我們已將資料集上傳到 nilvana 的 Vision Studio 中, 也知道標註格式的種類與基本內容, 這篇我們來執行標註、資料前處理與資料擴增.
標註方式可分為機器標註與人工標註,Vision Studio 的機器標註提供半自動標註及全自動標註兩種
接下來回到Nilvana的Dataset頁面, 請點擊下圖的Machine Annotation按鍵
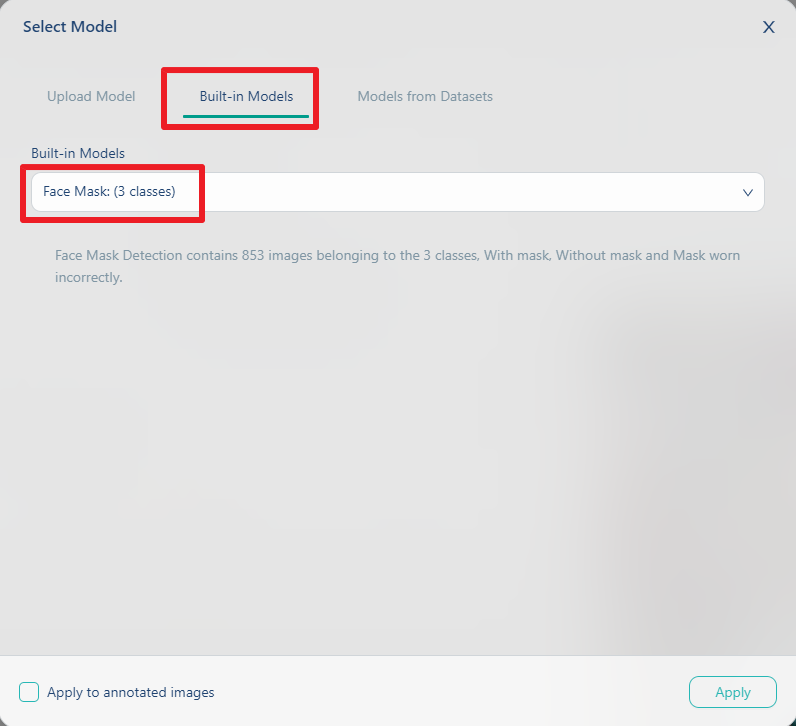
在下圖中, 我們擇選中間的tabBuilt-in Models, 表示我們要使用內建模型. 內建模型大部份是基於開放資料集,並經過驗證與調教訓練而成,包含:
有戴口罩、沒戴口罩及口罩穿戴不正確三種類別。在這個步驟中, 我們選擇Face Mask(口罩偵測模型), 再點擊apply鍵
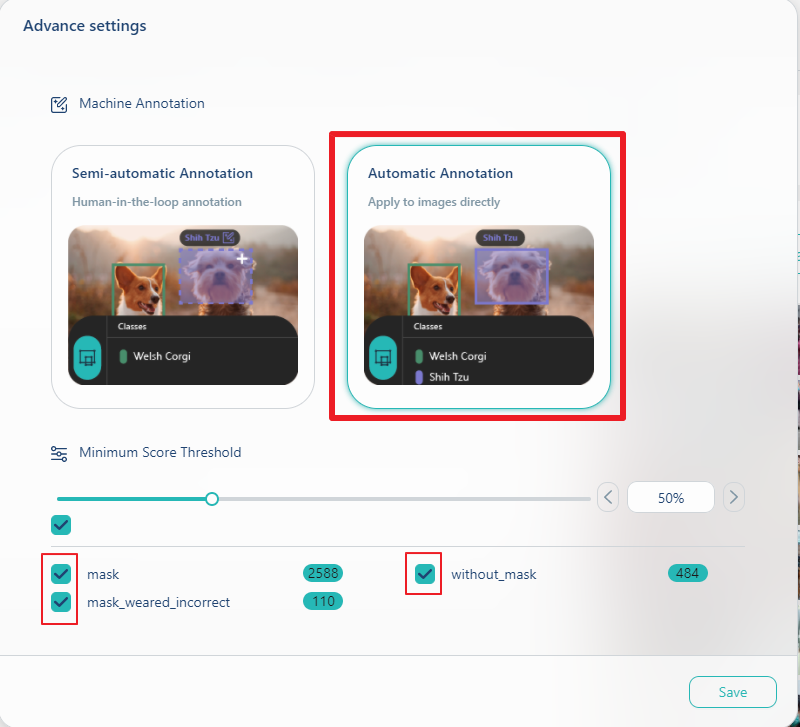
接著要選擇執行全自動標註還是半自動標註, 這裡我們選全自動標註Automatic Annotation
針對Minimum Score Threshlod, 可以左右拉動最小機率門檻值做設定, 數值越大則誤判機會越小, 但可能會漏掉一些物件.
然後進行確認要標註的標籤, 在我們的範例中, 被標註為有戴好口罩的數量有2588, 沒有正確戴口罩的數量有110, 而沒有戴口罩的數量有484, 我們把這三個checkbox都勾起來.
然後也再點擊save鍵
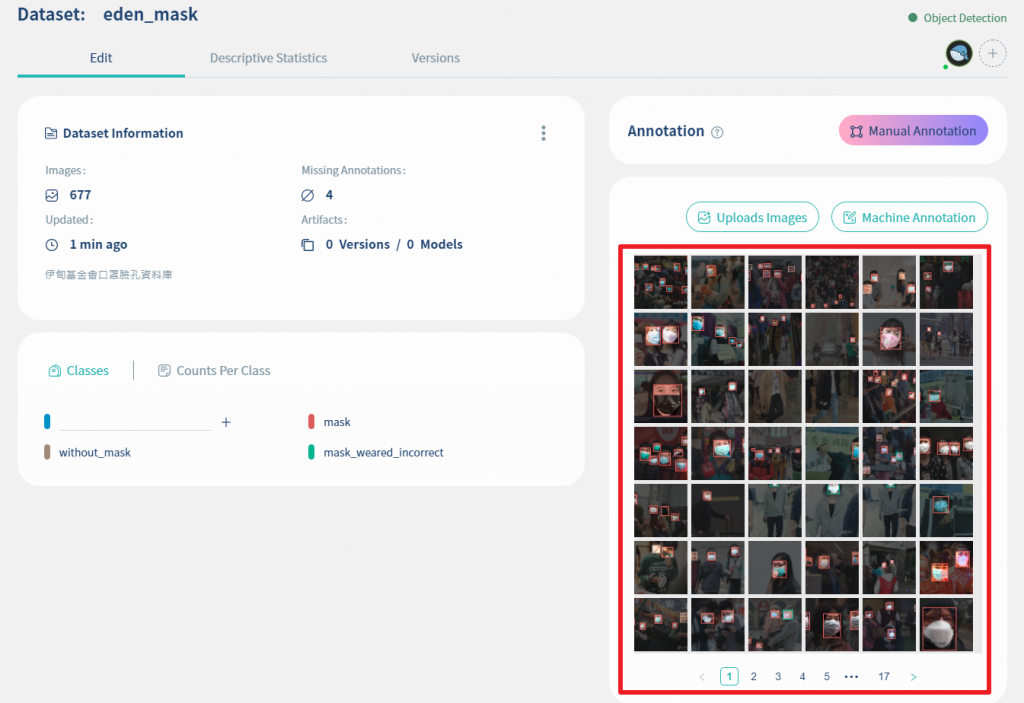
然後即可看到自動標註後的結果, 如下圖紅框處
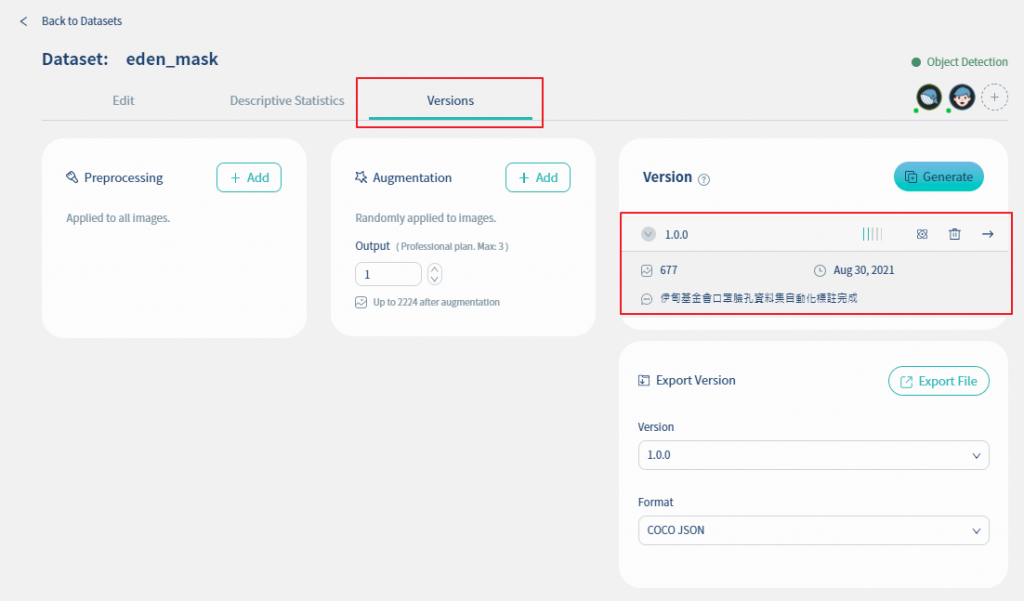
完成資枓標註之後, 以目前的圖檔建立一個新的版本, 版本名稱為1.0.0, 圖檔數量為677張, 如下圖所示. 但目前的圖檔版本品質為二格, 品質屬於尚可(fair), 因此接下來我們來(1)加入更多圖檔, (2)使用資料前處理與資料擴增技術增加資料集的品質
為了增加圖檔品質, 其中一種方式是增加圖檔, 上傳圖檔的方式請參考Day24的內容.
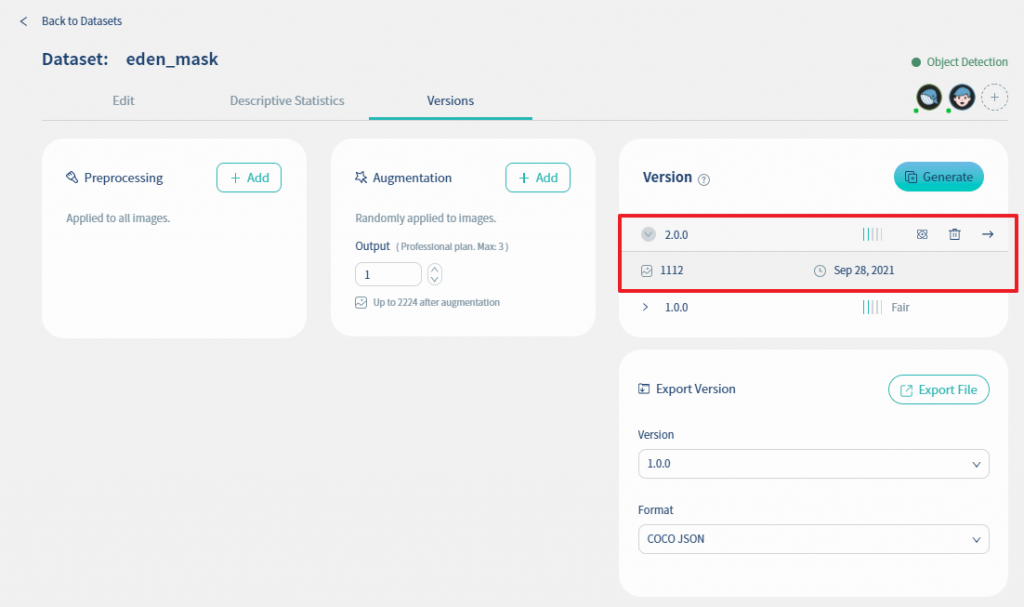
增加圖檔後, 圖檔的數量增加為1112張, 並且將版本命名為2.0.0, 如下圖所示.
但增加了圖檔數量之後並沒有增加圖檔品質, 圖檔品質仍屬於尚可(fair).
前述增加圖檔數量之後並沒有增加圖檔品質, 因此接下來要執行資料前處理與資料擴增, 預期資料品質會提高.
資料前處理與資料擴增是OpenCV的專長
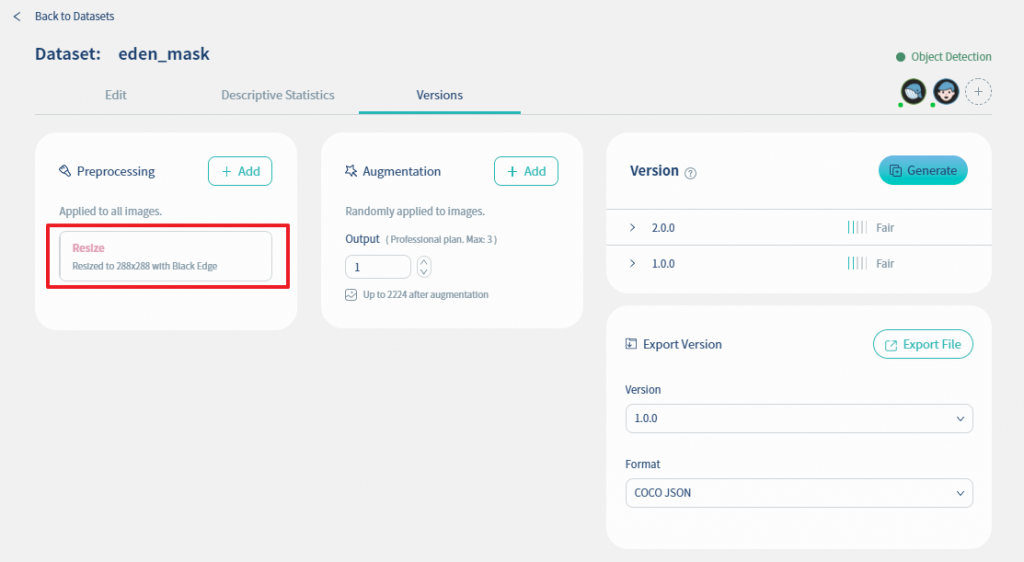
接下來我們使用Nilvana來做resize. 首先在下圖中選擇Versions頁籤, 然後點擊Preprocessing的Add鍵
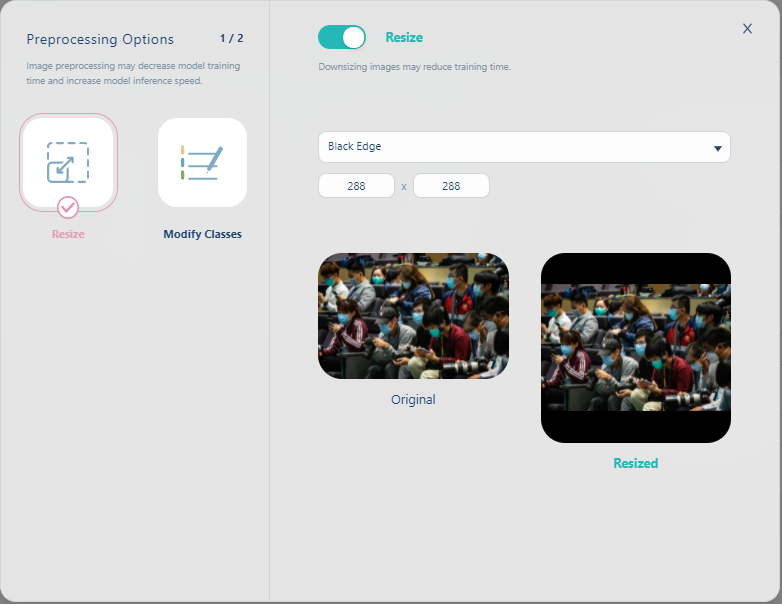
然後在下圖選擇Resize, 並且在右側的下拉式選單選擇Black Edge, 表示我們要影像檔固定為同一個size(288x288), 如果有多出來的部份以黑底填滿. 最後再將Resize切換為enabled.
這裡將資料的尺寸及類別格式統一的好處是可以幫助你減少模型訓練所要花費的時間.
設定好的畫面如下圖所示:
接下來我們要做資料擴增, 請點擊下圖的Add鍵
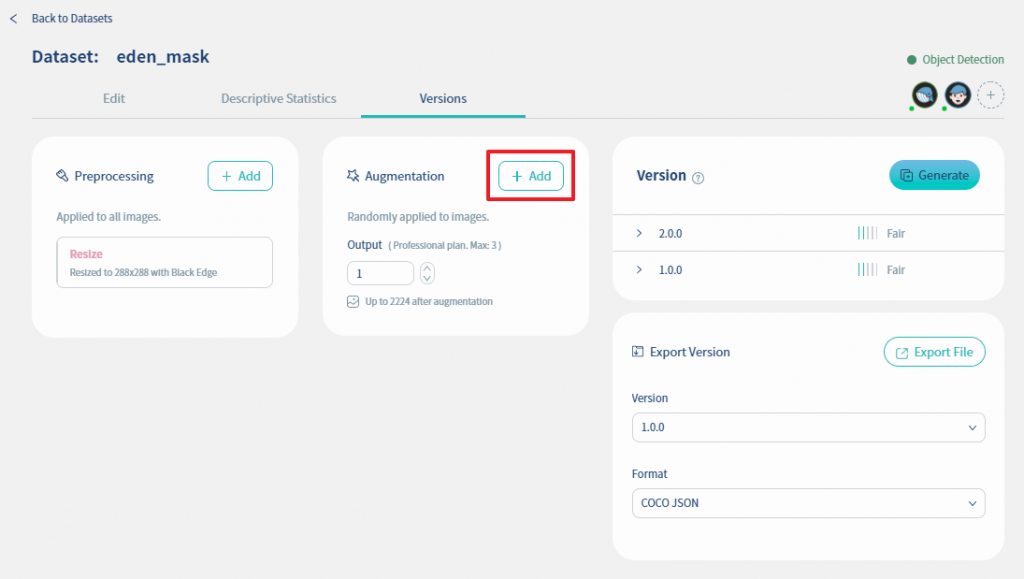
Nilvana提供多種方式, 透過小幅度的改動資料, 可以為你優質的資料增加多樣性以及降低過度擬合的現象, 提高資料集整體品質. Nilvana提供以下演算法輔助你增強圖像,包含:Noise, Saturation, Brightness, Hue, Flip, Exposure, Shear, Rotation, Blur, Grayscale 等。
在我們的範例中, 選擇左右翻轉(Flip)
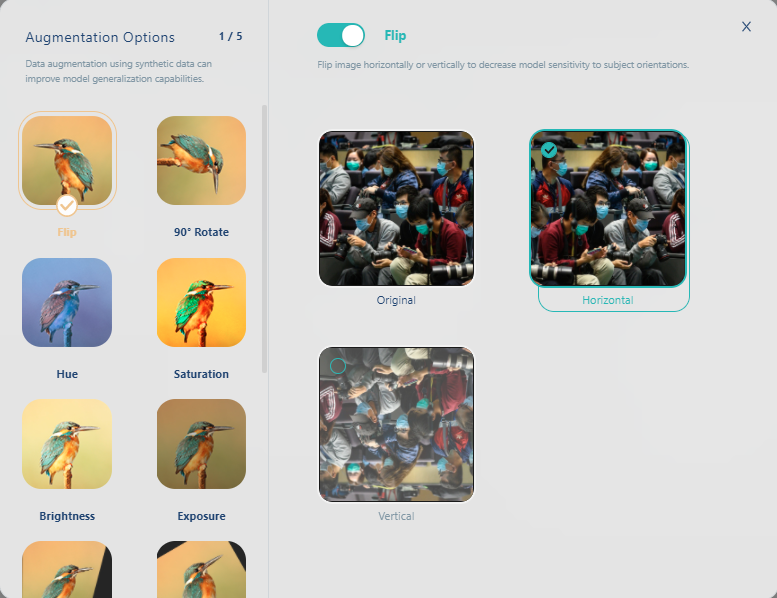
再選灰階(Grayscale)
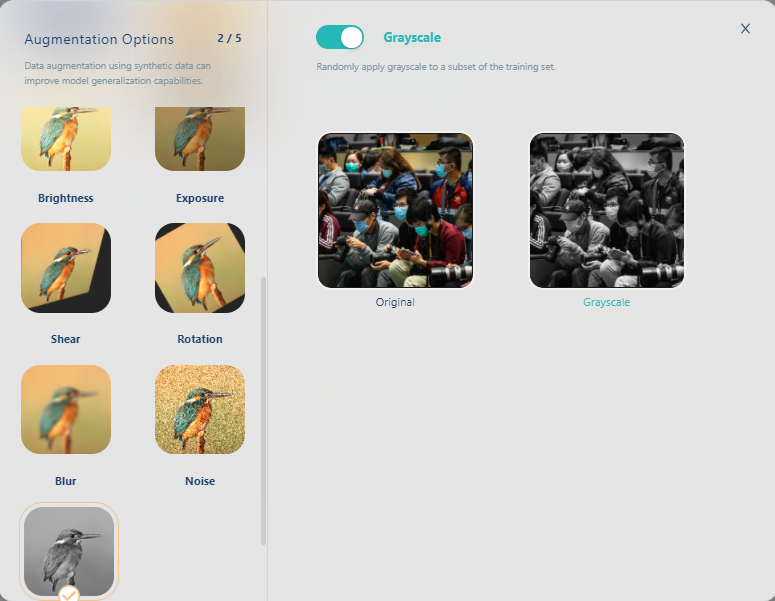
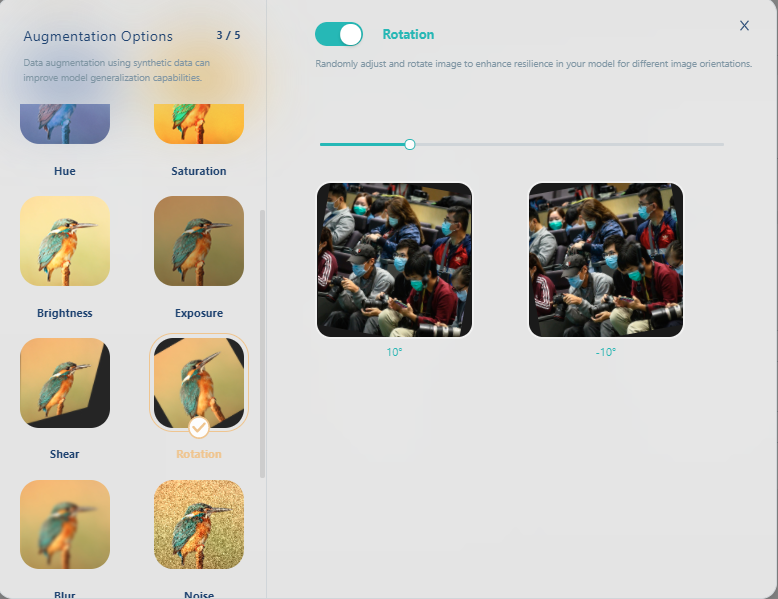
再選旋轉(Rotation)
再改變色調(Hue)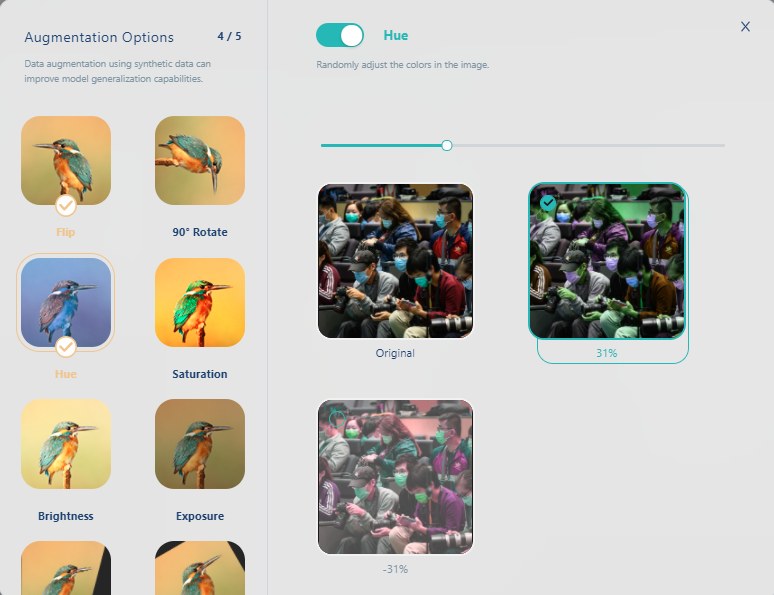
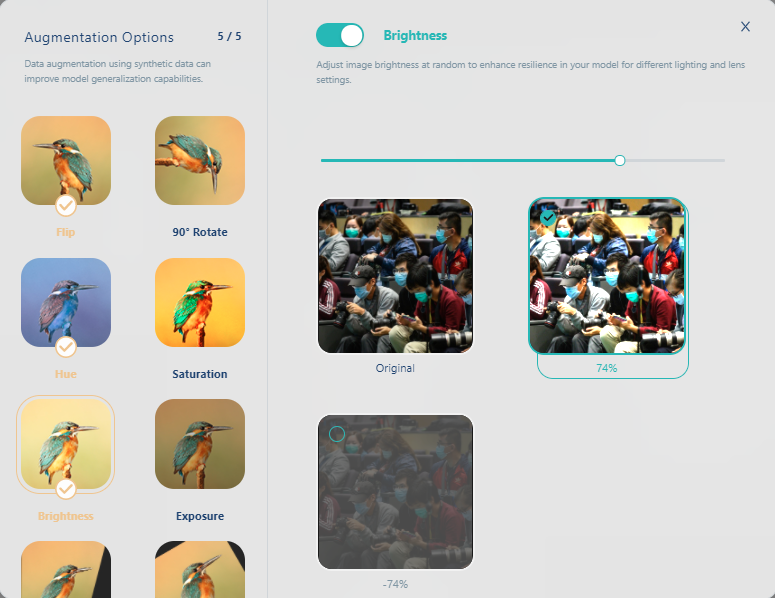
再選變亮(brightness)
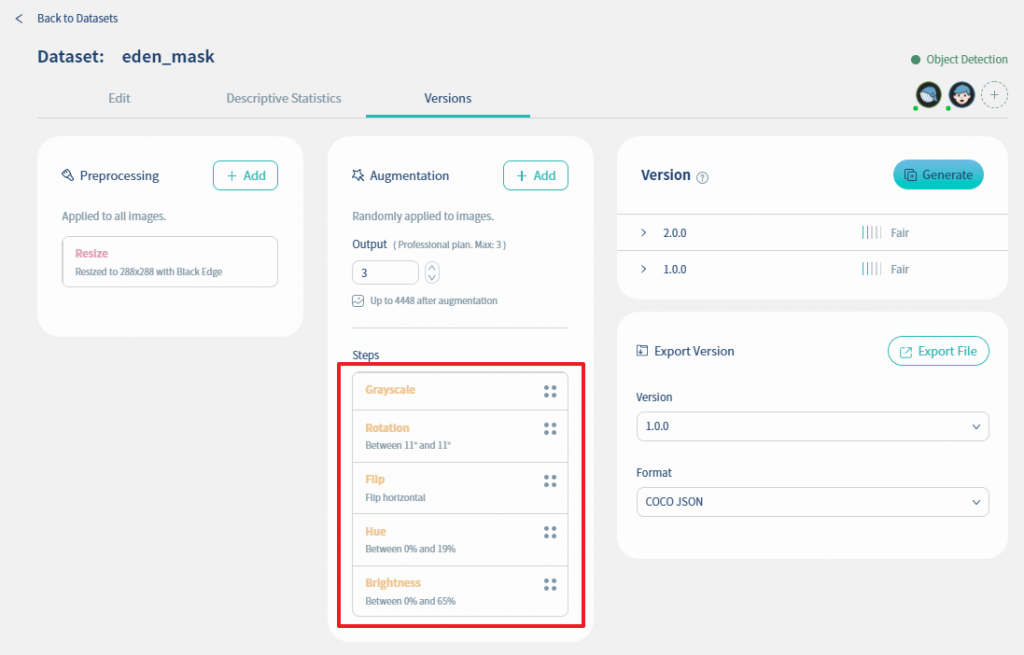
這時就可以看到我們把五種資料擴增機制加進來了. 同時再把output數設定為3. 這時可以看到資料集的圖片張數增加到4448張
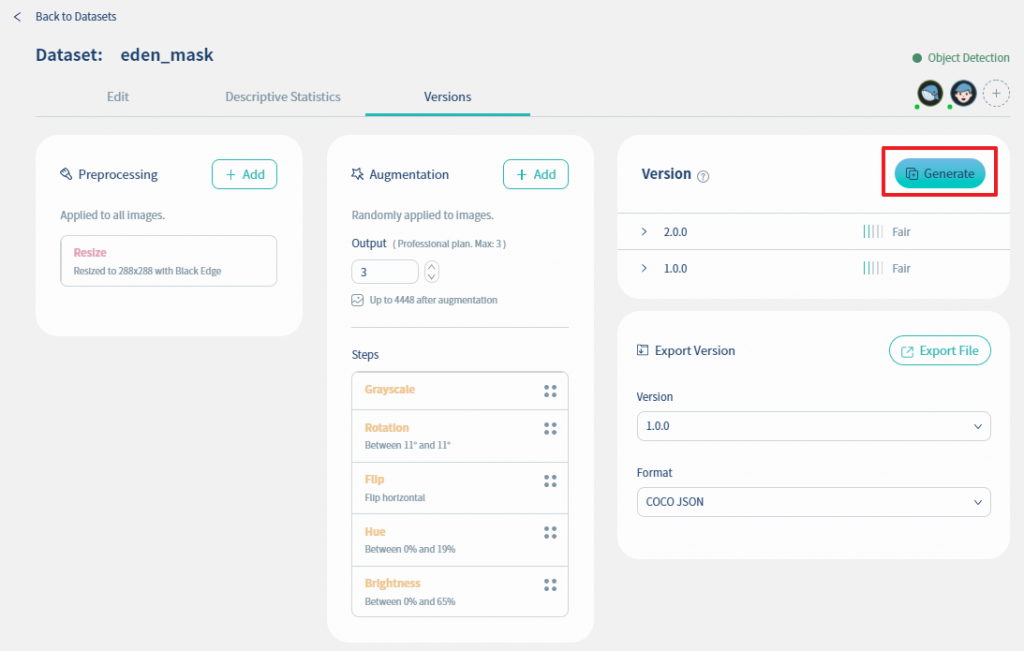
當完成資料前處理與資料擴增之後, 就要把這組資料集給定一個版本, 這樣之容易界定不同的資料集的差別, 也易於之後執行訓練時選擇不同版本名稱就可以選到不同的資料集.
請點下圖的Generate鍵
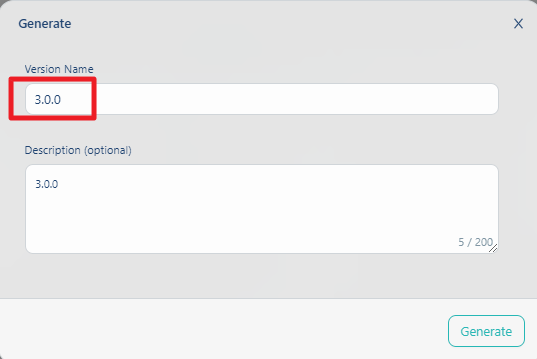
輸入版本編號
完成了之後, 可以看到Dataset版本已建立, 如下圖. 在這個版本, 影像張數為4448張, 而且資料品質增加為三格(Good),可見資料擴增功能已有效增加dataset張數與品質.
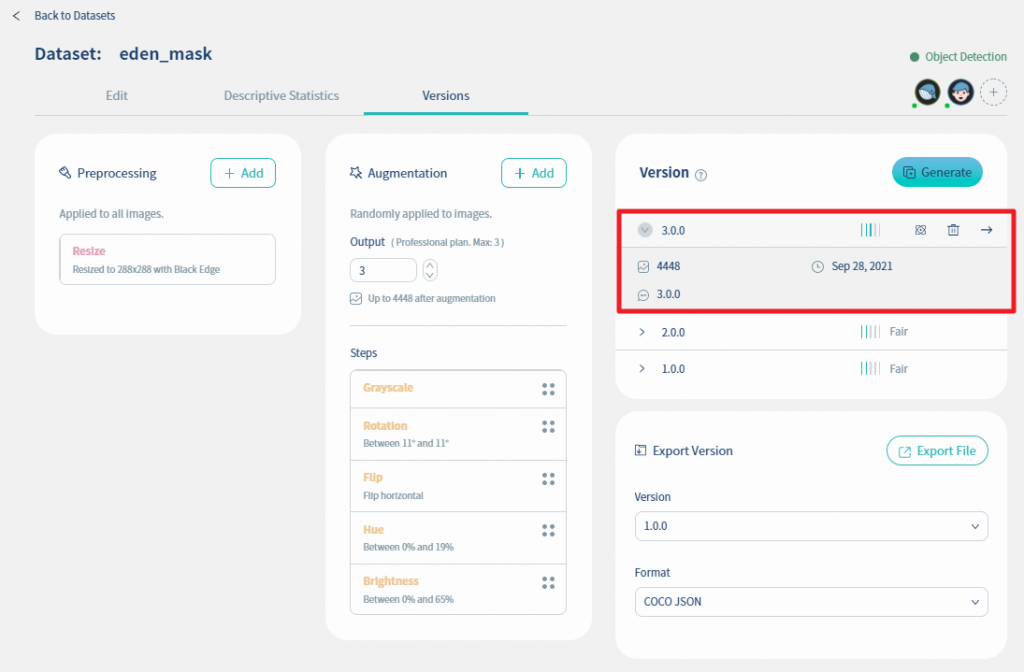
到這裡我們使用使用機器標註中的全自動標註功能完成了口罩臉孔資料集的標註, 也完成資料前處理、資料擴增與版本建立, 下一篇我們就來執行訓練

