BeautifulSoup是一個用來解析HTML結構的Python函式庫,能夠輕鬆的從HTML或XML檔案中分析資料,因此在爬蟲應用中是很常見的。今天就來開發一個簡單的爬蟲,來爬「ETtoday美食雲」網頁上的資料。
BeautifulSoup套件可以透過pip指令來進行安裝,不過就像之前安裝requests函式庫一樣,我會利用PyCharm的圖形化介面來進行安裝~
搜尋到想要的函式庫就直接點選install Package就好啦,安裝好後底下會出現一排綠色的表示已經安裝成功了。今天這個爬蟲也會需要用到requests函式庫,所以一樣要記得先安裝好,方法也是一樣的!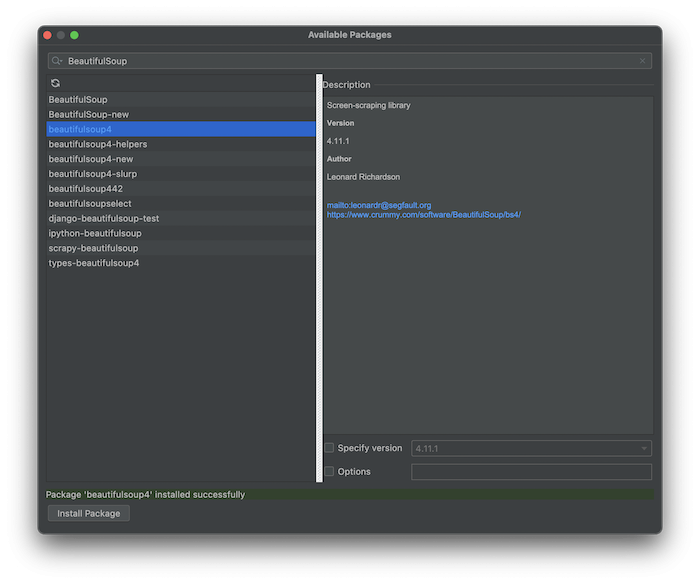
安裝完成後就可以正式開始爬蟲惹。最一開始當然要先把需要的函式庫都import進去。
import requests
from bs4 import BeautifulSoup
使用requests中的get()方法存取網頁的html程式碼,接著用BeautifulSoup將取得的HTML結構字串傳回來
url = "https://www.ettoday.net/feature/et_yummy?from=ettoday-pc-sidemenu"
response = requests.get(url)
html = BeautifulSoup(response.text, "html.parser")
print(html) # 輸出網頁的html程式碼
我擷取了一小段輸出結果。
<div class="box_0 clearfix">
<a class="pic" href="//www.ettoday.net/news/20220910/2332259.htm" target="_blank"><img src="//cdn2.ettoday.net/images/6552/c6552807.jpg"/></a>
<h2><a href="//www.ettoday.net/news/20220910/2332259.htm" target="_blank">被誤以為是廢墟!三重傳說級古早「茶冰沙」 炭焙茶香回甘不苦澀</a></h2>
<p class="summary">網友打卡瘋傳的隱藏版三重紅茶冰,外觀像是廢墟飲料店,位於新北市三重區中正南路上,近捷運菜寮站,超人氣排隊飲料名店,主打好茶、好糖、好水、好冰。必點紅茶、無憂紅茶、隨便奶一點,這裡的茶是冰沙,黃金比例最好喝,茶香回甘,不苦澀,奶香厚實濃郁,比許多客製化手搖飲料店更厲害!<a class="more" href="//www.ettoday.net/news/20220910/2332259.htm" target="_blank">詳全文>></a></p>
</div>
現在html物件已經包含了整個網頁的HTML程式碼,接下來就可以利用BeautifulSoup裡的方法,來進行節點的搜尋。
想要爬取標題文字首先你要知道標題會在HTML程式碼中的什麼位子,你可以從剛剛輸出過的程式碼中慢慢找,又或者我教你一個更快的方法。首先打開網頁後用F12看背後的程式碼,點選左上有一個箭頭的標誌。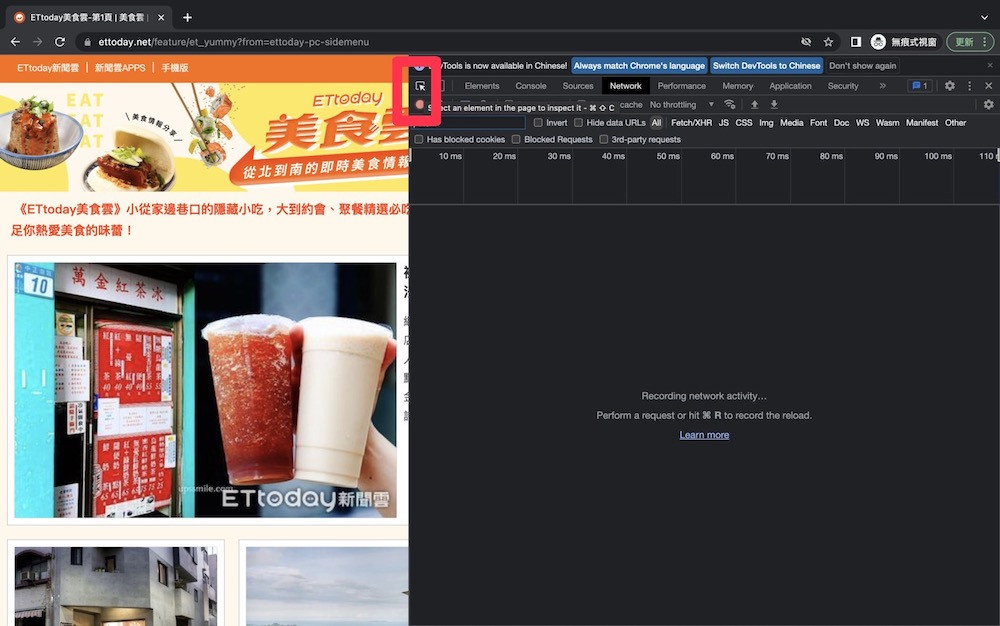
接著點標題的地方。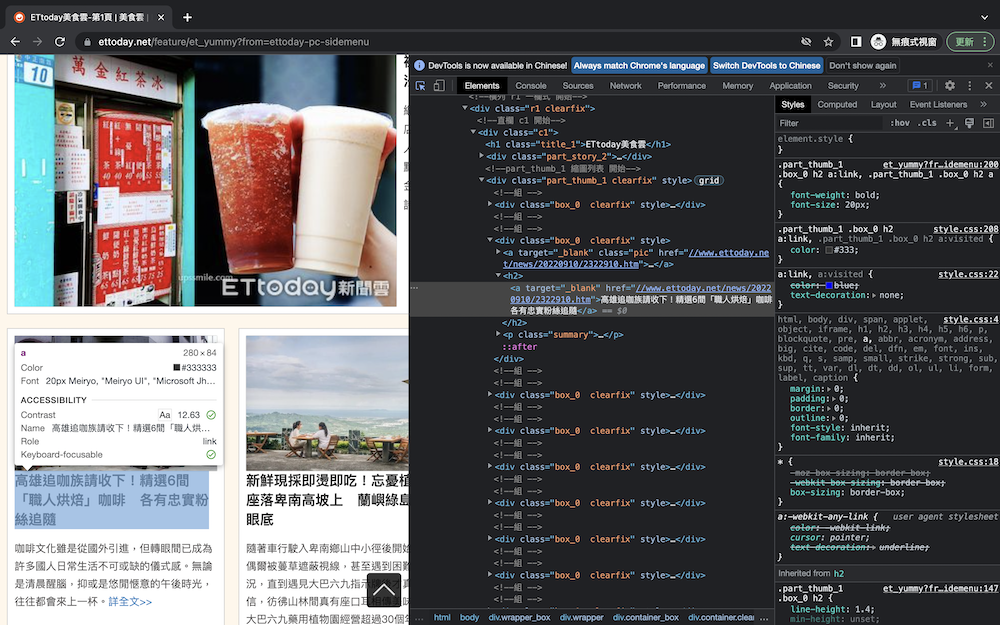
就可以直接知道標題的部分是用包住的,接著再搜尋所有h2的部分最後列印出其中的文字。
titles = html.find_all("h2") # 搜尋所有h2
for title in titles:
print(title.getText()) # 只提取文字部分
剛取標題文字差不多,標題文字和連結都是用包住的,只要先搜尋所有h2的部分,剛好標籤底下只有一個標籤,所以可以用select_one()方法來選取,最後再利用get()方法取得有"href"的部分,這樣就完成啦~
titles = html.find_all("h2") # 搜尋所有h2
for title in titles:
print(title.select_one("a").get("href")) # 只提取超連結部分


 iThome鐵人賽
iThome鐵人賽