
標題取名的緣由一方面來自於d3JS的全名Data-Drive-Documents令一方面Documents-Delivered-Data可以算是本日的重點,要從Documents(也就是網頁)Delivered(傳遞)Data(資料),做為資料視覺化的主題當中,資料是最根源的一項要素,從第一天到現在的的範例,絕大多數都是使用真實的資料,不敢說是無瑕的程式碼,但希望能藉由處理的過程當中讓讀者們了解到資料的預處理重要性及方法,做為D3Js的主題剩下幾天想談一些關於擷取資料和資料知識來契合整個主題的完整型,我們今天預計將使用Puppeteer來獲取鐵人賽文章名稱為d3.js的tag,之後一樣會繪製出圖表並且稍微講解一些基本統計數值的意義,這些統計數值也是D3Js的API所提供。
另外需要注意的地方是使用爬蟲軟體如果反覆對網頁伺服器發送請求,可能伺服器端的程式有偵測短時間大量相同IP發出網頁請求或是其他偵測項目而遭到封鎖,請深思後果後使用。
Puppeteer 是Node.js的套件,可以控制瀏覽器,研發團隊來自於Google,可以使用在瀏覽器的自動化測試、爬蟲。
如果想要檢查自己寫的網頁每個連結是否有效,每個按鈕是否正確,如果當前端網站每次寫完的時候都要用人工的方式手動按下這些鍵是十分花時間的事情,因此可以藉由自動化工具來進行,Puppeteer可以開啟瀏覽器操控許多事情,模擬表單輸入、點擊按鈕、跳轉頁面
爬蟲的意思是指說可以讀取網頁的內容,另外可以藉由程式存在一個變數或者檔案當中,例如我們想要得知網頁上所有連結,可以找到含有<a></a>標籤的字將裡面的href屬性存成一筆陣列,藉由這種機制我們可以解決重複的事情,也算是某種程式設計師的思維—解決重複的事情。
首先要下載 node JS
到node Js官網的下載頁面如下圖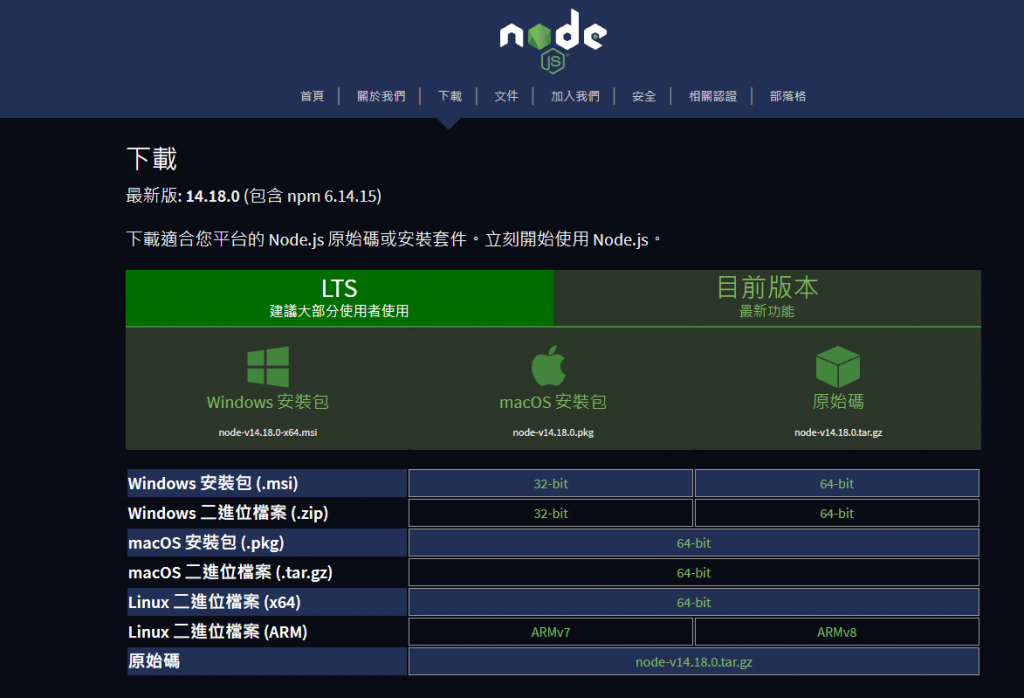
一般來說建議下載LTS(Long Term Support),算是比較穩定的版本。
依據你的作業系統下載,基本上使用預設next→next就可以了。

下載完畢後
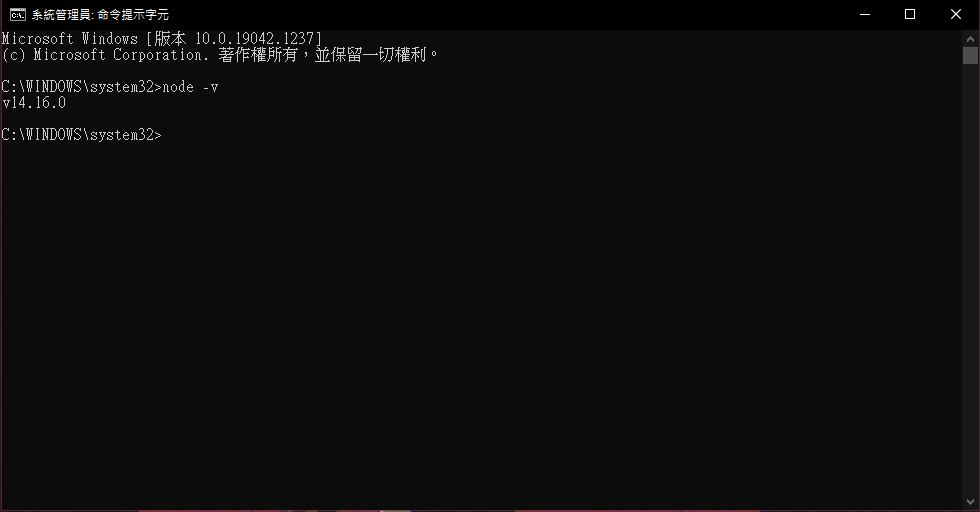
以windows為例 輸入cmd來打開命令提示字元視窗
輸入node -v
可以看到node 的版本顯示的話就代表安裝成功了
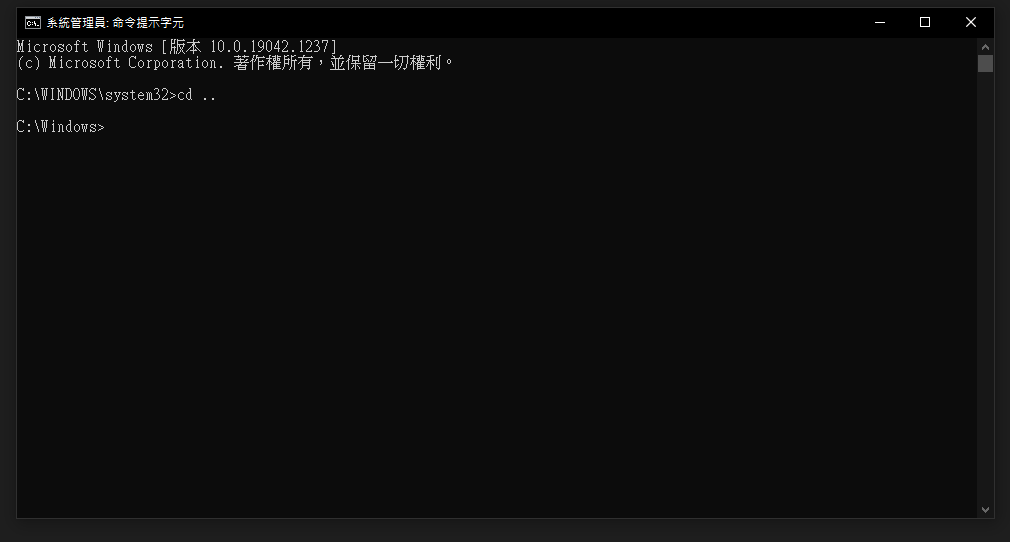
使用cd .. 回上層目錄 如下圖
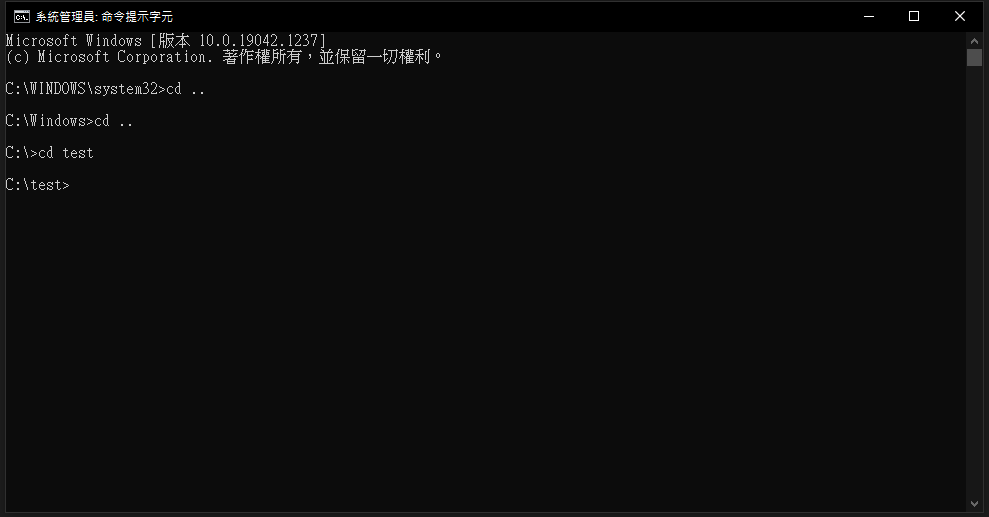
使用cd [目標資料夾名稱] 代表移動到該資料夾 如下圖
cd移動到你要安裝套件的資料夾之後輸入npm install puppeteer
這邊指令意思是npm套件管理 安裝 puppeteer
安裝過程如下圖
有關更多npm的知識可以查看以下維基或到NPM官方網站查看
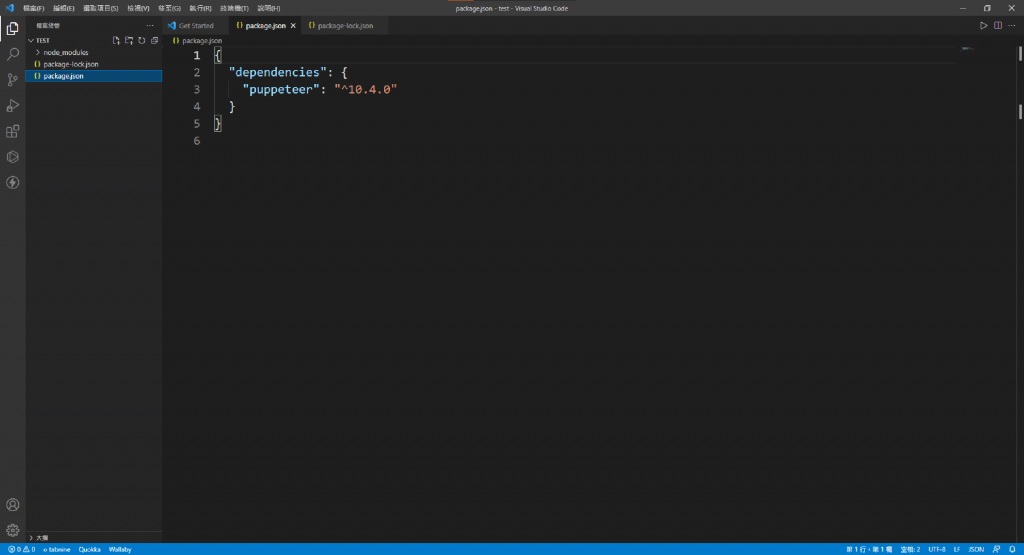
使用Visual Studio Code打開package.json查看dependencies內容含有puppeteer也代表記錄了你安裝了puppeteer
安裝完畢後,接下來就可著手開始寫js,我們創建一個叫做index.js的檔案
這邊我們要引入module
使用require函式在nodeJs環境當中要引入module
官方puppeteer建議使用async的方式來撰寫
因此我們先選告一個scrape的async函式
說明可以觀看註解
如下
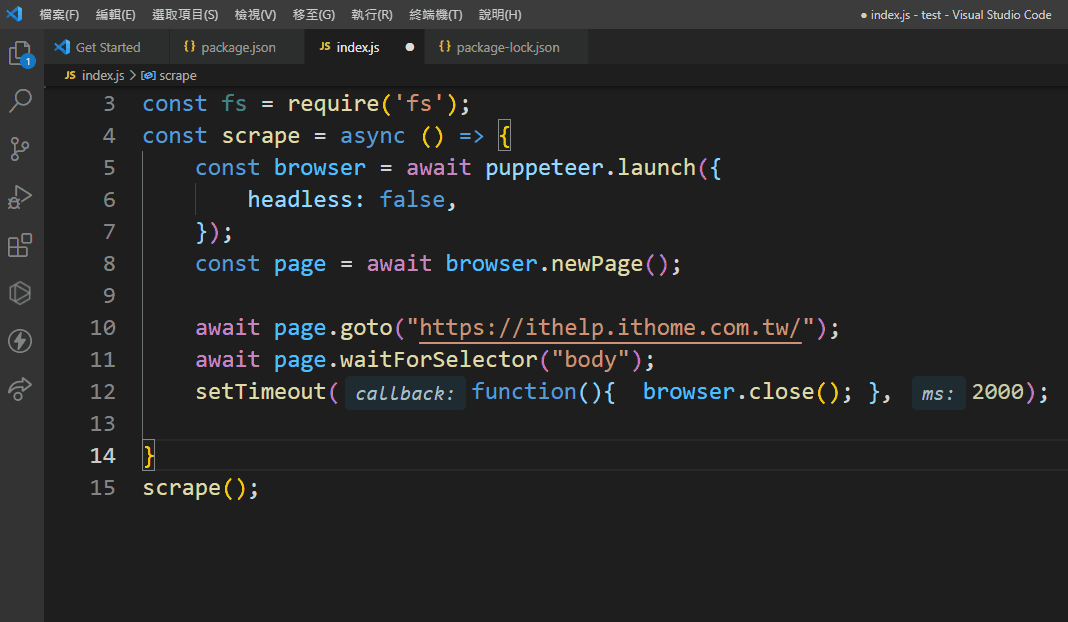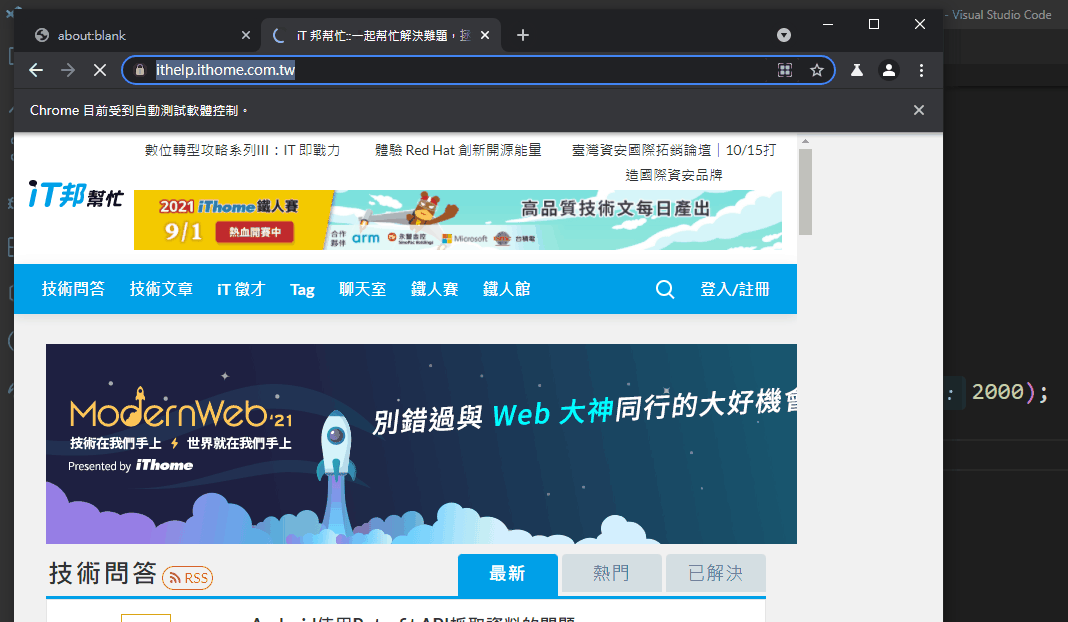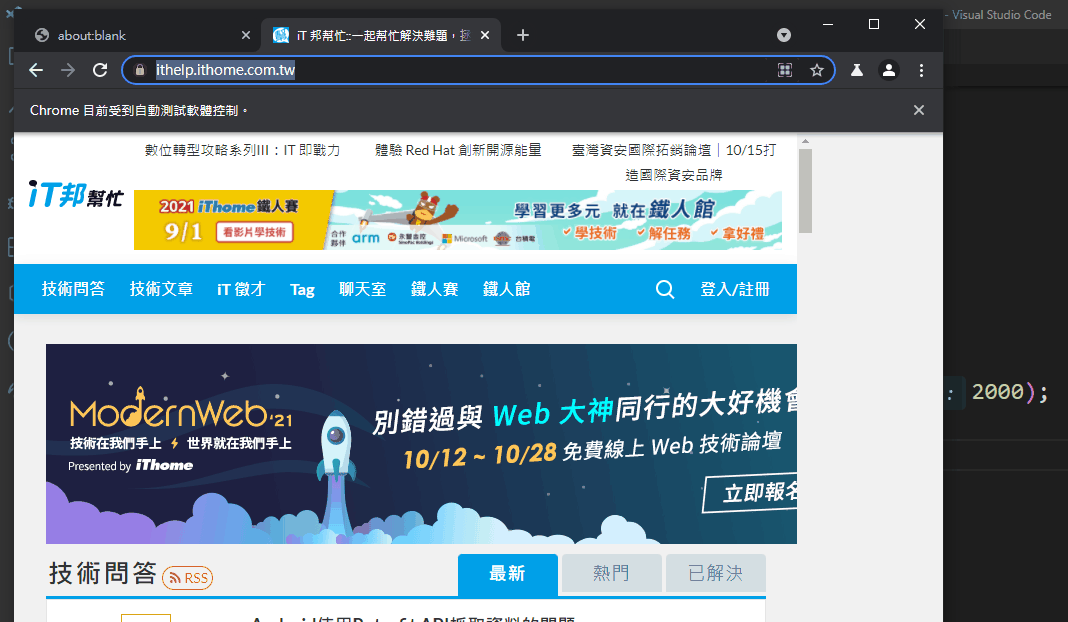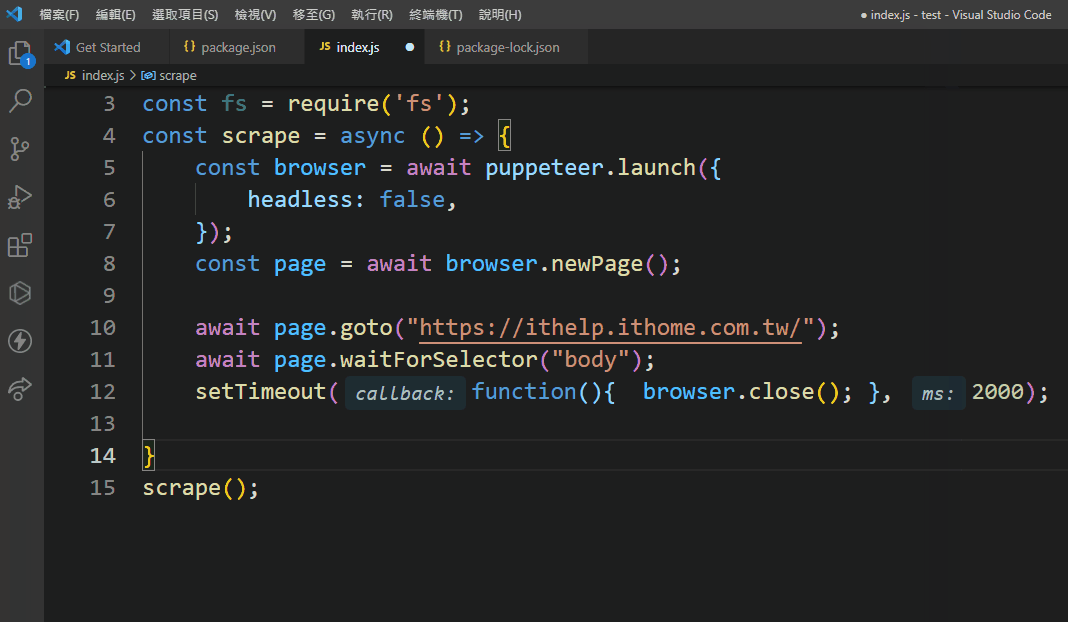
const puppeteer = require("puppeteer"); //使用require引入puppeteer module
const scrape = async () => {
const browser = await puppeteer.launch({ //啟動瀏覽器
headless: false, //是否設定無頭模式,設定false將會真的開起瀏覽器反之亦然
});
const page = await browser.newPage(); //開啟一個新分頁
await page.goto("https://ithelp.ithome.com.tw/"); //前往該網址
await page.waitForSelector("body"); //等待body載入
setTimeout(function(){ browser.close(); }, 2000); //兩秒後關掉瀏覽器
}
scrape();
開啟命令提示字元記得cd到剛剛安裝的資料夾底下後,輸入node index.jsnode [你的JS檔案名稱] 代表執行該JS檔案
這時候你應當可以看見如下的畫面
順帶一提如果使用命令提示字元執行
node [你的檔案名稱]想要中斷執行程式,在命令提示字元按下ctrl+c就能退出了
由於設定headless: false,所以他會實際開啟瀏覽器執行,如上圖也可以發現瀏覽器會寫Chrome目前受到自動測試軟體控制
這邊要介紹一個函式,我們預計使用page.evaluate函式來擷取DOM的內容在function裡面就可以使用瀏覽器的API像是document.querySelector來選取元素,
await page.evaluate(function(){
})
按下ctrl+shift+i開啟開發人員工具找到方形帶有游標的圖樣按下去
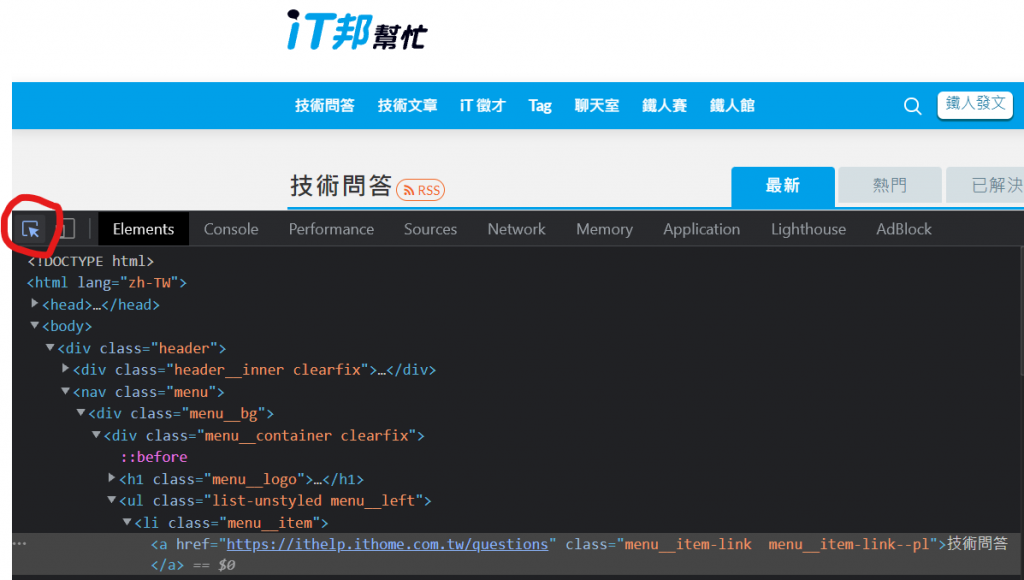
接下來你滑鼠游標移到網頁要選的區域後,它就會自動幫你選到該element了如下圖
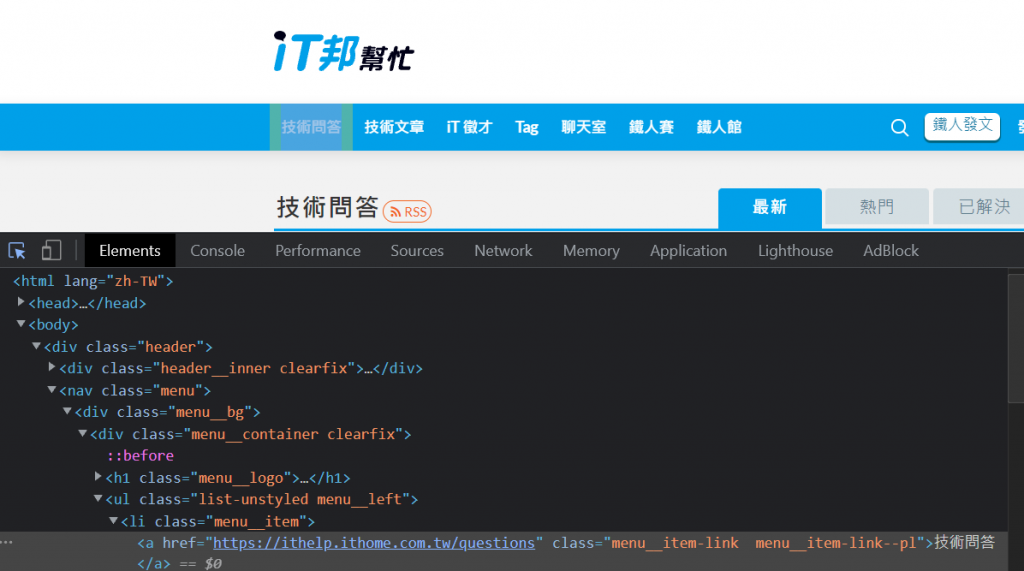
滑鼠移到該Element(這邊以如下圖的<ui>為例)按滑鼠右鍵選擇Copy→Copy selector
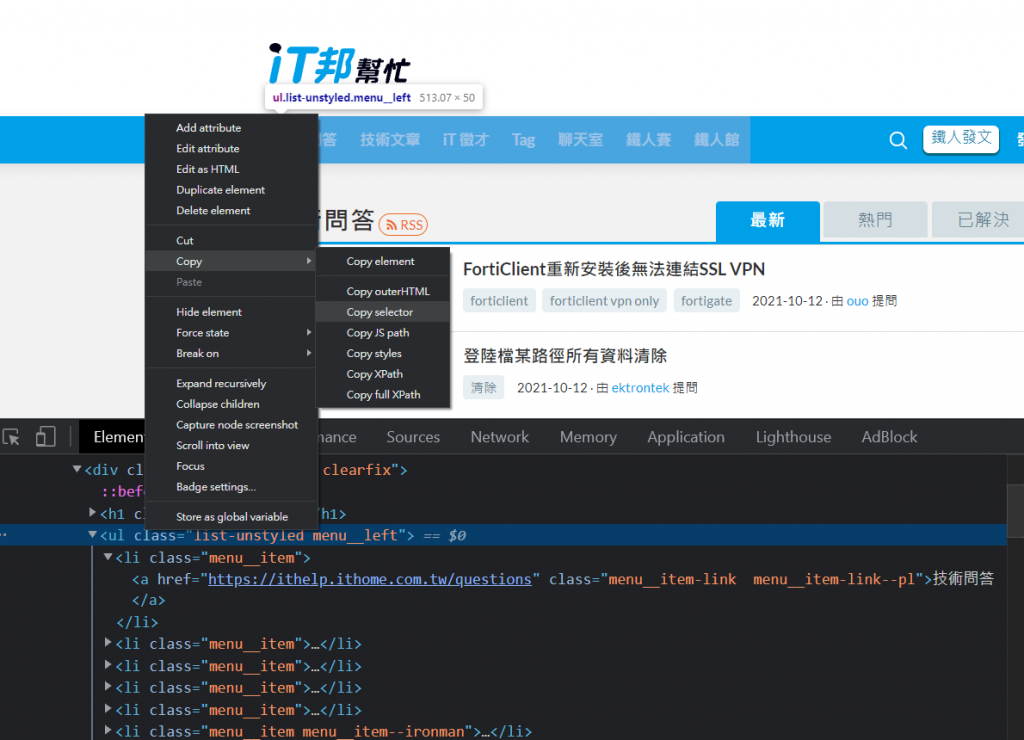
複製完後回到程式碼 我們嘗試著將剛剛複製的東西貼到evaluate裡面的callbackFunction,然後使用innerText取裡面的文字,最後return給str,然後我們試著將str印出來試試看
const puppeteer = require("puppeteer");
const fs = require('fs');
const scrape = async () => {
const browser = await puppeteer.launch({
headless: true,
});
const page = await browser.newPage();
await page.goto("https://ithelp.ithome.com.tw/");
await page.waitForSelector("body");
let str = await page.evaluate(() => {
return document.querySelector("body > div.header > nav > div.menu__bg > div > ul.list-unstyled.menu__left").innerText;
})
console.log(str);
browser.close();
}
scrape();
最後應當會看到如下圖,依照剛剛的程式碼,得到了每個連結的文字內容
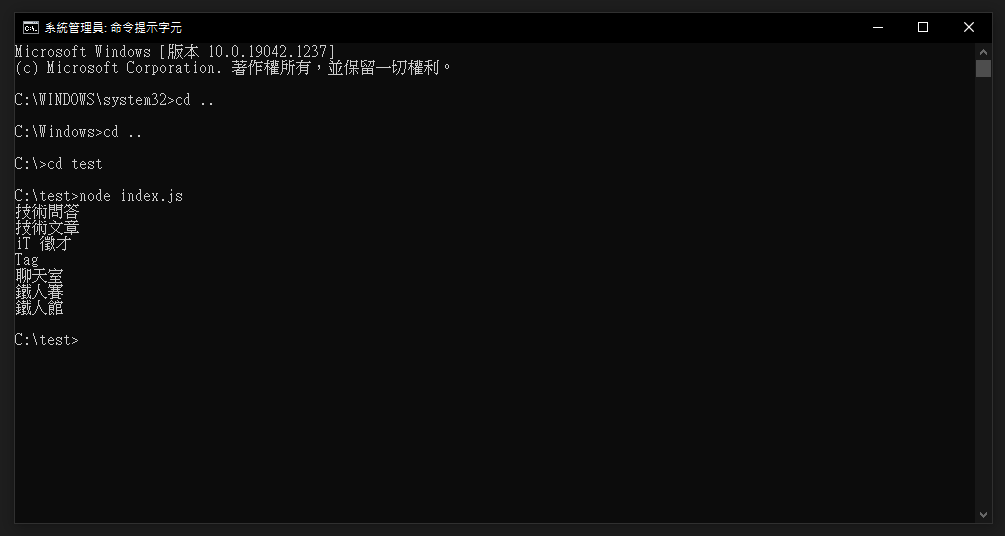
因此我們就可以使用此方法來獲取網頁的元素
接下來我們要使用另一個moduler叫做fs來產生json檔案
我們可以先撰寫一段code並且使用node [你的檔案名稱.js],看看
可以先寫在index.js這支檔案裏面並且使用node index.js執行
const fs = require('fs');
fs.writeFile('test.txt', '哈囉世界', function (err) {
if (err)
console.log(err);
else
console.log('json檔案撰寫完畢');
});
這時候你看到檔案總管會發現應當多了一個文字檔按叫做test.txt,它來自於你剛剛的程式碼所產生的檔案
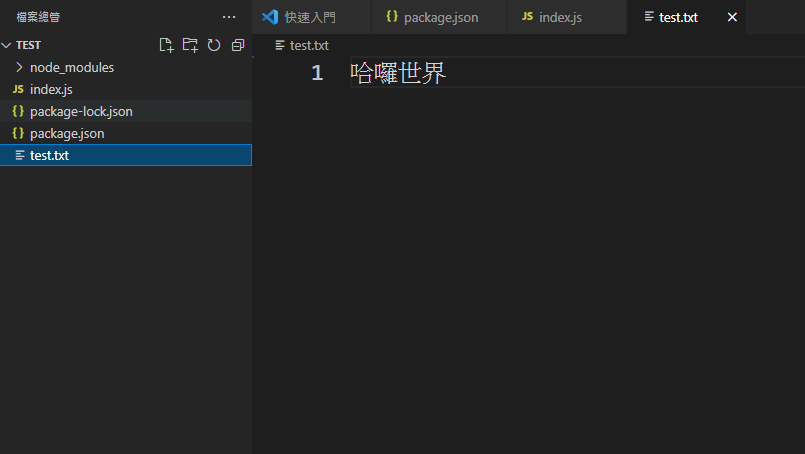
因此我們可以使用這個方式來產生json檔案
結合剛剛所抓取網頁的資料元素的程式碼應當會如下
const puppeteer = require("puppeteer");
const fs = require('fs');
const scrape = async () => {
const browser = await puppeteer.launch({
headless: true,
});
//如先前的程式碼故省略
//如先前的程式碼故省略
//如先前的程式碼故省略
browser.close();
return str;
}
scrape().then(function (data) {
let obj = {};
obj.data = data;
let objStr = JSON.stringify(obj);
console.log(dataStr);
fs.writeFile('test.json', objStr, function (err) {
if (err)
console.log(err);
else
console.log('撰寫完畢');
});
}).catch(error => console.log(error.message));
我們創建一個Object來放所得到的資料,需要注意的地方是由於JSON格式必須為字串,因此使用JSON.stringify先將物件轉成字串,最後使用剛剛引入的fs module來寫入
最後應當可以看到產生了一個json檔案如下圖

首先我們先找到你要的標籤這裡以d3JS為例如下圖
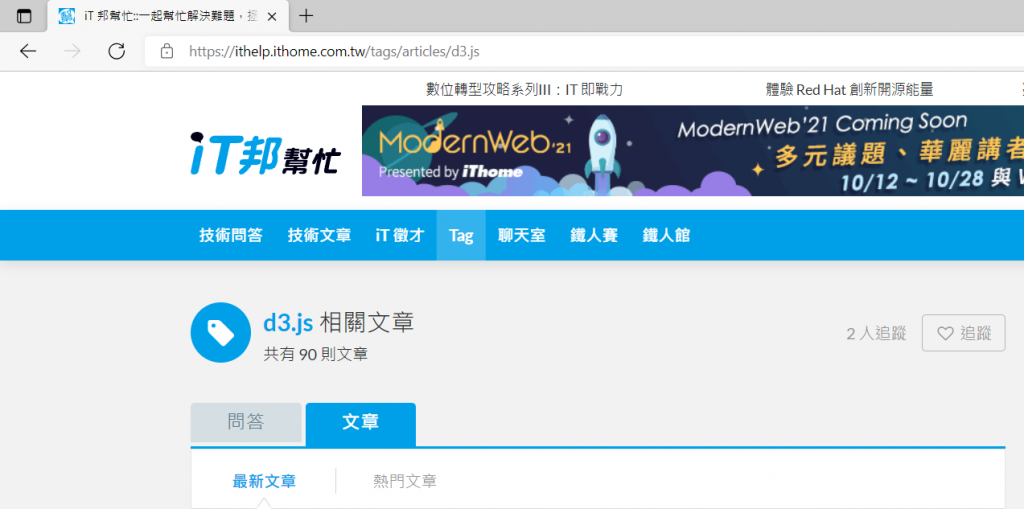
我們可以點到第二頁查看可以發現網址多了?page=2
策略是先得知總共有幾頁,然後再依序進入該頁面把所有的文章連結存成一個陣列後遍歷它進入每篇文章,對每篇文章的瀏覽數、留言數等等存起來,以此類推就能得到所有文章的瀏覽數、留言數等等的資訊了。
在上方會宣告一個allPeoplePagesAry來存放所有文章的資料
另外多撰寫await page.setDefaultNavigationTimeout(0);的原因主要是由於puppeteer的頁面跳轉如果大於30秒的話就會顯示錯誤如下error { TimeoutError: Navigation Timeout Exceeded: 30000ms exceeded,因此這邊設定0(表示持續等待的意思)來讓程式等待到畫面跳轉為止
程式碼內容如下
const puppeteer = require("puppeteer");
const fs = require('fs');
const scrape = async () => {
const browser = await puppeteer.launch({
headless: true,
});
const page = await browser.newPage();
await page.setDefaultNavigationTimeout(0);
const allPeoplePagesAry = [];
await page.goto("https://ithelp.ithome.com.tw/tags/articles/d3.js?page=1");
await page.waitForSelector("body");
}
接下來我們獲取總共的頁數
主要是獲取網頁最下方的頁數

這邊程式碼選取倒數第二個數字裡面的字串,因此寫li:nth-last-child(2)
let PageNum = await page.evaluate(() => {
return Number( document.querySelector(".tag-pagination > ul li:nth-last-child(2)").innerText);
})
console.log("總共有"+PageNum+"頁");
得到總共有幾頁之後我們就撰寫一個for迴圈來遍歷頁數
// 開始跑所有頁數
for (let index = 1; index <= PageNum; index++) {
await page.goto(`https://ithelp.ithome.com.tw/tags/articles/d3.js?page=${index}`)
// 獲取這一頁所有的連結
let currentPageHref = await page.evaluate(() => {
let href = document.querySelectorAll(".qa-list__title-link");
let ary= [];
href.forEach(function (el){
ary.push(el.getAttribute("href"));
})
return ary;
})
}
依照該頁面css的class我們獲取該頁面所有文章的連結存到currentPageHref陣列裡面
之後我們找出該頁面所需要的內容元素存成一個物件,程式碼如下
// 開始把這一頁的連結給爬一爬
for(let i=0; i<currentPageHref.length; i++){
await page.goto(currentPageHref[i]);
await page.waitForSelector("body");
let obj = await page.evaluate(()=>{
let obj = {};
let articleStrNum = document.querySelector(".markdown__style").innerText.replace(/\s*/g,"").length;
let articleTitle = document.querySelector(".qa-header__title").innerText.trim();
let view = document.querySelector(".ir-article-info__view")||document.querySelector(".qa-header__info-view");
let viewNum = Number(view.innerText.match(/\d+/g));
let likeNum = Number(document.querySelector(".likeGroup__num").innerText);
let commentNum = Number(document.querySelector(".qa-action__link--reply").innerText.match(/\d+/g));
let postTime = document.querySelector(".qa-header__info-time").innerText;
obj.articleTitle = articleTitle;
obj.articleStrNum=articleStrNum;
obj.viewNum = viewNum;
obj.likeNum = likeNum;
obj.commentNum = commentNum;
obj.postTime = postTime;
return obj;
})
obj.currentPageHref = currentPageHref[i];
allPeoplePagesAry.push(obj);
console.log("這是第"+index+"頁的第"+(i+1)+"個標題");
}
document.querySelector(".markdown__style").innerText.replace(/\s*/g,"").length;document.querySelector(".ir-article-info__view")||document.querySelector(".qa-header__info-view");來存取querySelector 如果是鐵人賽的文章class叫做.ir-article-infoview,如果是一般的文章叫做.qa-headerinfo-viewNumber(view.innerText.match(/\d+/g));解析觀看次數另外為了得知目前爬取的進度我在for迴圈裡面一併印出第幾頁第幾個標題來顯示當前頁數和標題數。

最後我們撰寫scrape()並在.then接收剛剛所取得的資料寫入json檔案,程式碼如下
scrape().then(function(allPeoplePages){
console.log(allPeoplePages);
let allPeoplePagesStr = JSON.stringify(allPeoplePages);
fs.writeFile('allPerson.json', allPeoplePagesStr, function (err) {
if (err)
console.log(err);
else
console.log('寫入完畢');
});
})
最後打開json可以看到如下圖就代表恭喜你成功爬取到網頁文章的元素了。
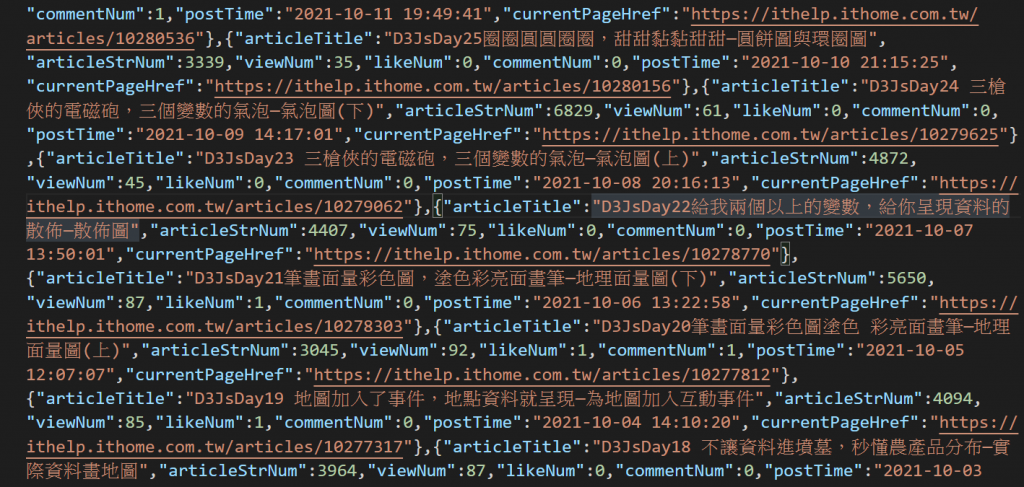
本日爬取到的Json資料預計將會作為d3Js的資料引入,期待明天如何處理這些資料和訴說什麼故事吧。



 iThome鐵人賽
iThome鐵人賽