
此系列文目前主要在此網站上繼續連載,本文更新於此:https://web-tracking.allenchou.cc/docs/browser-fingerprinting/browser-fingerprinting-and-information-theory/
上篇文章我們討論到 browser fingerprinting 需要使用許多 feature,每個 feature 的有用程度可能不太一樣。那,有沒有什麼方法可以衡量一個 feature 是否有用?每次 fingerprinting 時追蹤者對於使用者的認識增加程度都一樣嗎?還是有可能追蹤者拿到了 fingerprint 卻發現它沒什麼用?其背後都是在講同一件事情:browser fingerprinting 洩漏了多少「資訊」。於是我們進入了 Information Theory 的世界。
Information Theory 通常被翻譯成「資訊理論」,跟 theory of computation 計算理論不一樣,不要搞混了。Information Theory 出自 Claude Shannon 的 A Mathematical Theory of Communication,當時主要是在通訊的情境下做討論,但如今 Information Theory 已經四處可見,從最早的衡量通訊頻道可以承載多少資料、如何壓縮資料,到 Machine Learning 裡面討論每個神經元可以儲存多少資料,密碼學裡面有沒有什麼演算法可以抵擋無限計算資源與時間的攻擊者等,都是 Information Theory 的應用。
今天我們要討論的是,Information Theory 如何應用於 browser fingerprinting 的情境中。這篇文章會有一些數學,如果讀者對這些沒興趣,可以大膽地跳過這篇,對於後續文章的理解不會有太大的影響。
相信大家都知道 bit 是什麼。一個 boolean 是 1 bit,一個 ascii 會吃掉 8 bits。
所以「有啟用 cookie」是 1 bit。
然後我的 user agent 如下,
Mozilla/5.0 (X11; Linux x86_64; rv:103.0) Gecko/20100101 Firefox/103.0
有 70 bytes,所以是 70 * 8 = 560 bits。
所以我只要蒐集 user agent,就可以拿到 560 bits 的資訊量。換言之,這可以容納 2^560 種可能,space 這麼大,根本不可能重複,對吧?
不是這樣的。甚至,AmIUnique 說有 0.37% 的人和我的 user agent 一樣,遠大於 1/2^560。
我們可以這樣想:是的,儲存 Mozilla/5.0 佔用了 11 * 8 = 88 bits,但這個 88 bits 真的有派上用場嗎?所有主流 browser 的 user agent 都是 Mozilla/5.0 開頭啊,那儲存這個資訊對於我辨認使用者根本沒有幫助。
至此我們已經得到第一個觀念:重點不在於有多少 bit,而是有多少 bit 可以幫助辨識使用者。
可是,一個 bit 有沒有幫助並不是 binary 的,不能說「這個 bit 有幫助」、「那個 bit 沒幫助」。在剛剛我們看到 user agent 的前 11 個字,因為大家都一樣,所以沒有幫助。但試想,如果突然出現一個人的 user agent 開頭是 Zbmvyyn\3-1,是不是超級顯眼?換言之,並不是前 88 bits 沒有用,而是當前 88 bits 是 Mozilla/5.0 沒有用!
如果前面的舉例太 technical,我們可以換個日常一點的舉例。試想,現在有個超級好學生,從不遲到,上課總是認真做筆記,回家認真寫作業,以及另一個爛學生,瘋狂蹺課,作業都用抄的。有一天我上課前走進教室,看到有個人坐在裡面,請問那是好學生會讓我比較訝異,還是那是爛學生會讓我比較訝異?肯定是爛學生吧。如果好學生在裡面,我一點都不會意外,但如果是爛學生在裡面,我會很錯愕想說他怎麼會來上課,是不是今天要期中考了。同樣是出席與否(1 bit),當好學生出席時,不會發生什麼事,沒人在意,但當爛學生出席時,會讓我非常 surprise,因為這太特殊、罕見、獨特了,他竟然會來上課!
這就是 surprisal 的概念:當我看到這個結果時,我會多訝異。或是稍微正式一點來說:這個結果有多獨特、它蘊含了多少資訊。一個越不可能發生的事件,發生時我們獲得的資訊量就會越大,正如那個不來上課的爛學生,如果他來上課了,肯定是要出大事了。
握緊手把,我們要來看數學了。
若 F 是個 browser fingerprinting 的演算法,當遇到 browser x∈X 時,F(x) 的輸出是 f_n, n ∈ {0, 1, ..., N} ,並遵循 discrete pdf P(f_n),則每一個輸出的 surprisal I 可以如此表達:
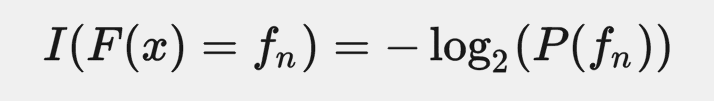
讀者可能覺得莫名其妙,這公式哪裡飛來的。為了不讓這篇文章變成數學地獄,我們只需要用直覺理解就好。P(f_n) 是個機率,介於 0 到 1 之間,所以 I 介於 ∞ 到 0 之間。如果機率接近於 0 的事件發生,我們會接近無限地訝異,如果機率接近於 1 的事件發生,我們一點都不在乎,訝異程度接近 0。如果對 log 函數不熟,可以參考這張函數圖,其中 x 軸是發生機率,y 軸是 surprisal。
所以至此我們已經有第二個重要觀念了:surprisal 的是衡量某個值的罕見程度,越罕見的值蘊含越多資訊,對於辨識使用者的幫助越大。
但故事還沒結束。我們可以設想一個情境:全世界剩下一個 browser 還支援 Flash,於是「支援 Flash」的 surprisal 非常大,它非常獨特,可是剩下來一百億個 browser 都不支援 Flash,surprisal 接近於 0。所以追蹤者在做 fingerprinting 時應該偵測是否支援 Flash,因為可能會遇到超級大的 surprisal,當剛好遇到那個唯一支援 Flash 的 browser,就可以超級準確地識別出他。好像哪裡怪怪的吧?對於幾乎所有人,那個 bit 是完全被浪費的,它什麼也沒講。除了其中一個特例以外,所有 browser 都不支援 Flash,知道不支援 Flash 幾乎毫無幫助,卻要浪費 1 bit 去存這個垃圾。顯然用 1 bit 換取偵測到百億分之一的特例不太划算。
有沒有什麼方法可以衡量一個 feature 有多划算?一個很直覺的作法是:不如我們取 surprisal 的期望值?這就是 entropy(通常以 H 表示)的概念。
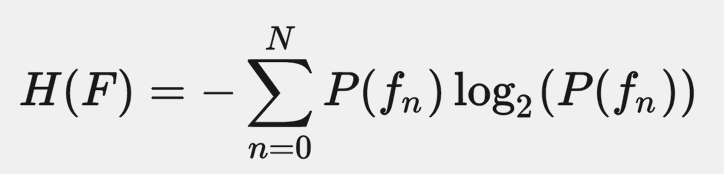
需要注意的是,entropy H 是 function of the distribution,其 input 是一個 distribution function,不是特定的值,output 也只根據 F(browser fingerprinting algorithm)與 X(browser 的 random variable),與遇到哪個 browser(x)無關。
以上面的例子來說,因為只有百億分之一的機率可以遇到唯一一個支援 Flash 的瀏覽器,所以「是否支援 Flash」的 entropy 是: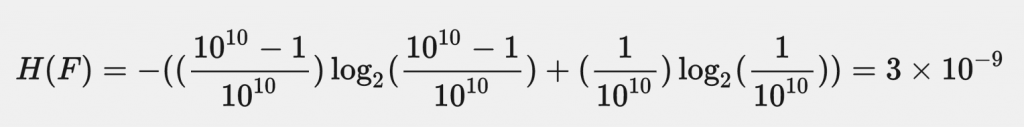
1 bit 的資料平均而言只貢獻了 3 x 10^-9 bit 的資訊,聽起來不太划算。
我們來討論另一個情境:使用者是否使用 Chrome。根據統計,有 65% 的使用者使用 Chrome,所以「是否使用 Chrome」的 entropy 是: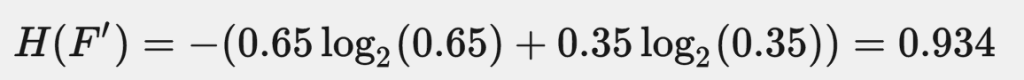
同樣是 1 bit 的資料,「是否使用 Chrome」貢獻了 0.934 bit 的資訊,和「是否使用 Flash」那趨近於 0 的資訊量相比,顯然「是否使用 Chrome」是個更好的 feature。
所以話說回來,entropy 到底是什麼?Entropy 用於衡量我們對資訊的 certainty。越是肯定的事情 entropy 會越小,越是不肯定的事情 entropy 會越大。試想,我們非常肯定 user agent 的前 88 bit 是 Mozilla/5.0,也非常肯定幾乎所有 browser 都不支援 Flash,所以這兩個 feature 的 entropy 都會很小。同時,我們沒有很肯定 browser 的預設語言是什麼,有可能是中文英文德文之類的,沒有很肯定使用者的時區是什麼,也不太肯定使用者的瀏覽器是不是 Chrome,因此這些 feature 的 entropy 很大。
至此我們可以看出重點了:如果可以用很少 bit 取得很大的 entropy,代表這個 feature 很划算。
雖然讀者可能不需要知道,但還是提一下:Shannon 證明了 1 bit 的 entropy 不可能超過 1 bit,所以別期待有可能存在 feature 是 entropy 比所需空間還要更大的,數學上可以證明這不可能存在。
最後提一下,如果要辨識出地球上每一個人,需要的 entropy 為 33 bit,因為 2^33 > 8 x 10^9。
Shannon's Entropy 的缺點在於,它很難理解。我可以理解 2 bit 的 entropy 比 3 bit 還要少,但所以 2 bit 到底是什麼概念?為了更直觀的理解,另一種討論途徑是使用 anonymity sets 的概念。
Anonymity set 的概念是:把所有相同 attribute 的 browser 都 cluster 在一起。所以如果一個 anonymity set 非常大,意味著有非常多 browser 擁有一模一樣的 fingerprint,於是追蹤者就無法辨別個人身份,他只知道這一整群人裡面有其中一個人做了什麼,但他不知道是誰,或甚至追蹤者連 anonymity set 裡面有多少人都不知道。因此在抵禦 browser fingerprinting 的討論中,有許多嘗試是把 browser 盡可能地塞入大一點的 anonymity set,使其淹沒在人海之中,就很難被 track 了。
最後想抱怨個,我不確定是不是自己第一次在這個平台發文所以不清楚操作方式,但我沒有找到插入 MathML 的方法,導致這篇文章在撰寫上與呈現上都和預期有不小的差異。等鐵人賽結束後我會把文章整理成 GitBook,屆時應該會好很多。
Eckersley, Peter. "How unique is your web browser?." International Symposium on Privacy Enhancing Technologies Symposium. Springer, Berlin, Heidelberg, 2010.
Understanding Your Browser Fingerprint, Or, a Basic Introduction to Information Theory

 iThome鐵人賽
iThome鐵人賽