今天要介紹的是許多機器學習模型的基礎概念----馬可夫鏈(Markov Chain)。馬可夫鏈在數學中有著廣泛的用途,包括經濟學、博弈論、傳播理論、遺傳學和金融學,甚至在語言學這樣看似與數字無關的領域也會使用到它。統計學中,尤其是貝葉斯統計以及資訊理論中也常出現馬可夫模型的身影。
馬可夫鍊是具有馬可夫性質(Markov Property)的隨機過程。所謂馬可夫性質就是當一個隨機過程在給定現在狀態及所有過去狀態情況下,其未來狀態的條件機率分布僅依賴於當前狀態;換句話說,在給定現在狀態時,它與過去狀態(即該過程的歷史路徑)是條件獨立的,那麼此隨機過程即具有馬可夫性質。再更簡單明瞭的說就是在記錄一件事情時,若時間與狀態都是離散的隨機過程,就稱為 Markov Chain。Markov Chain 是隨機變數 X0,X1,X2,X3,... ,也就是 Xn,n>=0 的一個數列,其中 X0,X1,...Xn−1 都是過去時間的狀態, Xn 是目前的狀態, Xn+1,Xn+2,... 是未來的狀態,每一個狀態可轉移到其他狀態,轉移的機率總和為 1,因此移動到下一個狀態的機率僅取決於當前狀態而不取決於先前狀態。
討論 Markove Chain 的時候必須要記住 2 點:
這樣的概念可以產生以下的公式:
可以看到,Xn+1 的機率僅取決於它之前的 Xn 的機率。表示了解前一個狀態的內容是確定當前狀態機率分佈所必需的,也就是說你只需要知道當前狀態就可以確定下一個狀態(無記憶性,系統不需要記錄前面經過的狀態,只需要目前的狀態,就可以預測下一個狀態)。
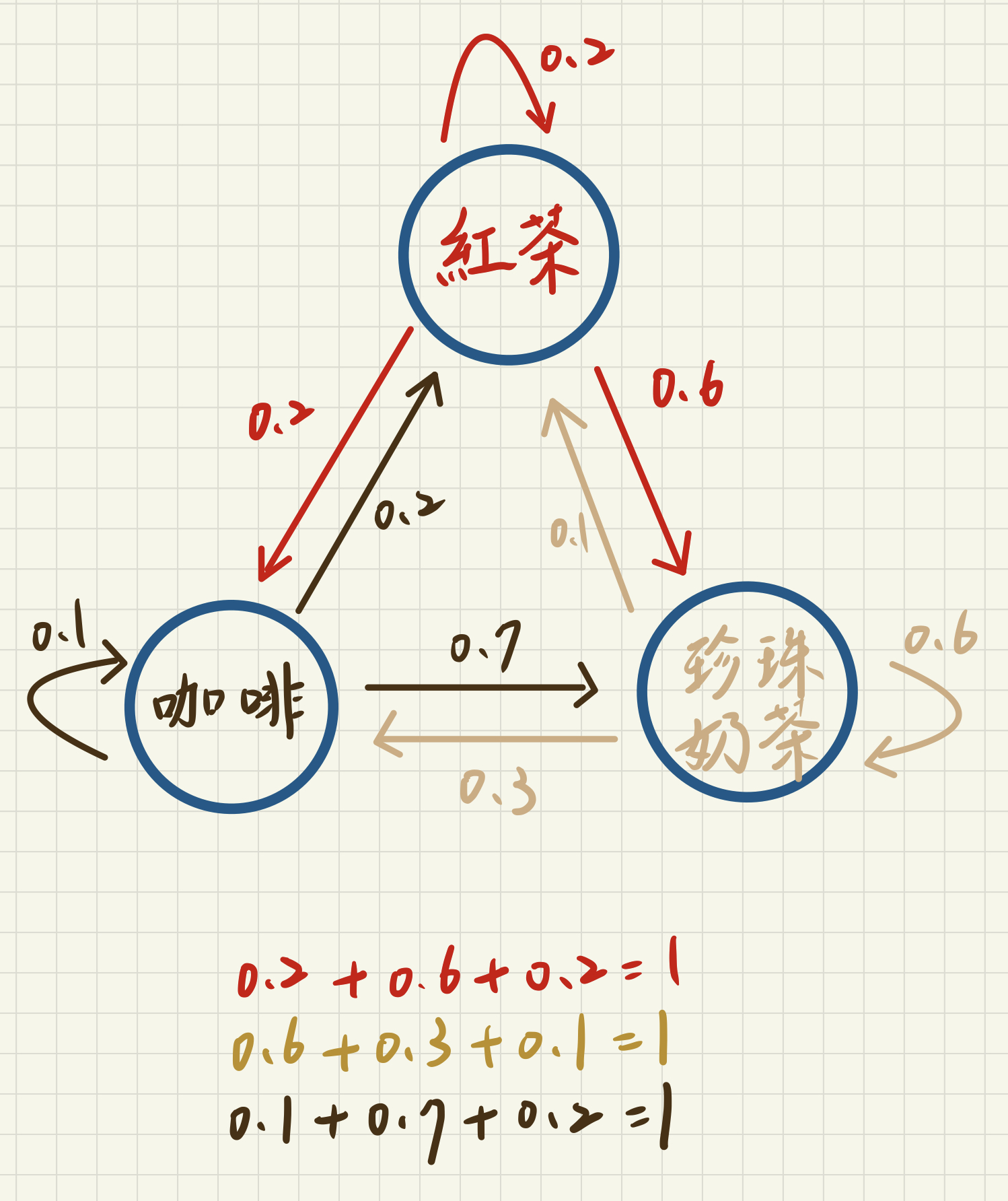
Markov Chain 以下圖為表示方式:
以上圖為例,假設小美很喜歡喝飲料,她每天一定都要買一杯飲料來喝,她喜歡的飲料有紅茶、珍珠奶茶和咖啡。
記錄顯示,若小美前一天放學已經喝過紅茶了,那麼她今天放學再次喝紅茶的機率是 0.2,喝珍珠奶茶的機率是 0.6,喝咖啡的機率是 0.2。
若小美前一天放學已經喝過珍珠奶茶了,那麼她今天放學再次喝珍珠奶茶的機率是 0.6,喝紅茶的機率是 0.1,喝咖啡的機率是 0.3。
若小美前一天放學已經喝過咖啡了,那麼她今天放學再次喝咖啡的機率是 0.1,喝紅茶的機率是 0.2,喝珍珠奶茶的機率是 0.7。
記得每一個狀態的機率總和要為 1。
有了這樣的機率就可以計算出 Markov Chain 了!只要選定某一個狀態為起點,根據轉移矩陣改變狀態,當狀態不斷地改變,會產生一個狀態變化的路徑。如考慮所有的狀況,可計算出每一個路徑的發生機率,這些路徑就稱為 Markov Chain。
了解了 Markov Chain 是什麼了之後,我們就用上述的例子簡單實作一下吧!
import numpy as np
import random as rm
# 狀態
states = ["Black_tea","Bubble_tea","Coffee"]
# 可能的路徑
transitionName = [["BB","BT","BC"],["TB","TT","TC"],["CB","CT","CC"]]
# 轉換矩陣
transitionMatrix = [[0.2,0.6,0.2],[0.1,0.6,0.3],[0.2,0.7,0.1]]
# 確認一下機率、轉換矩陣是否設定正確
if sum(transitionMatrix[0])+sum(transitionMatrix[1])+sum(transitionMatrix[1]) != 3:
print("是不是機率計算錯了呢?")
else: print("沒問題,繼續下一步吧!")
# 實現馬爾可夫模型以預測狀態
def activity_forecast(days):
# 這邊可以更改起始的 state
activityToday = "Black_tea"
print("Start state: " + activityToday)
activityList = [activityToday]
i = 0
# To calculate the probability of the activityList
prob = 1
while i != days:
if activityToday == "Black_tea":
change = np.random.choice(transitionName[0],replace=True,p=transitionMatrix[0])
if change == "BB":
prob = prob * 0.2
activityList.append("Black_tea")
pass
elif change == "BT":
prob = prob * 0.6
activityToday = "Bubble_tea"
activityList.append("Bubble_tea")
else:
prob = prob * 0.2
activityToday = "Coffee"
activityList.append("Coffee")
elif activityToday == "Bubble_tea":
change = np.random.choice(transitionName[1],replace=True,p=transitionMatrix[1])
if change == "TT":
prob = prob * 0.6
activityList.append("Bubble_tea")
pass
elif change == "TB":
prob = prob * 0.1
activityToday = "Black_tea"
activityList.append("Black_tea")
else:
prob = prob * 0.3
activityToday = "Coffee"
activityList.append("Coffee")
elif activityToday == "Coffee":
change = np.random.choice(transitionName[2],replace=True,p=transitionMatrix[2])
if change == "CC":
prob = prob * 0.1
activityList.append("Coffee")
pass
elif change == "CB":
prob = prob * 0.2
activityToday = "Black_tea"
activityList.append("Black_tea")
else:
prob = prob * 0.7
activityToday = "Bubble_tea"
activityList.append("Bubble_tea")
i += 1
print("Possible states: " + str(activityList))
print("End state after "+ str(days) + " days: " + activityToday)
print("Probability of the possible sequence of states: " + str(prob))
# 預測 5 天後的 state
activity_forecast(5)
執行結果為:
Start state: Black_tea
Possible states: ['Black_tea', 'Coffee', 'Bubble_tea', 'Coffee', 'Bubble_tea', 'Coffee']
End state after 5 days: Coffee
Probability of the possible sequence of states: 0.008819999999999998
上面的方式會得到一組從狀態:Black_tea 開始可能的隨機轉換以及它發生的機率。讓我們進一步擴展,寫個 loop 讓其在某個起始狀態下進行數百次迭代,然後獲得在某個特定結束狀態下的預期機率。
def activity_forecast(days):
# 這邊可以更改起始狀態
activityToday = "Black_tea"
activityList = [activityToday]
i = 0
prob = 1
while i != days:
if activityToday == "Black_tea":
change = np.random.choice(transitionName[0],replace=True,p=transitionMatrix[0])
if change == "BB":
prob = prob * 0.2
activityList.append("Black_tea")
pass
elif change == "BT":
prob = prob * 0.6
activityToday = "Bubble_tea"
activityList.append("Bubble_tea")
else:
prob = prob * 0.2
activityToday = "Coffee"
activityList.append("Coffee")
elif activityToday == "Bubble_tea":
change = np.random.choice(transitionName[1],replace=True,p=transitionMatrix[1])
if change == "TT":
prob = prob * 0.6
activityList.append("Bubble_tea")
pass
elif change == "TB":
prob = prob * 0.1
activityToday = "Black_tea"
activityList.append("Black_tea")
else:
prob = prob * 0.3
activityToday = "Coffee"
activityList.append("Coffee")
elif activityToday == "Coffee":
change = np.random.choice(transitionName[2],replace=True,p=transitionMatrix[2])
if change == "CC":
prob = prob * 0.1
activityList.append("Coffee")
pass
elif change == "CB":
prob = prob * 0.2
activityToday = "Black_tea"
activityList.append("Black_tea")
else:
prob = prob * 0.7
activityToday = "Bubble_tea"
activityList.append("Bubble_tea")
i += 1
return activityList
# 儲存每個 activityList
list_activity = []
count = 0
for iterations in range(1,10000):
list_activity.append(activity_forecast(5)) # 5 天後
# Check out all the `activityList` we collected
#print(list_activity)
# 獲取以 state:'Bubble_tea' 結尾的所有活動的計數
for smaller_list in list_activity:
if(smaller_list[2] == "Bubble_tea"):
count += 1
# 計算從 state:'Black_tea' 開始到 state:'Bubble_tea' 結束的機率
percentage = (count/10000) * 100
print("The probability of starting at state:'Black_tea' and ending at state:'Bubble_tea'= " + str(percentage) + "%")
執行結果為:
The probability of starting at state:'Black_tea' and ending at state:'Bubble_tea'= 62.019999999999996%
今天就介紹到這邊~明天見!
code 參考自 (https://www.datacamp.com/tutorial/markov-chains-python-tutorial)


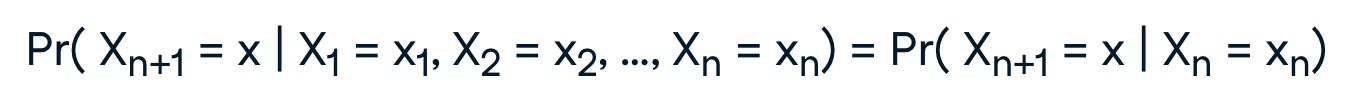
 iThome鐵人賽
iThome鐵人賽