在上一篇文章中 Neo4j Graph Data Science 基本語法與演算法實作資料分析,我重新介紹了 Neo4j GDS 的基本概念與操作方式,以及一部分的演算法分析資料,這次我想挑戰更進階的應用:金融詐欺檢測,使用 Neo4j Sandbox 提供的分析步驟與方法來練習,其中 Fraud Detection 專案便使用了 PaySim 數據,以及一連串的 Neo4j Cypher 和 GDS 演算法,來模擬在龐大的金融交易紀錄中,找出金融詐欺的嫌犯。
因為是以練習 Cypher 與 GDS 演算法為目的,基本上都會與官方教學的範例與步驟相同,但一部分 Cypher 指令有做些修改或解釋,以及我沒有打算用官方做好的資料,而是用 PaySim 重新模擬出更大量的數據,模擬的方式也會一併分享。
對於不是直接在銀行或保險業上班的人,根本無法取得真實世界中的交易資料,即便是銀行職員也不見得有這樣的權限。所幸 Lopez-Rojas、Elmire 和 Axelsson 在 2016 年發布了 PaySim 模擬工具。
它是一個行動支付的交易紀錄模擬器,可以想像成 Apple Pay,有電子錢包的功能可以儲值,用戶間可以互相轉帳匯款,或是與商家進行交易,也可以把錢轉出轉入銀行,這些資料參考了真實的商務系統產生的交易日誌,進一步模擬與合成。
Neo4j Sandbox 提供的 PaySim 資料集大約有 33 萬個資料節點、100 萬筆關聯,其中包含 2500 位客戶、32 萬筆交易紀錄。
如果想自己產生不同的數據,可以參考 PaySim Github,但輸出的格式是CSV,且教學有點少,還要自行匯入 Neo4j。
但是後來一位 Neo4j 工程師 Dave Voutila,他 FORK 出一個新的 Github project https://github.com/voutilad/PaySim ,把原本的工具改寫成 Library,以便可以被其他 Java 程式直接調用,並改善原本詐欺行為模式過於單純的問題,為詐欺者加入更多的行為模式,以便貼近真實世界的案例。
之後他再開發了一個 PaySim demo project ,使用上述改好的 PaySim Library,搭配一篇很完整的教學文章 https://www.sisu.io/posts/paysim-part2/ ,教大家如何用 PaySim 直接匯入 Neo4j 的資料庫,省略了中間 CSV 轉換的過程,真是太佛心了!
這一段會分享如何用 Dave Voutila 的 PaySim demo project 來自定義產生的 PaySim 數據,並直接匯入 Neo4j,如果沒有這個需求,可以直接略過。
paysim-demo 是一個 gradle wrapper 專案,git clone 之後直接用 gradle wrapper 執行即可
./gradlew runBolt
預設會用 bolt protocol 連線到本機 Neo4j 7687 port,設定檔請參考 src/main/java/io/sisu/paysim/Config.java,也可以在這裡設定你自己的資料庫帳密。
不過仍建議直接打包成可執行檔,以上的參數都可以用參數傳遞
./gradlew distTar
打包完成後,會在 build/ 得到 tar 檔案,例如 ./build/distributions/paysim-demo-0.8.3.tar
以下是我執行的指令
bin/paysim-demo bolt --uri bolt://172.29.64.1:7687 --username neo4j --password 12345678
這邊 bolt connection 不是預設的 localhost,而是我的電腦 private ip,因為我是在 WSL2 Ubuntu 執行 paysim-demo,匯入到 Windows 的 Neo4j。除了要明確指定匯出的 IP,也要設定 Neo4j 允許 remote connection
dbms.default_listen_address=0.0.0.0
客製化數據的部分,則要修改 PaySim.properties,以下是我的參數,我直接用註解來說明。
seed=666666 # 修改 seed 來產出不同特徵的資料
nbSteps=720 # 最大值 720 步,一步相當於於 1 小時,也就是最多模擬真實世界一個月的交易量,這是源自 PaySim 原本的限制
multiplier=1 # 方便分析師快速的加倍資料量,請小心使用。2 的意思就是以下參數全部乘以 2
nbClients=80000 # 產生大約 8 萬名客戶
nbFraudsters=2000
nbMerchants=3000
nbBanks=5
以上的參數為我重新產出了約 1410 萬個資料節點、4160 萬個關聯,80000 個客戶、3000 家合作商店、5 家銀行、1370 萬筆交易紀錄。
不過因為這個數據比官方的版本大得多,所以我也一併重新調整了記憶體相關的參數如下,僅供參考。這部分的優化可參考官方文件 guide-performance-tuning 、memory-configuration
dbms.memory.heap.initial_size=24G
dbms.memory.heap.max_size=24G
dbms.memory.pagecache.size=28G
dbms.memory.transaction.global_max_size=8G
dbms.memory.transaction.max_size=4G
Fraud Detection 專案一開始就指出了兩種詐欺行為,作為分析資料集的目標
在網路上翻了一輪,找到 experian(一家美國-愛爾蘭跨國消費者信用報告公司) 的文章 The different types of fraud and how they’re changing,詳細介紹了詐欺的分類與常見行為模式如下。
總歸來說,個人或群體歪曲其身份或提供假訊息來獲得利益。
意指個人故意將其身分或資料提供給他人進行詐欺,也就是上一小節提到的「錢驢」。常見的就是提供人頭帳戶給詐騙集團在銀行出入資金,以換取少量報酬,而這種詐欺金額還很有可能是犯罪活動或洗錢的結果,可用於資助恐怖主義、剝削和暴力犯罪。
年輕人和弱勢群體一直是第二方欺詐的目標。社交媒體已被大量用於以這種方式針對年輕人和弱勢群體。
通常就的是身份盜用,也就是未經個人同意,在其不知情下使用其身份獲得信用、服務或產品,這還包括製造假的身份,例如藉由收集來的非法個資去憑空創造新的身份。
如果自己 Google「三方詐騙」,就會發現網路上許多報導,各地警局也有貼出告示作為警惕,因為這種詐騙充斥你我的生活之中,防不勝防。
從上述三種詐欺形式來看,可以發現一個共通點:詐欺行為的發生,或多或少會伴隨著個人身份的盜用與共享。
了解資料集的結構與分布概況,已經是資料分析的起手式了
可直接參考 Dave Voutila 的文章介紹 PaySim資料模型
或是自行用 Cypher 語法得知
CALL db.schema.visualization();
CALL apoc.meta.subGraph({
labels: ['Client', 'Email', 'Phone', 'SSN', 'Transaction', 'Bank', 'Merchant']
})
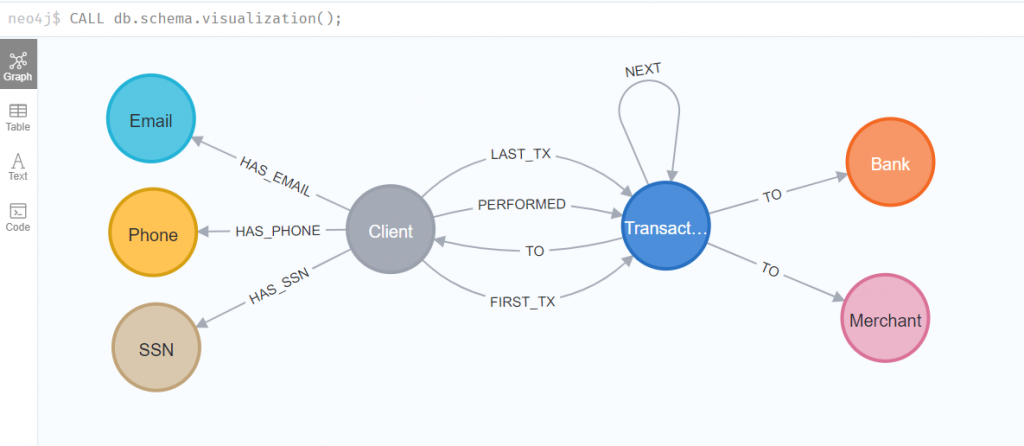
從這個資料結構可以看出,每一位客戶(Client),有其個人資料,目前只有 Email、電話和美國社會安全碼SSN,這是簡化過的模型,實際上的個人資料當然會更多。客戶同一時間會和其他客戶、銀行、商家有零到多筆交易,這個資料模型聚焦在客戶發起的交易行為,也是為了學習資料分析而簡化過的,實際上交易行為應該是因商業模式變化,多向性且複雜,例如商家與商家,或商家與銀行。
※ APOC Library 是 Neo4j 的實驗室專案之一,集合了大約 400 個常用的預存程序或函數,可參考我之前的文章介紹
https://ithelp.ithome.com.tw/articles/10244205
使用 APOC 提供的函數,直接可得知這個資料集有些什麼樣的節點和關聯,以及數量
CALL apoc.meta.stats();
官方教學仍列出了自行用 Cypher 語法查詢的方式,如下。
CALL db.labels() YIELD label
CALL apoc.cypher.run('MATCH (:`'+label+'`) RETURN count(*) as count', {})
YIELD value
RETURN label, value.count AS Count
CALL db.relationshipTypes() YIELD relationshipType as type
CALL apoc.cypher.run('MATCH ()-[:`'+type+'`]->() RETURN count(*) as count', {})
YIELD value
RETURN type, value.count AS Count
查詢所有的交易類型與交易總額的百分比例
MATCH (t:Transaction)
WITH count(t) AS globalCnt, sum(t.amount) as totalAmount
UNWIND ['CashIn', 'CashOut', 'Payment', 'Debit', 'Transfer'] AS txType
CALL apoc.cypher.run('MATCH (t:' + txType + ') RETURN count(t) AS txCnt, sum(t.amount) AS txAmount', {}) YIELD value
RETURN
txType,
value.txCnt AS NumberOfTransactions,
round(toFloat(value.txCnt) * 100 / toFloat(globalCnt), 2) AS `%Transactions`,
round(toFloat(value.txAmount) * 100 / toFloat(totalAmount), 2) AS `%Amount`
ORDER BY NumberOfTransactions DESC;
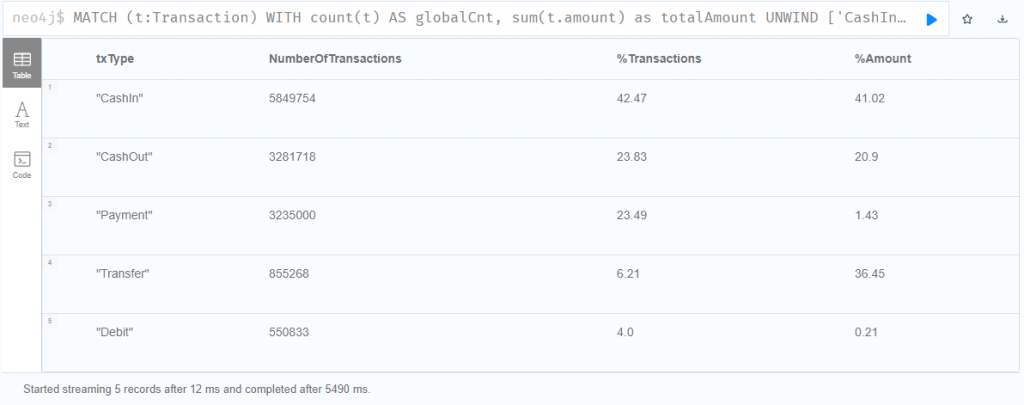
從上圖可以看出,最大的交易量和最大交易額都是 CashIn,比較特別的是用戶間的轉帳 Transfer,交易量只占 6%,但交易總額卻高達 36% 之多!
這邊我發現一個有趣的點,雖然有點事後諸葛~
就是所有的交易類節點,都必然有 Transaction 標籤,這感覺很像一種「繼承」的概念,我自己可能受到傳統關聯式資料庫的荼毒太深了XD,所以比較少設計多重標籤,但上述的結構讓我重新思考 Neo4j 多重標籤的設計方式與可能性!
官方教學提出了一個基本假設,就是「兩個用戶共享了個人身分資訊,例如電話、Email、SSN等,是可疑的,會有比較高的機率進行詐欺」,其實這樣的假設也是呼應了前面介紹詐欺分類的描述。
當然這不是絕對的,每一個共享其本質是沒問題的,但是被愈多人共享的個資是可疑的,而使用這些個資的用戶,就愈有可能是詐欺犯。這個基本假設可能來自於銀行的經驗吧。
所以我們需要有一些演算法來計算這些客戶的詐欺分數,將分數最高的客戶們取一個比例,才標示為詐欺犯。
找出所有至少共享一項個資的用戶,以及實際上共享的個資數量
MATCH (c1:Client)-[:HAS_EMAIL|:HAS_PHONE|:HAS_SSN]-> (n) <-[:HAS_EMAIL|:HAS_PHONE|:HAS_SSN]-(c2:Client)
WHERE id(c1) < id(c2) // 為避免重複列出,所以用小於
RETURN c1.id, c2.id, count(*) AS freq
ORDER BY freq DESC;
找出總共有多少用戶共享身分資訊
MATCH (c1:Client)-[:HAS_EMAIL|:HAS_PHONE|:HAS_SSN]-> (n) <-[:HAS_EMAIL|:HAS_PHONE|:HAS_SSN]-(c2:Client)
WHERE id(c1) <> id(c2)
RETURN count(DISTINCT c1.id) AS freq;
針對有共享個資的用戶,將共享的雙方建立新的關聯 SHARED_IDENTIFIERS,並賦予屬性 count,表示共享的個資總數
MATCH (c1:Client)-[:HAS_EMAIL|:HAS_PHONE|:HAS_SSN] -> (n) <- [:HAS_EMAIL|:HAS_PHONE|:HAS_SSN]-(c2:Client)
WHERE id(c1) < id(c2)
WITH c1, c2, count(*) as cnt
MERGE (c1) - [:SHARED_IDENTIFIERS {count: cnt}] -> (c2);
建立關聯後,重新用圖形顯示出至少共享兩項個資的用戶群
MATCH p = (:Client) - [s:SHARED_IDENTIFIERS] -> (:Client) WHERE s.count >= 2 RETURN p;
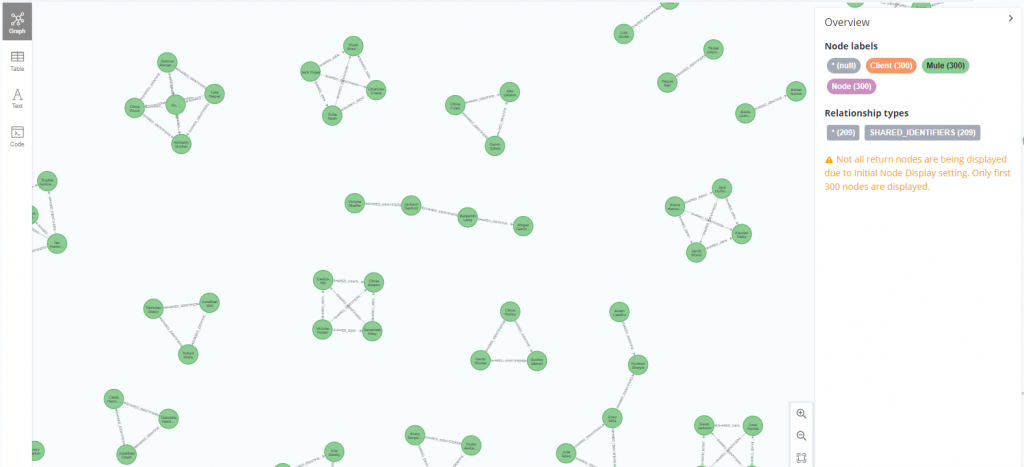
到目前為止,都只是在深入分析資料前的簡單探索,對眼前的資料有多一點概念與理解,還不能直接做出任何判斷與識別。接下來就用 Neo4j GDS 演算法,從各個層面去逐步抽絲剝繭,找出最有可能是第一方詐欺的客戶。
首先用 WCC 演算法 (Weakly Connected Components) 來做群聚分析,找到所有共享個資的用戶,並將其分群。
然後因為是千萬級別的資料量,所以在建立 Projection graph 或使用演算法之前,我會很常先估算記憶體用量如下,後續文章會省略不提。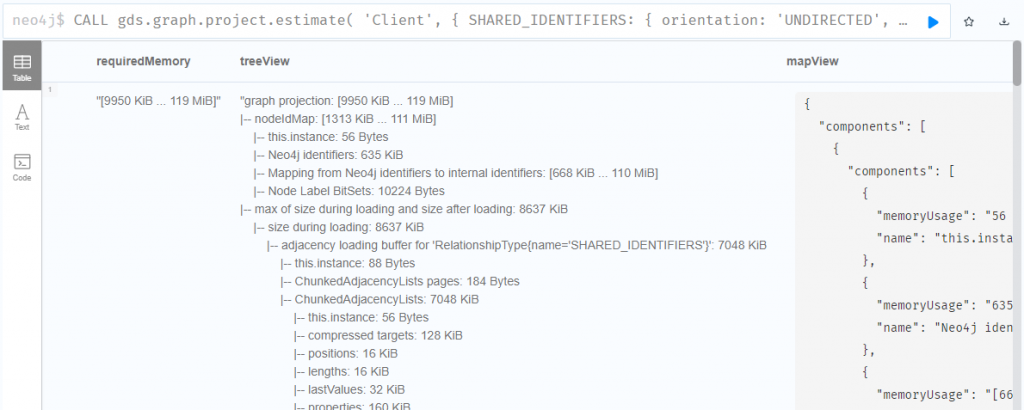
建立 WCC 算法要用的 Projection graph,將全部用戶以及 SHARED_IDENTIFIERS 關聯都放到記憶體圖中,並把關聯改為無向性。官方給的語法我稍嫌囉嗦,所以簡化如下
CALL gds.graph.project('wcc',
'Client',
{
SHARED_IDENTIFIERS: {
orientation: 'UNDIRECTED',
properties: 'count'
}
}
) YIELD graphName,nodeCount,relationshipCount,projectMillis;
先跑一次 stream 模式查看分群結果,如圖,相同的 componentId 表示被分到同一群,而同一群代表用戶彼此之間或多或少有共用一些個資。
CALL gds.wcc.stream('wcc',
{
nodeLabels: ['Client'],
relationshipTypes: ['SHARED_IDENTIFIERS'],
consecutiveIds: true // 讓 componentId 連號
}
)
YIELD nodeId, componentId
RETURN gds.util.asNode(nodeId).id AS clientId, componentId
ORDER BY componentId;
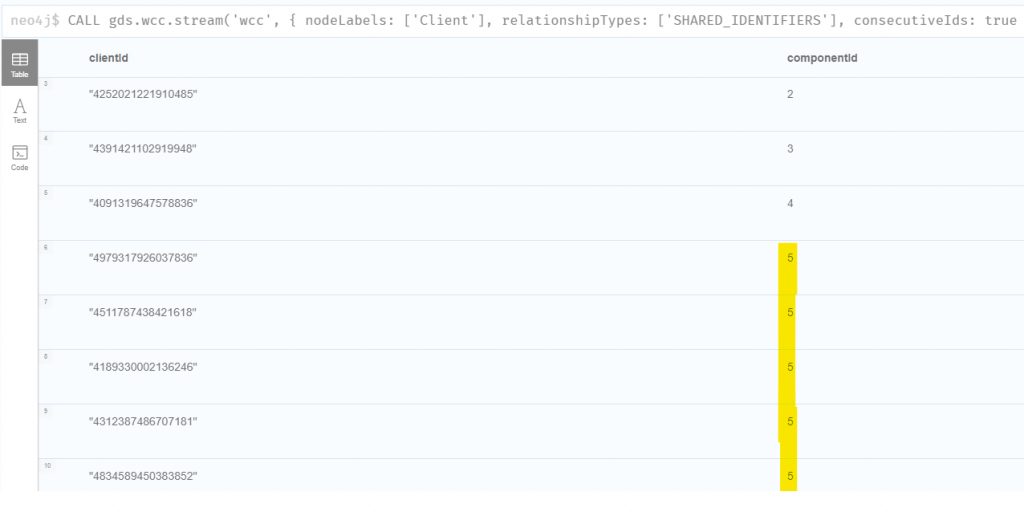
在官方教學文件中,WCC 的演算過程有加上 consecutiveIds: true 設定,這是讓最後輸出的 componentId 可以連號,因為 Component 在不斷的合併過程中,就會產生跳號。不過這個設定在這次的練習沒有實際用途,而且會耗用更多記憶體,不建議使用。
WCC 演算法還額外提供了 weight 和 threshold 的設定,以下便是限定 SHARED_IDENTIFIERS 的 count 屬性必須大於 1,才會被 WCC 算法視為兩個節點可有效連通。
意義上就是說,兩個用戶彼此間至少有兩項個資共用,其 SHARED_IDENTIFIERS 關聯才視為有效。
CALL gds.wcc.stream('wcc',
{
nodeLabels: ['Client'],
relationshipTypes: ['SHARED_IDENTIFIERS'],
consecutiveIds: true,
relationshipWeightProperty: 'count',
threshold: 1.0
}
)
最後,我們將 WCC 演算法的分群結果,也就是 componentId,判斷 Component 有兩個客戶或以上時,將 componentId 寫回 firstPartyFraudGroupId 屬性,至此完成第一方詐欺分群。同一群內的所有人,彼此間一定有直接或間接共用 Email、Phone、SSN。
Component 內如果只有一個客戶,表示他沒有和任何人共用個資。
CALL gds.wcc.stream('wcc',
{
nodeLabels: ['Client'],
relationshipTypes: ['SHARED_IDENTIFIERS']
}
)
YIELD componentId as groupId, nodeId
WITH groupId, gds.util.asNode(nodeId) AS client
WITH groupId, collect(client) AS clients
WITH groupId, clients, size(clients) AS groupSize WHERE groupSize > 1
UNWIND clients AS client
MATCH (c:Client) WHERE c.id = client.id
SET c.firstPartyFraudGroupId = groupId;
這邊因為有刻意過濾出集群數量大於 1,也就是彼此有共享個資的群體,才寫入 firstPartyFraudGroupId 屬性,如果想要不管群體大小,一律寫入新的屬性,那麼簡單用 write 模式即可解決。
CALL gds.wcc.stream('wcc',
{
nodeLabels: ['Client'],
relationshipTypes: ['SHARED_IDENTIFIERS'],
writeProperty: 'firstPartyFraudGroupId' }
}
)
最後將第一方詐欺分群內,比較密集的群組先找出來調查,以便縮小調查範圍,這邊以 6 個客戶以上的群體為例。(圖形中有很多群體不到六個客戶,純粹只是因為回傳數量大,被 Neo4j 限制了)
接著可以逐步提高數字來優先調查更大的群體。
MATCH (c:Client)
WITH c.firstPartyFraudGroupId AS groupId, collect(c.id) AS group
WITH *, size(group) AS groupSize WHERE groupSize >= 6
WITH collect(groupId) AS fraudRings
MATCH p = (c:Client)-[:HAS_SSN|HAS_EMAIL|HAS_PHONE]->() WHERE c.firstPartyFraudGroupId IN fraudRings
RETURN p
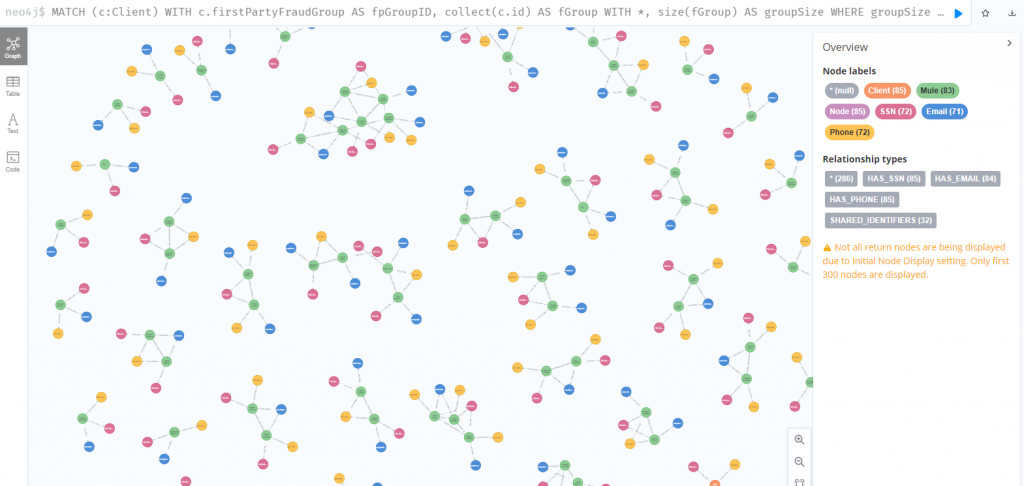
從這個圖可以看到有些個資被許多客戶重複使用。以此為出發點,試著找出相似度高的客戶群,共用愈多個資,相似度就愈高。
如之前文章介紹到 Node similarity 演算法,使用 Jaccard similarity 來計算相似度,而 Jaccard 會使用到二分圖,在目前的案例中,二分圖的第一群節點就是潛在的第一方詐欺客戶群,第二群節點就是個資群,我們要用個資群來計算客戶群彼此間的相似度分數。
先用 Projection graph 建立二分圖如下
MATCH (c:Client) WHERE c.firstPartyFraudGroupId is not NULL // 第一群節點,初步懷疑為第一方詐欺
WITH collect(c) as clients
MATCH (n) WHERE n:Email OR n:Phone OR n:SSN // 第二群節點為所有個資,用來輔助判斷第一群節點間的相似度
WITH clients, collect(n) as identifiers
WITH clients + identifiers as nodes
MATCH (c:Client) -[:HAS_EMAIL|:HAS_PHONE|:HAS_SSN]->(id)
WHERE c.firstPartyFraudGroupId is not NULL
// 收集所有第一方詐欺、所有個資、以及所有關聯,準備建立 Cypher projection graph
WITH nodes, collect({source: c, target: id}) as relationships
// 以下可參考官方 Cypher projection 定義 https://neo4j.com/docs/graph-data-science/current/graph-project-cypher/
CALL gds.graph.project.cypher('similarity',
"UNWIND $nodes as n RETURN id(n) AS id, labels(n) AS labels",
"UNWIND $relationships as r RETURN id(r['source']) AS source, id(r['target']) AS target, 'HAS_IDENTIFIER' as type",
{ parameters: {nodes: nodes, relationships: relationships}}
)
YIELD graphName, nodeCount, relationshipCount, projectMillis
RETURN graphName, nodeCount, relationshipCount, projectMillis
藉由上面準備好的 projection graph,使用 nodeSimilarity 演算法計算用戶間的相似度,給予高低評分並建立新的關聯
CALL gds.nodeSimilarity.mutate('similarity',
{
topK:15, // 每個 Client 只找出相似度最高的 15 個 Client,數字愈高愈精確,但耗用更多記憶體,預設值是 10
mutateProperty: 'jaccardScore',
mutateRelationshipType:'SIMILAR_TO'
}
);
將記憶體中的關聯與分數寫回到資料庫,作為後續分析
CALL gds.graph.writeRelationship('similarity', 'SIMILAR_TO', 'jaccardScore');
接著用圖形表示出,在第一方詐欺 6 個客戶以上的大群體中,彼此有高度相似的客戶們
MATCH (c:Client)
WITH c.firstPartyFraudGroupId AS groupId, collect(c.id) AS group
WITH *, size(group) AS groupSize WHERE groupSize >= 6
WITH collect(groupId) AS fraudRings
MATCH p = (c:Client)-[r:SIMILAR_TO]->() WHERE c.firstPartyFraudGroupId IN fraudRings AND r.jaccardScore > 0.8
RETURN p
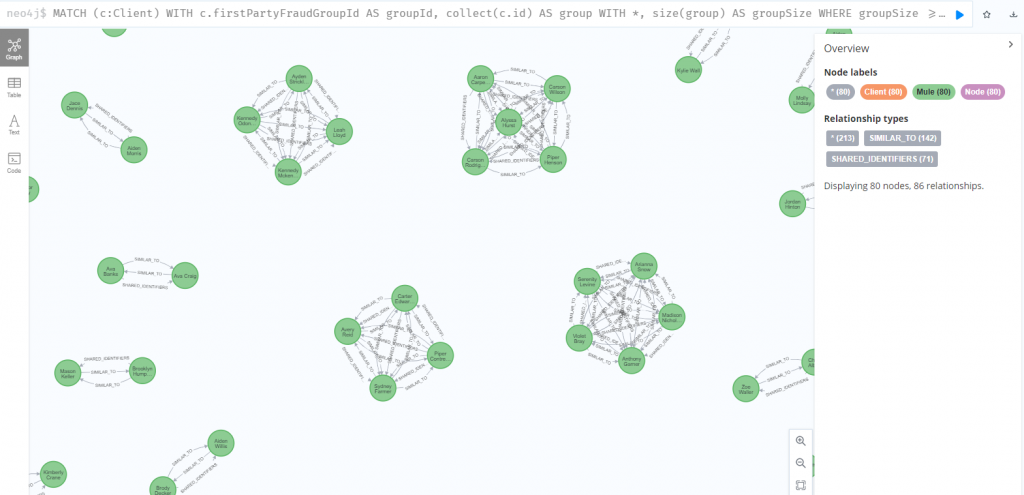
繼續縮小範圍,接下來加總每個客戶的 jaccardScore 分數,得出 firstPartyFraudScore,這個分數愈高,代表這個客戶和愈多人有相似性,愈有可能是第一方詐欺
CALL gds.degree.stream('similarity',
{
nodeLabels: ['Client'],
relationshipTypes: ['SIMILAR_TO'],
relationshipWeightProperty: 'jaccardScore'
}
)
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS name, score
ORDER BY score DESC
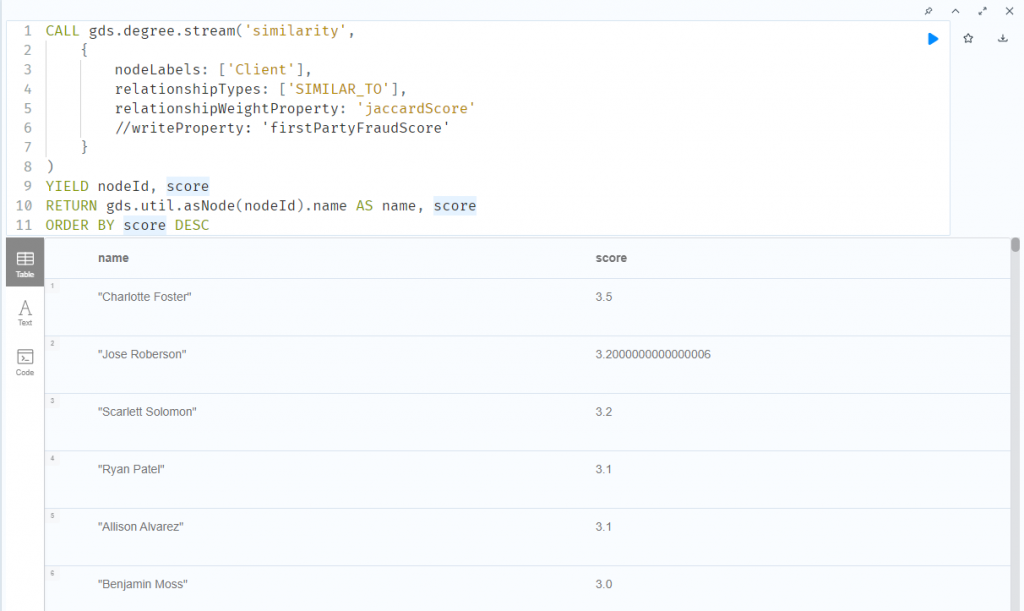
將加總分數寫回資料庫 firstPartyFraudScore 屬性
CALL gds.degree.write('similarity',
{
nodeLabels: ['Client'],
relationshipTypes: ['SIMILAR_TO'],
relationshipWeightProperty: 'jaccardScore',
writeProperty: 'firstPartyFraudScore'
}
);
計算出 firstPartyFraudScore 的第 95 百分位數,作為審查的臨界值,超過這個值,就直接標籤他為詐欺犯
MATCH(c:Client)
WHERE c.firstPartyFraudScore IS NOT NULL
WITH percentileCont(c.firstPartyFraudScore, 0.95) AS firstPartyFraudThreshold
MATCH(c:Client)
WHERE c.firstPartyFraudScore > firstPartyFraudThreshold
SET c:FirstPartyFraudster;
以上,到目前為止的步驟是,我們先識別出有共享個資的客戶們,並用 WCC 演算法將其分群,再用 Node similarity 找出共享很多個資因而高度相似的客戶,計算其相似度分數,最後再用 Weighted Degree Centrality,把這些分數加總,作為第一方詐欺總評分。
然後取評分最高的一定比例,直接標籤為第一方詐欺犯。
接下來我們要以第一方詐欺犯為基礎延伸出去,找出可能的第二方詐欺犯。
在接下來練習中,我想在 PaySim 資料集中檢測錢騾,也就是被犯罪分子招募來幫助洗錢。一個基本假設是,和第一方欺詐犯有資金往來的客戶,會是第二方欺詐的嫌疑人,所以要識別和探索第一方欺詐者與其他客戶間的交易,找出可能支持第一方欺詐者但未被確定為潛在第一方欺詐者的客戶。
先簡單看一下有哪些用戶和第一方詐欺犯有交易,從圖形可以初步看出,某些客戶和其他多位客戶有密集的交易,可能需要關注。
MATCH p = (:FirstPartyFraudster)-[]-(:Transaction)-[]-(c:Client)
WHERE NOT c:FirstPartyFraudster
RETURN p;
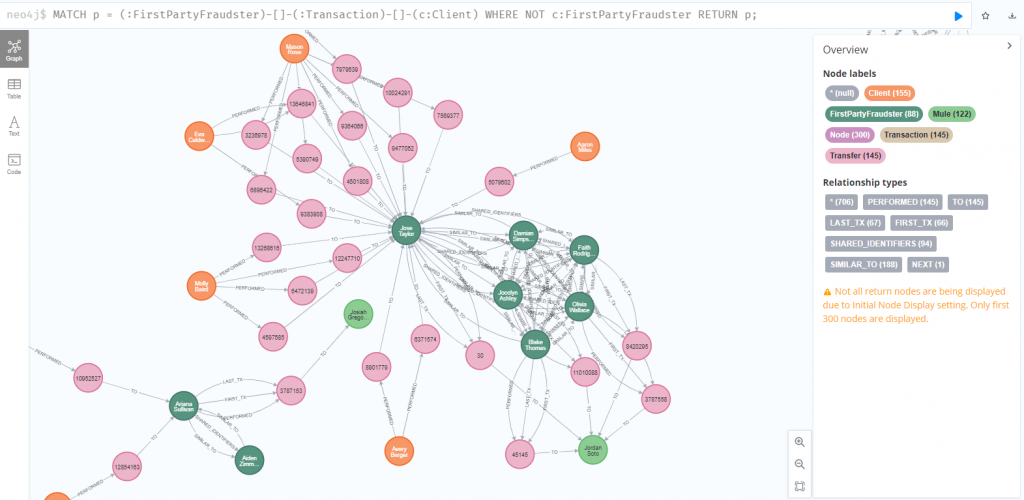
查看這些交易都是哪些類型,從查詢結果得知,全部都是用戶間的直接轉帳,果然符合錢驢的行為 XD
MATCH (:FirstPartyFraudster)-[]-(txn:Transaction)-[]-(c:Client)
WHERE NOT c:FirstPartyFraudster
UNWIND labels(txn) AS transactionType
RETURN transactionType, count(*) AS freq;
與第一方詐欺犯有交易的客戶,都先標籤為第二方詐欺嫌疑人,並建立新的關聯,紀錄轉出和轉入的交易總額,方便後續先針對大量交易做調查。
MATCH (c1:FirstPartyFraudster)-[]->(t:Transaction)-[]->(c2:Client)
WHERE NOT c2:FirstPartyFraudster
WITH c1, c2, sum(t.amount) AS totalAmount
SET c2:SecondPartyFraudSuspect
CREATE (c1)-[:TRANSFER_TO {amount:totalAmount}]->(c2);
為了將第二方詐欺分群,再次使用 WCC 演算法,並將焦點放在比較大的第二方詐欺群體。
這次改用轉帳交易的關係來分群,用 TRANSFER_TO 關聯建立新的 Projection graph,並將交易總額也寫入記憶體,方便後續過濾大宗交易。
CALL gds.graph.project('SecondPartyFraudNetwork',
'Client',
'TRANSFER_TO',
{relationshipProperties:'amount'}
);
使用 WCC 演算法分群後,設定這些客戶們的第二方詐欺群組 id
CALL gds.wcc.stream('SecondPartyFraudNetwork')
YIELD nodeId, componentId as groupId
WITH gds.util.asNode(nodeId) AS client, groupId
WITH groupId, collect(client) AS group
WITH groupId, size(group) AS groupSize, group
WHERE groupSize > 1
UNWIND group AS client
MATCH (c:Client {id:client.id})
SET c.secondPartyFraudGroupId = groupId;
重新用圖形化表示,找出比較大的第二方詐騙集團
CALL gds.wcc.stream('SecondPartyFraudNetwork')
YIELD nodeId, componentId as groupId
WITH groupId, collect(nodeId) AS group
WITH groupId, size(group) AS groupSize
WHERE groupSize > 5
MATCH p = (:FirstPartyFraudster)-[:TRANSFER_TO]-(c:Client)
WHERE NOT c:FirstPartyFraudster AND c.secondPartyFraudGroupId = groupId
RETURN p;
使用 PageRank 演算法,根據轉帳總額排名並給予分數,分數高者直接加上第二方詐欺的標籤。
CALL gds.pageRank.stream('SecondPartyFraudNetwork', {
relationshipWeightProperty:'amount'
}) YIELD nodeId, score
WITH gds.util.asNode(nodeId) AS client, score AS pageRankScore
WHERE client.secondPartyFraudGroupId IS NOT NULL AND
pageRankScore > 0.6 AND
NOT client:FirstPartyFraudster
MATCH(c:Client {id:client.id})
SET c:SecondPartyFraud
SET c.secondPartyFraudScore = pageRankScore;
以上,我們用演算法,從多個角度逐步把最有可能的第一方詐欺群體找出後,再把與第一方詐欺犯有交易的客戶,且重要性高(總金額達到一定比例),直接標籤為錢驢。
國外知名大廠如 eBay, Adobe, IBM, volvo, NASA, Cisco, HP, Airbnb, Microsoft,都是 Neo4j 的客戶,其中跟金融詐欺檢測有關的案例是 ICIJ巴拿馬文件 ;至於國內,就我所知已有台灣金控龍頭採用 Neo4j,是由日新科技協助導入。
國內越來越多金融業開始評估 Neo4j,除了最受歡迎的詐欺檢測之外,對於營銷、風控、智能客服優化以及產品預測也是非常適合的應用。
https://www.sisu.io/posts/paysim
https://www.sisu.io/posts/paysim-part2
https://www.bnc-technology.com/neo4j.html
https://www.experian.co.uk/blogs/latest-thinking/fraud-prevention/what-is-first-second-and-third-party-fraud/
https://neo4j.com/use-cases/fraud-detection/
https://www.tpisoftware.com/tpu/articleDetails/2651
 蛋踢球
蛋踢球
