閒聊
在昨天學習了BeautifulSoup套件後,今天來看看爬蟲究竟有分為哪些種類,以及它們之間的差別。
種類
通用網路爬蟲 General Purpose Web Crawler
又稱為「全網爬蟲」,爬蟲的資料主要來自於全網際網路。
這類爬蟲主要是蒐集每個網站的特色資訊,所以範圍、數據量龐大。
例如:Google、Yahoo、百度搜尋引擎。
聚焦網路爬蟲 Focused Crawler
又稱為「主題網路爬蟲」,主要依據需求選擇性爬取相關頁面,不會廣泛爬取。
增量式網路爬蟲 Incremental Web Crawler
主要是爬取新增網頁或是已更新網頁,這類爬蟲可以減少數據下載量,可以節省時間、空間。
但也需要比較複雜的演算法,設計執行上比較困難。
目前比較少實務應用。
深層網路爬蟲 Deep Web Crawler
顧名思義就是爬取深層的內容,一般可以爬取的網頁是表層的內容。
這類主要爬取內容無法從靜態URL,只有用戶提交表單時才能獲得的網路訊息(例如需要輸入帳號密碼)。
而且深層的內容理論上能獲取的資料量較大,因此會儘量爬取此頁面。
實際上:
搜尋引擎工作原理
也可以稱為通用網路爬蟲工作原理。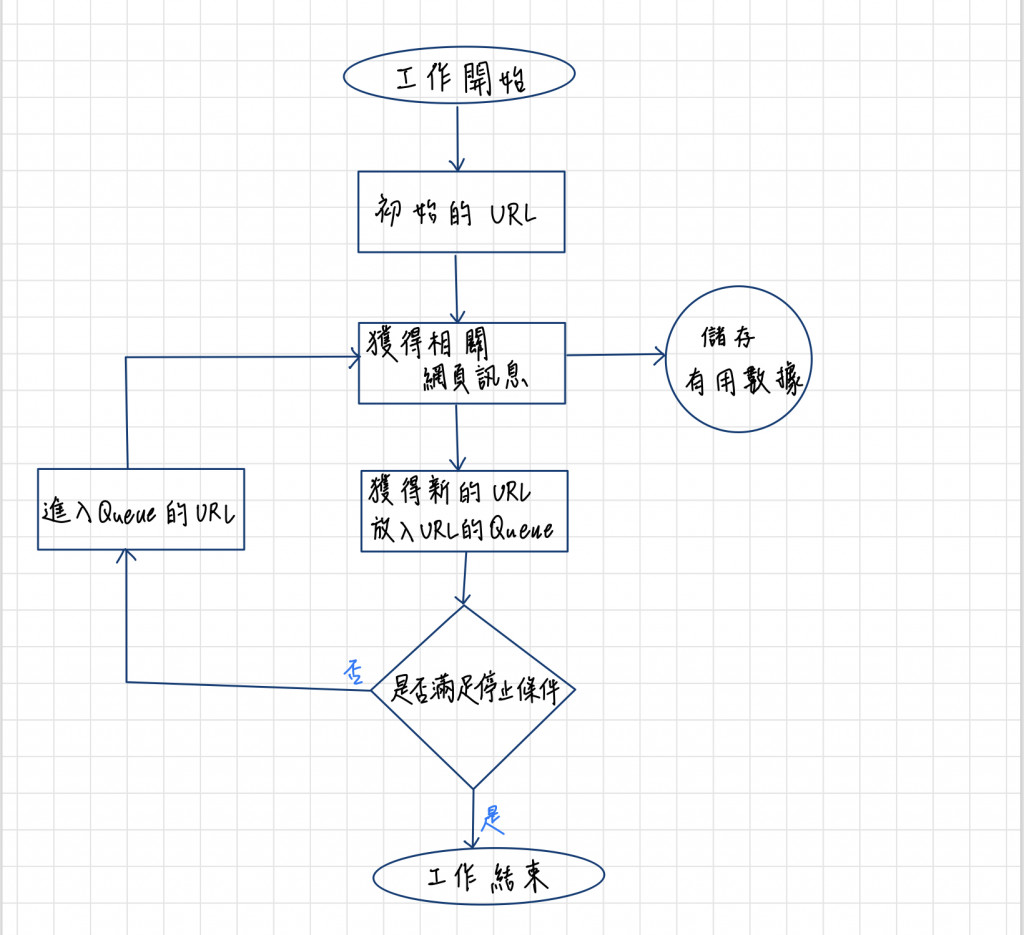
網路爬蟲工作原理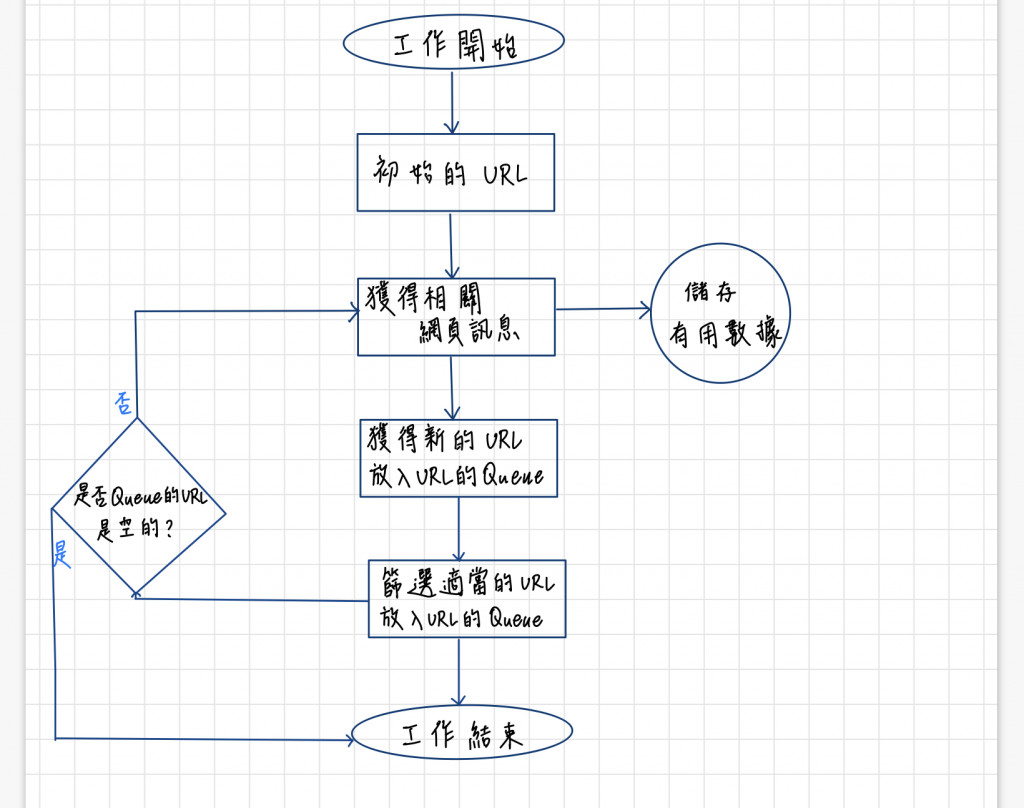
結語
在今天之前,我也只知道網路爬蟲而已,原來還有分為這幾個種類!
知道這些種類後,以後需要獲取不同資料的時候,就知道可以使用哪種爬蟲種類了。
明天!
【Day 14】爬進PTT的網頁吧!(實戰PTT 1/3)
參考資料
Python網路爬蟲:誰是真正的鄉民之王?https://deepmind.com.tw/sse%E7%9F%A5%E8%AD%98%E8%A3%9C%E7%B5%A6%E7%AF%84%E4%BE%8B/

