前一篇我們介紹了 Slate Normalizing 裡負責實作節點正規化以及讓使用者自定義 constraints 的主要函式: create-editor 編輯器的 normalizeNode action 。還沒閱讀過的讀者 傳送門 在此~
今天我們緊接著要介紹 Normalizing 章節的另一個主要函式:interfaces/editor.ts 的 normalize method 。以及輔助函式: withoutNormalizing 、 isNormalizing 。
它們除了負責呼叫 normalizeNode 執行節點的正規化之外,還有處理整個 Normalizing 功能的效能優化以及實作我們在 Day24 裡提到過的特性。
如果説 normalizeNode 是肉眼可見的表皮的話,那麼今天要介紹的 normalize method 以及它的小夥伴們就是支撐著整個 Normalizing 系統能夠順利運作的骨幹啊!
那麼事不宜遲,讓我們直接深入它的 code 一探究竟
normalize Method Content我們可以把整個 method 拆成兩個部分:
withoutNormalizing 實作的主要段落( Main-Process )Preprocess 的部分除了幾個判斷式負責輔助主要段落之外,還有一些額外的功能:
取得 Dirty-Path value
這部分很基本,就是另外宣告一個 getDirtyPaths function 提供給後續的功能取得 DIRTY_PATHS 的 value 而已:
normalize(
editor: Editor,
options: {
force?: boolean
} = {}
): void {
const getDirtyPaths = (editor: Editor) => {
return DIRTY_PATHS.get(editor) || []
}
// ...
}
處理 forth option
forth 參數代表的含意就是忽略計算出來的 Dirty-Path 結果,強行正規化編輯器內的所有節點。
這裡的做法也很簡單:透過 Node.nodes method 取出編輯器當前存在的全部節點,並設定進 DIRTY_PATHS 裡:
normalize(
editor: Editor,
options: {
force?: boolean
} = {}
): void {
// ...
if (force) {
const allPaths = Array.from(Node.nodes(editor), ([, p]) => p)
DIRTY_PATHS.set(editor, allPaths)
}
// ...
}
接著就輪到了主要段落的部分了,我們會依序介紹下方它所實現的功能們:
還記得在 前一篇 文章中提到過, Slate 正規化的運作方式是『一組完整的 FLUSHING 搭配一次 Normalize 』, withoutNormalize 就是實現這項功能最核心的 method ,所有會需要 Normalizing 功能的 Transform methods 裡都一定會包進這個 method 裡來實作,隨便舉個 insertNodes 當作範例:
insertNodes<T extends Node>(
editor: Editor,
// ... args
): void {
Editor.withoutNormalizing(editor, () => {
// ... Implementation
})
},
先一起來看一下它的 code 長啥樣子:
/**
* Call a function, deferring normalization until after it completes.
*/
withoutNormalizing(editor: Editor, fn: () => void): void {
const value = Editor.isNormalizing(editor)
NORMALIZING.set(editor, false)
try {
fn()
} finally {
NORMALIZING.set(editor, value)
}
Editor.normalize(editor)
},
它首先儲存了 isNormalizing method 回傳的資料作為 NORMALIZING WeakMap 的初始值。
isNormalizing 其實單純就是回傳當前 editor 的 NORMALIZING value ,代表編輯器當前是否為『完成正規化』的狀態,只是多加了一層三元判斷:如果 value === undefined 則回傳 true (因為 undefined 為初始值,編輯器的初始狀態就是已經完成正規化的狀態了)。
/**
* Check if the editor is currently normalizing after each operation.
*/
isNormalizing(editor: Editor): boolean {
const isNormalizing = NORMALIZING.get(editor)
return isNormalizing === undefined ? true : isNormalizing
},
接著將 NORMALIZING value 設為 false ,等執行完傳入的 fn 以後再設 NORMALIZING 回先前存下來的初始值,並重新執行 normalize method 。
這麼做的用途是推延執行 normalize ,在 normalize 裡有一行 statement 會去呼叫 isNormalizing 回傳的 value ,如果回傳 false 就直接跳過這次的 normalize
normalize(
editor: Editor,
options: {
force?: boolean
} = {}
): void {
// ...
if (!Editor.isNormalizing(editor)) {
return
}
// ... Implementation
}
這使得一組 Transform 裡頭除了最初呼叫的那次包進 withoutNormalizing 的 fn method 會推遲執行 normalize method 之外,其餘在過程中呼叫的 normalize 都會因為 isNormalizing 回傳值為 false 因而直接跳過。
基本上整個 normalize method 是否結束完全取決於 DIRTY_PATHS 裡頭是否仍然有值,前面也有提到過 normalize method 的主要段落是搭配 withoutNormalizing ,放在傳入的 fn 參數裡去執行,所以就算完整地執行完 fn 的內容以後仍然會再執行一次 normalize method :
normalize(
editor: Editor,
options: {
force?: boolean
} = {}
): void {
// ...
// Main-Process
Editor.withoutNormalizing(editor, () => {
// ...
});
},
withoutNormalizing(editor: Editor, fn: () => void): void {
const value = Editor.isNormalizing(editor)
NORMALIZING.set(editor, false)
try {
fn()
} finally {
NORMALIZING.set(editor, value)
}
Editor.normalize(editor)
},
它會不斷地重複執行 normalize method ,直到從 getDirtyPath 取得的 length 為 0 時才真正結束。
所以我們不會在函式裡看到將 Dirty-Paths 設為空陣列之類的初始化動作,它只會不斷地重複執行 Normalizing 直到隨著每次新的 Operation 呼叫,透過 apply method 重新計算出要設定進 DIRTY_PATHS 的 value 為空陣列(詳請請回顧 上一篇 的內容)以後再透過預處理段落的輔助判斷式來跳出 method :
normalize(
editor: Editor,
options: {
force?: boolean
} = {}
): void {
// ...
if (getDirtyPaths(editor).length === 0) {
return
}
// Main-Process
Editor.withoutNormalizing(editor, () => {
// ...
});
},
在主要段落裡也是透過一組 while loop 重複 pop 出 Dirty-Path 的 value 來重複呼叫 normalizeNode 。當然作者還是有設一個門檻不讓整個正規化的次數無限上綱,也會先確定 pop 出來的路徑所指向的節點確實存在於 document 中再呼叫 normalizeNode :
// Main-Process
Editor.withoutNormalizing(editor, () => {
// ...
const max = getDirtyPaths(editor).length * 42 // HACK: better way?
let m = 0
while (getDirtyPaths(editor).length !== 0) {
if (m > max) {
throw new Error(`
Could not completely normalize the editor after ${max} iterations! This is usually due to incorrect normalization logic that leaves a node in an invalid state.
`)
}
const dirtyPath = getDirtyPaths(editor).pop()!
// If the node doesn't exist in the tree, it does not need to be normalized.
if (Node.has(editor, dirtyPath)) {
const entry = Editor.node(editor, dirtyPath)
editor.normalizeNode(entry)
}
m++
}
});
原來如此!再綜合上一小節的內容就能夠確保『正規化會被推延到最後才執行那麼一次』了!
但我想問個問題:如果在呼叫normalizeNode執行正規化的過程中為了更新 document 而又另外呼叫了 Transform method 又會發生什麼事呢?這些 method 所推延的normalizemethod 會在最後成功執行嗎?
答案是:不會!
還記得 normalize 將主要段落包進 withoutNormalizing 這件事嗎?
這麼做除了會讓 normalize method 被重複執行之外,也會同時將 NORMALIZING 設為 false ,因此在新的 Transform method 執行的過程中所呼叫的 normalize method ,包含 Transform 開頭包進 withoutNormalizing 受到推延執行的那一組 normalize method 都會因為 NORMALIZING 被設為 false 而跳出:
// New "Transform" call during "normalizeNode"
withoutNormalizing(editor: Editor, fn: () => void): void {
const value = Editor.isNormalizing(editor) // set "value" to false
NORMALIZING.set(editor, false)
try {
fn()
} finally {
NORMALIZING.set(editor, value) // set "NORMALIZING" the value of "value" variable, which is still false
}
Editor.normalize(editor) // "normalize" won't execute successfully since "NORMALIZING: false"
}
因此在過程中執行新的 Transform 只會更新 document 以及 Dirty-Paths 的 value 而已,並不會再次出發執行另一組 Normalization ,直到完整執行完 Transform 的內容以後才會回到原本尚未執行完的 normalize method 裡,以新的 DIRTY_PATHS value 繼續執行正規化。
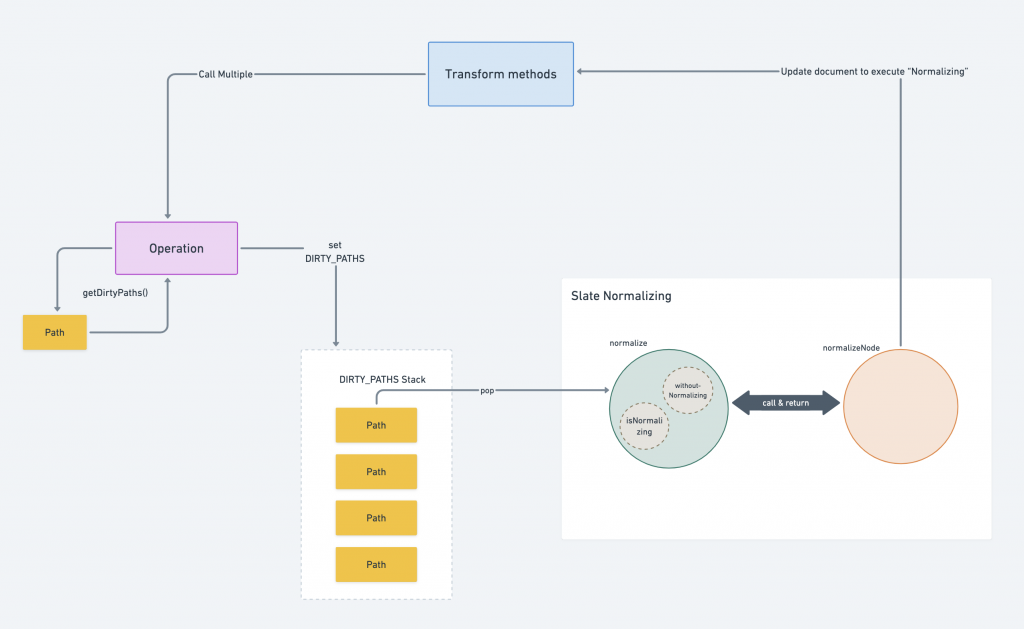
綜合前兩篇介紹的內容,我們可以將整個 Normalizing 與 Transform / Operation 的互動流程以下圖呈現:
這一段的 code 基本上與 normalizeNode 實作第 1. constraint 的內容大同小異。
就是取出所有的 Dirty-Paths ,確保這些路徑指向的節點都確實存在於 document 裡之後,將不存在子節點的 Element node 插入空的 Text void 節點:
Editor.withoutNormalizing(editor, () => {
/*
Fix dirty elements with no children.
editor.normalizeNode() does fix this, but some normalization fixes also require it to work.
Running an initial pass avoids the catch-22 race condition.
*/
for (const dirtyPath of getDirtyPaths(editor)) {
if (Node.has(editor, dirtyPath)) {
const [node, _] = Editor.node(editor, dirtyPath)
// Add a text child to elements with no children.
// This is safe to do in any order, by definition it can't cause other paths to change.
if (Element.isElement(node) && node.children.length === 0) {
const child = { text: '' }
Transforms.insertNodes(editor, child, {
at: dirtyPath.concat(0),
voids: true,
})
}
}
}
}
最後我們放上一張延續 Day10 , Slate 完整的運作流程圖:
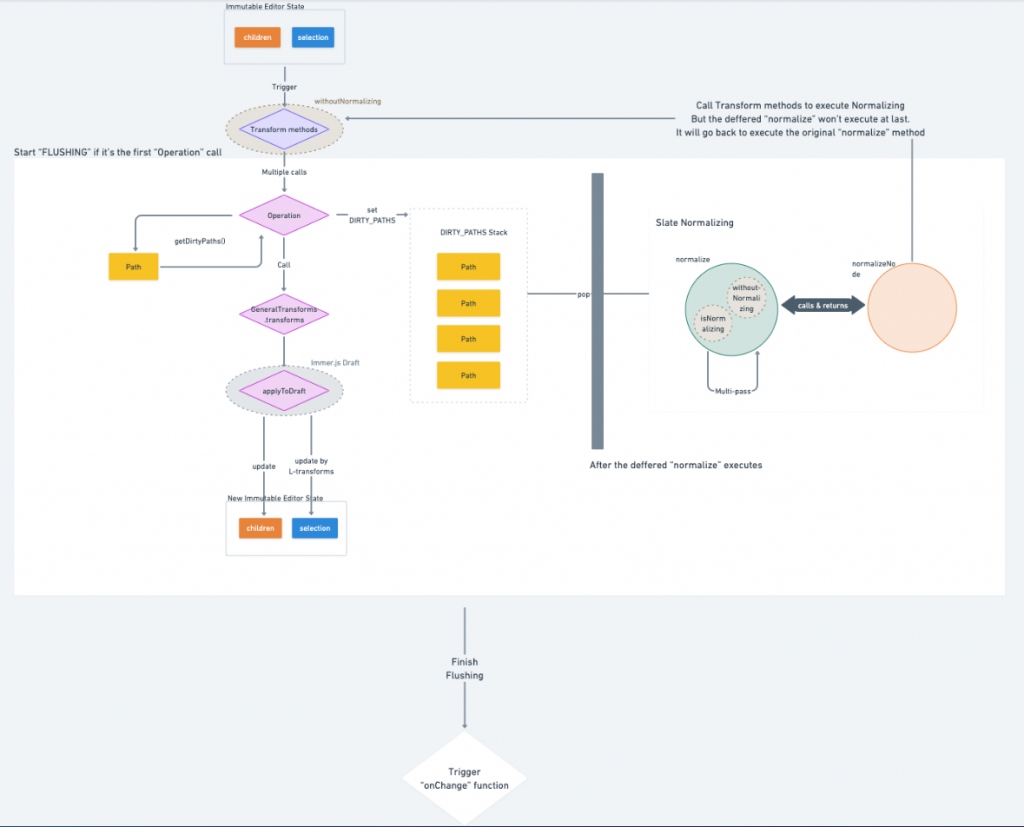
transform 與 normalize 之外,也會將 FLUSHING 設為 true ,並將 onChange 的執行以 Promise 的 Micro-Task 包裝起來getDirtyPath 取得並更新 DIRTY_PATHS WeakMap variableGeneralTransforms.transform 搭配 Immer Draft State 呼叫 applyToDraft 更新 children 與 selection
normalize method 搭配 normalizeNode 執行 Dirty-Paths 的節點正規化,再次呼叫 Transform 來更新節點以滿足 constraints 的規範並重跑一次相同的 Transform 流程,除了被推延的 normalize 不會正確地被執行以外FLUSHING 設為 false 並觸發 onChange function ,結束一輪完整的編輯器更新!到此為止我們終於完整介紹完了一整輪 Slate 編輯器的運作與更新流程了!整個正規化的章節也在今天告一個段落~
相信具備了完整知識的讀者們未來在開發上或是處理類似的情境問題時都會更有解題的方向。
接下來我們準備要進入到整個系列文章的最後一個章節:『 Transform 』。
前面這麼常提到它,相信讀者對它肯定是不陌生的,一切相關的介紹我們就留到明天吧~

