撰寫機器學習/深度學習相關程式時,我們常要調整超參數(Hyperparameters),觀察模型的準確度或其他效能指標的變化,如果能設計各式輸入欄位,就很容易說明 what-if 或將程式提供他人使用。
ipywidgets套件提供我們在 Jupyter Notebook 內設計各式輸入欄位,安裝指令如下:
pip install ipywidgets
之後啟動 Jupyter Notebook 確定是否安裝成功: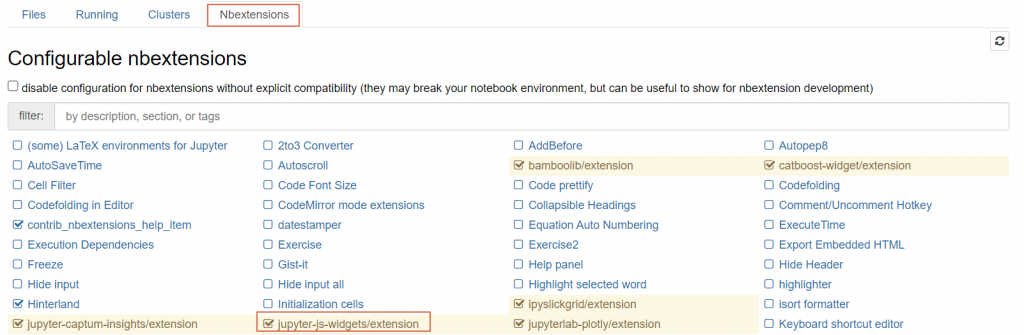
如果未現該擴充程式,執行以下指令,並確定有打勾:
jupyter nbextension enable --py widgetsnbextension
# 載入套件
from ipywidgets import interact
# 定義一個簡單函數
def f(x):
return x
# 呼叫 interact 函數,如 x 為整數則輸入欄位為一拉桿(slider)
interact(f, x=10)
執行結果如下,拖曳拉桿,可改變輸入值:
# 如 x 為boolean則輸入欄位為 checkbox
interact(f, x=True)
# 如 x 為字串則輸入欄位為文字框
interact(f, x='')
# 如 x 為list則輸入欄位為下拉式欄位
interact(f, x=[1,2,3])
interact 會視 x 參數資料型態產生各式輸入欄位。
# 使用裝飾器(Decorator)
@interact(x=20, y=1.0)
def g(x, y):
return x + y
雖然在畫面上可以看到我們輸入值,但沒辦法在下面的程式碼抓到它,筆者一度腦筋打結,後來google一下,才了解必須要在函數中使用輸入值,以下介紹兩種應用。
# 篩選資料
import pandas as pd
import numpy as np
from sklearn import datasets
@interact(x=[0,1,2])
def f(x):
# 載入鳶尾花資料
ds = datasets.load_iris()
df=pd.DataFrame(ds.data, columns=ds.feature_names)
df['y'] = ds.target
# 依據輸入值篩選資料
return df.query(f'y == {x}')
執行結果如下,改變輸入值可篩選資料: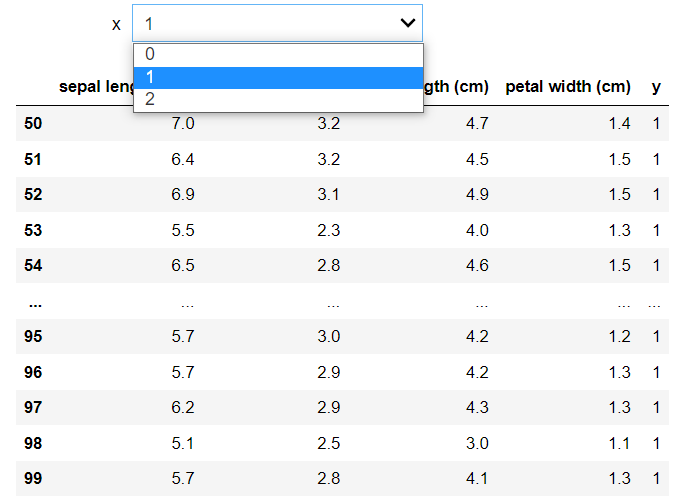
import pandas as pd
import numpy as np
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
@interact(x=(3,11))
def f(x):
# 載入鳶尾花資料
ds = datasets.load_iris()
X=pd.DataFrame(ds.data, columns=ds.feature_names)
y=ds.target
# 切割訓練及測試資料
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = .2)
# KNN 模型的 n_neighbors 參數調校
clf = KNeighborsClassifier(n_neighbors = x)
clf.fit(X_train, y_train)
return f'score={clf.score(X_test, y_test)}'

夠簡單吧? 美中不足的是,沒辦法在函數外抓到輸入值,還好有人解決這個問題,請待下回分解。
 I code so I am
I code so I am
