在搜尋HTML網頁時,可以使用BeautifulSoup中的find()函數來找出指定的HTML 標籤。此函數傳回的值是”第一個”符合條件的HTML標籤,若沒有找到指定標籤會回傳None。
find()函數內可以使用四個參數,如下:
BeautifulSoap的find_all()函數可以搜尋HTML網頁找出”所有”符合條件的HTML標籤。
find_all()函數內可以使用五個參數,前四個參數和find()函數相同,如下:
使用標籤名稱搜尋HTML標籤:在FJU_website.html中找出標籤中的內容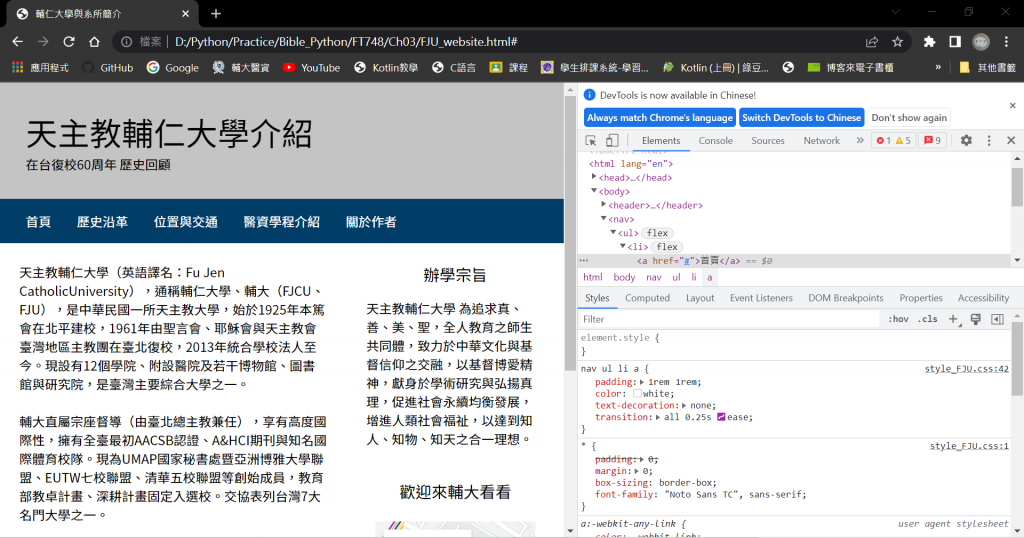
from bs4 import BeautifulSoup
with open("FJU_website.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
tag_a = soup.find("a") # 搜尋<a>標籤
print(tag_a.string)

搜尋HTML標籤的class屬性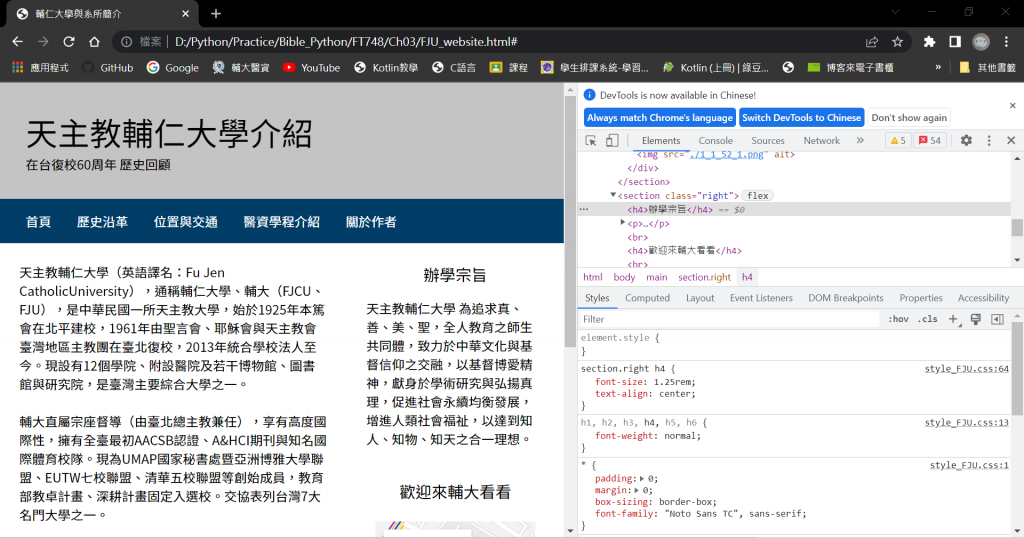
from bs4 import BeautifulSoup
with open("FJU_website.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
# 使用class屬性搜尋<li>標籤, 和之下的<span>標籤
tag_li = soup.find(attrs={"class": "right"})
tag_h4 = tag_li.find("h4")
print(tag_h4.string)

搜尋HTML標籤的文字內容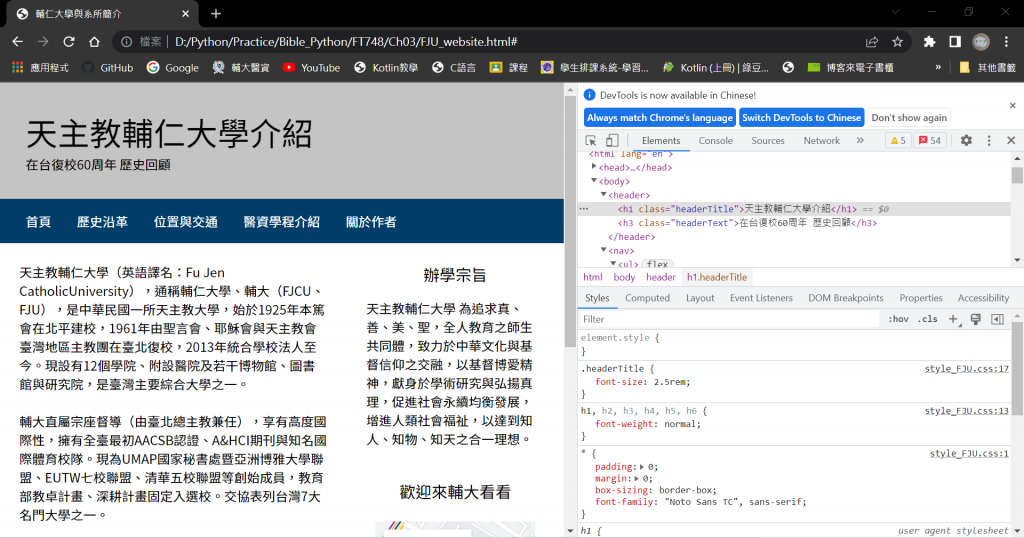
from bs4 import BeautifulSoup
with open("FJU_website.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
# 使用文字內容來搜尋標籤
tag_str = soup.find(text="天主教輔仁大學介紹")
print(tag_str)
tag_str = soup.find(text="在台復校60周年 歷史回顧")
print(tag_str)
print(type(tag_str)) # NavigableString型態
print(tag_str.parent.name) # 父標籤名稱

搜尋所有標籤:在FJU_website.html找出所有左半邊的標籤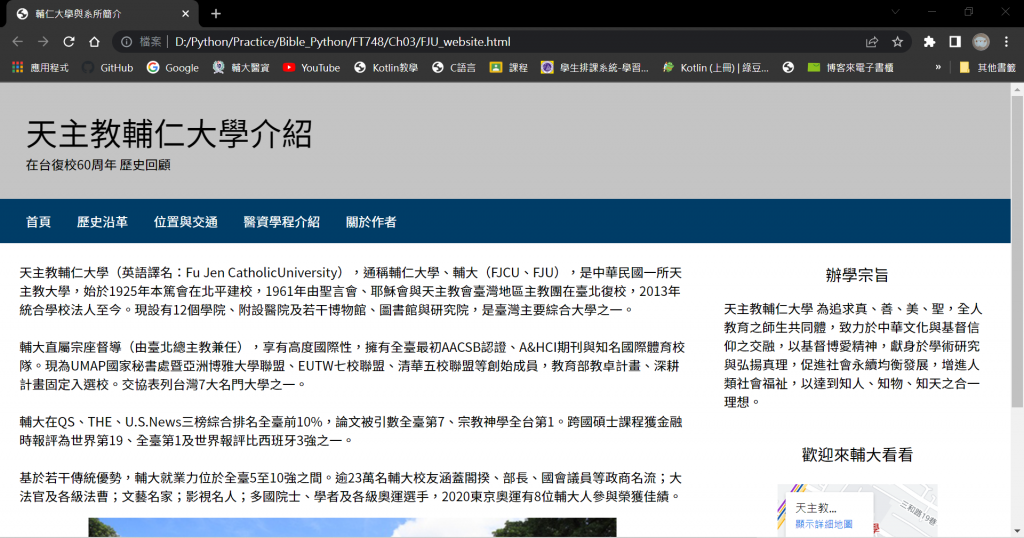
from bs4 import BeautifulSoup
with open("FJU_website.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
# 找出左半邊的文字內容
tag_list = soup.find_all("section", class_="left")
print(tag_list)
for left in tag_list:
print(left.p.string)



 iThome鐵人賽
iThome鐵人賽