有個更有效率的方式是去找別人已經訓練好的模型,然後調整後再用自己的目標的應用資料再訓練,這稱為所謂的"transfer learning"。
這邊我們使用"InceptionV3",這可以直接從keras裡面拿出來用,另外可以載入自己想要的權重參數,並設定不給train:
from tensorflow.keras.applications.inception_v3 import InceptionV3
from tensorflow.keras import layers
# Set the weights file you downloaded into a variable
local_weights_file = './inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5'
# Initialize the base model.
# Set the input shape and remove the dense layers.
pre_trained_model = InceptionV3(input_shape = (150, 150, 3),
include_top = False,
weights = None)
#Set the input shape to fit your application. In this case. set it to 150x150x3.
#Pick and freeze the convolution layers to take advantage of the features it has learned already.
#Add dense layers which you will train.
# Load the pre-trained weights you downloaded.
pre_trained_model.load_weights(local_weights_file)
# Freeze the weights of the layers.
for layer in pre_trained_model.layers:
layer.trainable = False
我們把它切出想要的部分,例如到"mixed7"這層,後面銜接到我們原本設計的model:
# Choose `mixed_7` as the last layer of your base model
last_layer = pre_trained_model.get_layer('mixed7')
print('last layer output shape: ', last_layer.output_shape)
last_output = last_layer.output
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras import Model
# Flatten the output layer to 1 dimension
x = layers.Flatten()(last_output)
# Add a fully connected layer with 1,024 hidden units and ReLU activation
x = layers.Dense(1024, activation='relu')(x)
# Add a dropout rate of 0.2
x = layers.Dropout(0.2)(x)
# Add a final sigmoid layer for classification
x = layers.Dense (1, activation='sigmoid')(x)
# Append the dense network to the base model
model = Model(pre_trained_model.input, x)
其中特別的是增加了"layers.Dropout(0.2)(x)"這層,所謂dropout大家可以參考Andrew Ng的教學課程影片以及這篇文章,簡單說是在這邊是用來處理overfitting的方式。
可以同樣用summary秀出,但非常的多,若只在console上看只能看到最後的一部分,所以下面節錄最後從mixed7銜接以及增加的部分:
mixed7 (Concatenate) (None, 7, 7, 768) 0 ['activation_530[0][0]','activation_533[0][0]','activation_538[0][0]','activation_539[0][0]']
flatten_14 (Flatten) (None, 37632) 0 ['mixed7[0][0]']
dense_28 (Dense) (None, 1024) 38536192 ['flatten_14[0][0]']
dropout_3 (Dropout) (None, 1024) 0 ['dense_28[0][0]']
dense_29 (Dense) (None, 1) 1025 ['dropout_3[0][0]']
================================================================================================
Total params: 47,512,481
Trainable params: 38,537,217
Non-trainable params: 8,975,264
然後我們畫出訓練和測試的accuracy,可以看到大幅度的改善: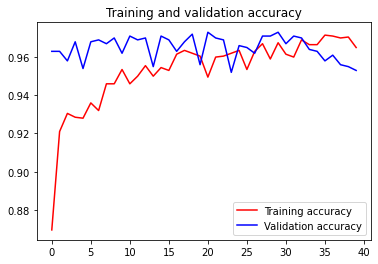
但相對的訓練時間約為原本的8倍左右QQ
此外也可以站在其他巨人的肩膀,例如再TensorFlow的教學範例是用"MobileNetV2",其做法也類似前面的範例,大家也可以試試用不同人的肩膀以及切到不同層的效果。


 iThome鐵人賽
iThome鐵人賽