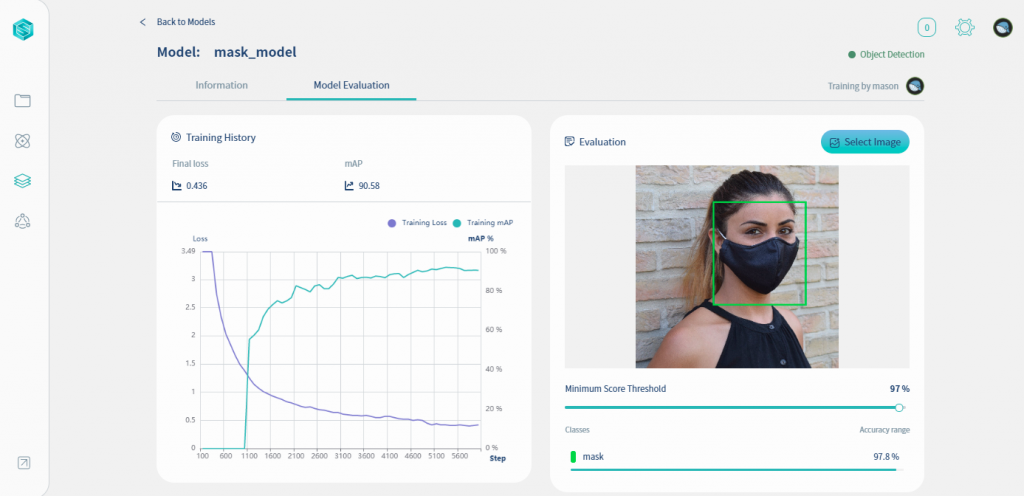
監督式學習的模型品質跟高品質的資料集有很大的關係,如果你覺得效果不盡理想,可以先試著增加有意義的訓練資料,再實驗使用不同的訓練方法與切分比例。
到此我們已經使用 Nilvana 的 Vision Studio 完成口罩辨識模型的訓練流程,選定資料集版本後,在 UI 上就能選擇訓練方式及圖片切分比例,對於模型訓練的任務來說更加輕鬆上手

