前面的圖像辨識的練習,都是在二分的歸類,但真實的世界是多元的,所以最後的一片拼圖,就是多項目的分類。這邊的範例是剪刀石頭布三種手型的分類,而三種、跟十種、或多種是同理相通。
而如同之前的範例,要修改的部分只有3個地方:在model的最後一層dense的activation='softmax',在compile的loss = 'categorical_crossentropy',以及 ImageDataGenerator的 flow_from_directory中class_mode='categorical',這些都是很明顯因為現在是多個分類。完整範例code如下:
import tensorflow as tf
model = tf.keras.models.Sequential([
# Note the input shape is the desired size of the image 150x150 with 3 bytes color
# This is the first convolution
tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
# The second convolution
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# The third convolution
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# The fourth convolution
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# Flatten the results to feed into a DNN
tf.keras.layers.Flatten(),
tf.keras.layers.Dropout(0.5),
# 512 neuron hidden layer
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
])
# Set the training parameters
model.compile(loss = 'categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen_aug = ImageDataGenerator(
rescale = 1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
datagen = ImageDataGenerator(rescale = 1./255)
train_generator_aug = datagen_aug.flow_from_directory(
TRAINING_DIR,
target_size=(150,150),
class_mode='categorical',
batch_size=126)
validation_generator = datagen.flow_from_directory(
VALIDATION_DIR,
target_size=(150,150),
class_mode='categorical',
batch_size=126)
# Train the model
history = model.fit(train_generator_aug,
epochs=25,
steps_per_epoch=20,
validation_data = validation_generator,
verbose = 1,
validation_steps=3)
訓練的accuracy和loss如下圖: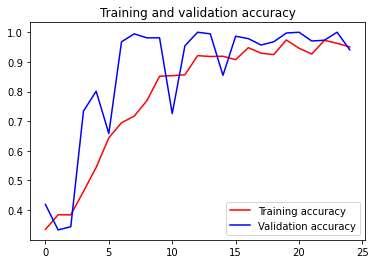
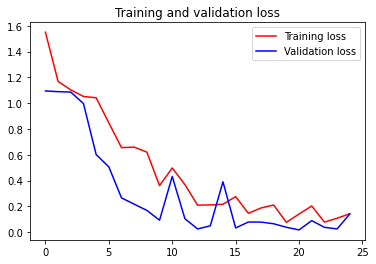
在25次epoch後loss已經低於0.15而accuracy也高於0.94,這是由於訓練和測試的圖庫都是CGI電腦生成的,而且背景非常乾淨:


 iThome鐵人賽
iThome鐵人賽