
此系列文目前主要在此網站上繼續連載,本文更新於此:https://web-tracking.allenchou.cc/docs/privacy-preserving-web-tracking/ipa/
最後一天我們要看的是 Mozilla 和 Meta 的 Interoperable Private Attribution(IPA,與啤酒沒有關係)。IPA 所要解決的問題與 PCM 非常相像,都是 conversion measurement / ad attribution,不過 IPA 的架構卻顯著地比 PCM 複雜非常多。此文我們會討論 IPA 的架構及特性,並會討論到 IPA 解決了什麼 PCM 的問題。
我猜也許不少讀者跟我一樣,看到 Mozilla + Meta 這個組合時感到很訝異,一個注重網路隱私的公司,與一個以侵害隱私而惡名昭彰的公司聯手開發一個隱私保護的 conversion measurement 機制,這肯定需要關注的。喔對,我想還是得把話說清楚。IPA 的系統架構很複雜,非常複雜,比這系列曾經介紹過的任何系統都還要更複雜。所以我們開始吧!
IPA 與其他 privacy-preserving web tracking 一樣,試圖在一個沒有 third-party cookie 的時代做 tracking。IPA 旨在不追蹤特定使用者的情況下做 conversion measurement。如果不知道 conversion measurement 是什麼,可以先回頭看 Day 29 的文章。簡言之,廣告商需要知道廣告的曝光、點擊和各個事件之間的對應關係,例如使用者點擊廣告之後有做消費、有註冊帳號等。過去要達成這點,需要仰賴 third-party cookie 做追蹤,或是在 native app 會仰賴某些 identifier,但這其實會造成不必要的隱私侵害,廣告商不需要也不該知道個別使用者的操作,只需要知道最後的統計結果就好了。IPA 嘗試使用 MPC 與 differential privacy 等技術來達到這個目標。
首先得強調的是,IPA 目前還在 proposal 階段,正在廣徵意見,也還沒有 implement 出來,所以未來可能會有很大的改變。我只能根據寫作當下的版本來介紹 IPA,如果是幾年後的訪客,還請注意,也許 IPA 已經有完全不同的面貌了。
簡單定義一下名詞。當使用者在 blog.example 點擊 shop.example 的廣告,或是看到 shop.example 的廣告(曝光),這樣的事件叫做 source events,簡言之與廣告投遞有關的事件都屬於此類。使用者進入 shop.example 後如果註冊帳號、消費、下載 App 之類的,shop.example 會觸發一些事件通知 blog.example,這類型的事件叫做 trigger events。
雖然砍了 cookie,但我們還是需要一個 identifier 來識別 conversion。IPA 的作法是使用 match key,它可以被網站寫入,但只能被 browser 讀取,網站寫了之後就讀不到了。所以 site A 寫了一個 match key,它當然知道自己在這個裝置寫入了什麼,但所有其他網站都看不到這個 match key,也因此 match key 無法用於 cross-site tracking。回想一下 FLoC 遇到的困境,便可知道這個性質很重要。
讓網站可以指定 match key 的好處是,追蹤可以橫跨裝置。試想一個情境是,我在電腦與手機都有使用 Facebook,在傳統 third-party cookie 下,Facebook 可以安裝同樣的 cookie,藉此追蹤橫跨裝置的 conversion,可是在許多其他 privacy-preserving web tracking 中,往往訴諸 browser 自己生 identifier,於是這種可以跨裝置追蹤的特性被拿掉了,而 IPA 正是嘗試在不犧牲隱私的前提下重新實現跨裝置追蹤的可能。
另外,雖然其他網站不能讀到 match key,但它們可以「使用」match key,後文會討論如何讓網站在不讀到 match key 的前提下使用它。
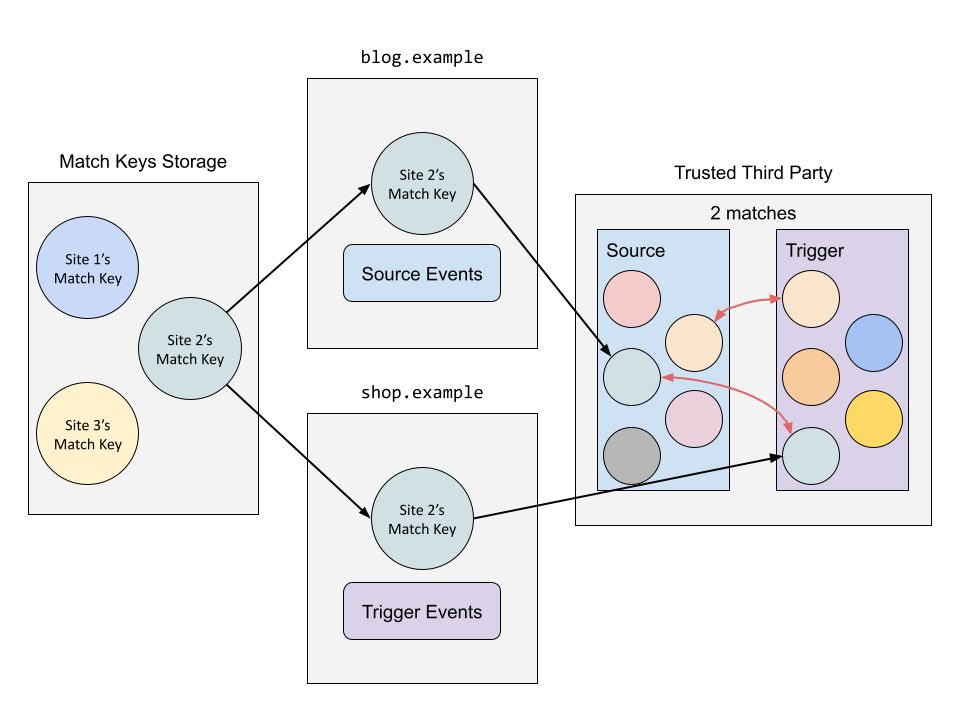
為了使廣告的買家與賣家可以核對 conversion,我們需要仰賴一個第三方可信任的伺服器來幫忙比對資料,這個第三方可信任伺服器會先生出一把 key-pair 並公佈其 public key。
一開始大型網站(例如 Google、Facebook 等)會先建立一個 match key,而一般網站,例如 blog.example 與 shop.example,可以指定他想要用哪個網站的 match key,例如指定要用 Google 的 match key。
當使用者在 blog.example 點擊廣告(source event),並在 shop.example 完成消費(trigger event),則 blog.example 與 shop.example 會各自獲得發生在自己網站上的 event。他們接著使用 browser 的 API 把 match key 使用前述的第三方可信任伺服器的 public key 加密,然後連同 event 的明文封裝好,並儲存起來。需要注意的是,網站只能透過 browser 的 API 拿到 match key 的密文,網站本身還是看不到 match key。
接著 blog.example 與 shop.example 可能會交換他們收到的 event 以及其 match key 的密文。當任一方需要了解 conversion 數量時,會把兩方有關的 event 挑出來,把對應的一堆 match key 密文傳給第三方可信任的伺服器,伺服器用其 private key 解密後,算出有成對的 match key,於是就知道 conversion 的數量了。
舉例來說,如果我想要知道有多少人點了廣告之後真的有註冊會員,就先把 blog.example 上點擊廣告(source event)對應的 match key 密文,以及 shop.example 上註冊會員(trigger event)對應的 match key 密文都蒐集起來,傳給伺服器。伺服器看到有個 match key 為 123 的在 blog.example 上點了廣告,又看到同個 match key 在 shop.example 上註冊會員,於是就知道有一個成功的 conversion(點擊廣告導致一個會員註冊)。伺服器計算有多少成功的 conversion,然後將此數量回傳。
在這整個過程中,blog.example 與 shop.example 都沒有看到 match key,也沒有看到發生在對方網站上的任何 event,只知道伺服器回傳有多少個成功的 conversion。
但這麼做有個問題是:這個可信任的伺服器看得到 match key,所以他就有能力追蹤使用者。如果真的存在一個伺服器是大家都可以信任的,我們都很有信心他絕對不會嘗試追蹤大家或洩漏任何資料,而且絕對不會被入侵而資料外流,那到目前為止故事已經結束了,皆大歡喜的結局。但問題就在於,我們不想假設也不能假設這樣的伺服器存在啊。如果這個伺服器不完全受信任,他也許會嘗試追蹤使用者、把資料洩漏出去,或是被入侵,我們可以怎麼做?
IPA 所使用的解法非常暴力:用 MPC (Multi-party Computation) 結束這回合。所謂 MPC 是一系列的密碼學協定,其允許多個參與方(party)一起計算 function 的 output,同時又不洩漏 input 給其他參與方。以 IPA 的情境來說,受保護的 input 是 match key,想要執行的 function 是比對 source events 和 trigger events 之中有沒有來自同個使用者的 pair,也就是有同樣 match key,output 是有同樣 match key 的 event pair。
我們的目標很簡單:第三方伺服器要可以比對有哪些資料中的 match key 是一樣的,同時不能知道 match key 的值,藉此避免 tracking。
在密碼學中,有一種常用的技術叫做 blinding,其概念是,如果 Alice 希望 Oracle 協助算出 f(m),可是不想讓 Oracle 知道 m,則 Alice 可以先算 E(m) 後送給 Oracle,Oracle 算出 f(E(m)),然後 Alice 把可以跳過 f 隔空解密,得到 D(f(E(m))) = f(m)。我們把 E 稱為 blinding function,通常 E 可能是替輸入加上一個指定的數值之類的,我們稱這個數值為 blinding factor。聽起來很像是黑魔法,但真的把演算法攤開來看會發現出乎意料地簡潔,不過這不是本文重點,所以就不細究了。
回過頭來,我們如果希望第三方伺服器一方面可以比對 match key 是否一樣,另一方面不要知道 match key,其實這可以用類似 blinding 的方式解決:browser 用第三方伺服器的 public key 加密 match key,第三方伺服器先挑個 blinding factor 做 blinding,然後再解密回來,在(被做過 blinding 的)match key 上做計算。
用一個稍微簡單一點的比喻,假設現在 Alice 有一整串數字,Alice 想要讓 Oracle 幫忙算這些數字有沒有重複,但又不想讓 Oracle 知道這些數字,於是 Alice 先將每個數字都 +3 然後傳給 Oracle,Oracle 雖然看得到處理過後的數字,但他不知道 Alice 到底加了多少上去,於是他還是可以比對有沒有數字重複(因為相等的數字一起 +3 之後還是相等),但他看不到具體數字。
所以我們可以設想一個解法:blog.example 如果想要知道 conversion,就先把一堆密文(加密過的 event 與 match key)傳給第三方伺服器,然後第三方伺服器先加上 blinding factor 後再解密,於是就只能看到混淆過的 match key,並在這之上計算 conversion。但這沒解決問題啊,我們還是得信任第三方伺服器真的有做 blinding。
其解法也很簡單:我們再找另一個人也一起來做 blinding 不就好了?
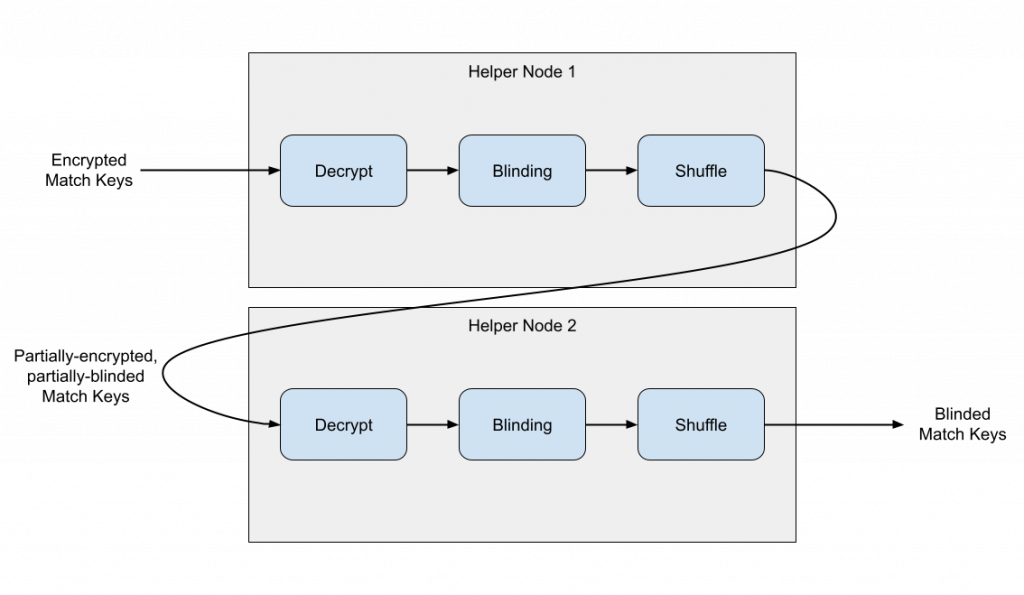
於是現在我們有兩個伺服器負責做 blinding。密文使用兩個伺服器的 public key 加密,也就是加密兩層(所以才叫做 double encryption),得到 E1(E2(m)) ,然後傳給第一個伺服器,它解密後得到 E2(m),先加上他自己的 blinding factor 得 E2(m'),再傳給第二個伺服器,第二個伺服器一樣解密完之後得 m',然後加上他自己的 blinding factor 得到 m'',再傳給負責運算的伺服器。
在這個架構中,負責運算的伺服器只看得到 blinded 的 match key m'',第二個伺服器拿到密文並解密後也只會看到第一個伺服器 blind 過的match key m',第一個伺服器拿到密文解密後只是另一個密文 E2(m),沒什麼用。只要兩個做 blinding 的伺服器不要 collude,就不會洩漏資訊。
稍微提幾個可能會有的疑問。首先,為什麼第一個伺服器對 E2(m) 做 blinding 不會讓第二個伺服器無法解密?理論上的確會如此,因此 IPA 要求使用 homomorphic encryption,也就是可以直接在 ciphertext 上運算,藉此讓我們可以讓 ciphertext 上做 blinding。第二個是,一開始說有個可信任的第三方伺服器負責做 blinding 然後解密,為什麼之後變成先解密再做 blinding?IPA 的文件沒有明確地講為什麼,但我的猜測是 homomorphic encryption 沒有辦法穿透兩層加密,所以第一個伺服器一定得先解密,讓加密只剩下一層,才可以做 blinding。
到這邊,狀況應該已經從糟糕變得難以理解了。所以我們來釐清一下整個 MPC 流程到底做了什麼。
在 IPA 的 MPC 架構中,有兩個重要角色:
一開始兩個 Helper Node 會各自產生一對 key,並公開其 public key。
當使用者在 blog.example 點擊廣告,並在 shop.example 完成消費時,兩個網站會使用 browser 的 API 將 match key 使用 Helper Node A, B 的 public key 分別加密,然後將其密文連同 event 封裝起來,回傳給兩個網站,他們會再私下交換密文。
接著,當有一個網站想要了解有多少成功的 conversion 時,他會挑出他想要搜尋的 event 所對應的 match key 密文,接著把這些密文傳給 Leader,Leader 會再把密文發給 Helper Node A 與 B。當 Helper Node A 拿到密文時,他會先用他自己的 private key 解密,並加上 blinding factor,順便 shuffle 一下密文,然後傳給 Helper Node B,後者會再做一次一樣的事情,然後回應給 Leader。Leader 再去比對有多少重複的 (blinded) match key 來算 conversion。
上述架構雖然可以不洩漏資訊給 helper node 與 leader,且廣告的買賣雙方也理應無法復原個別使用者的操作,但我們可以設想一個攻擊:blog.example 做兩次 query,第一次把 Alice 的 match key 密文放進請求,算出來的 conversion 是 10 次,第二次故意不把 Alice 的 match key 密文放進請求,算出來的 conversion 是 9 次,於是就可以推論出 Alice 有實現一次 conversion。
稍微離題補充一下,blog.example 在蒐集 event 與其對應 match key 密文時,可以存取到 cookie 之類的資訊,所以他可以把 event、match key 密文、使用者身份對應起來,只不過他(在正常情況下)不知道這筆紀錄是否有成功的 conversion。因此在上述攻擊中 blog.example 的確有能力故意找出 Alice 的 match key 密文並將其移除。
IPA 的解法是引入 Differential Privacy(DP)。DP 的核心精神是,在回傳的結果加上一點 noise,以致看到結果時無法直接判斷一個人有沒有在群體裡面。延續前面的例子,當 Alice 的 match key 在請求中,在回傳 conversion 時,不會直接說 10 次,而是從 10 ± 2 挑一個數字;當 Alice 的 match key 不在請求中,也不直接回傳 9 次 conversion,而是從 9 ± 1.8 挑一個,於是有可能兩次都回傳 10.2 次 conversion,或是第一次回傳 9.8 次,第二次回傳 9.7 次。於是 blog.example 看到這些數字時,他無從判斷 Alice 到底有沒有完成 conversion。
但這麼做會有兩個問題。首先,noise 大小的 "2", "1.8" 這些數字是怎麼來的?此外,如果多做幾次請求,是不是就可以把 noise 平均掉了?至此我們還要再引入一個概念是 privacy budget。
每個單位(無論廣告買賣方)會被分發到一定數量的 privacy budget(七天重設一次)。當發出請求時,他們可以指定要用多少 budget,用越多 budget,noise 就會越小,也就是數值會越精準。於是,如果不斷重複請求,則還沒把 noise 平均掉,budget 就會先耗盡了;如果一次 all in 所有 budget,會得到超級精準的答案,但也沒有剩下的 budget 可以做第二次請求了 。此外,根據每一筆數據的價值以及對於誤差的容忍程度,參與方可以決定每一次 query 要花多少 budget,對於那些錯了就算了沒差的數字可以用很少的 budget,那些越精準越好的就要用多一點 budget。
所以把系統搞得這麼複雜,IPA 跟 PCM(或是其他 on-device 的 conversion measurement 系統)相比獲得什麼優勢了?
首先,因為在 IPA 的系統架構中,廣告買賣雙方看不到最後到底有哪些 match key 成功完成 conversion,只能看到最終完成 conversion 的數量(而且還是加過 noise 的),所以不需要刻意隱藏使用者身份。因此,IPA 可以即時地把 event 資料傳給雙方,也可以允許非常多 campaign id(對應到 PCM 的 source id)。而同時,PCM 因為看得到每一筆 conversion 的 report,需要刻意等 24-48 小時,以避免藉由時間把使用者身份還原出來,而且要限制 source id 與 trigger data 以避免其被當作 identifier。
此外,因為 match key 可以由網站設置,所以藉由設置 match key,可以達成 cross-device tracking,在電腦上點的廣告,在手機上完成消費,一樣可以被偵測出來。這點是 PCM 所作不到的。站在 Meta (Facebook) 的立場,應該可以理解為何他們需要這個性質。
在缺點層面,IPA 相較於 PCM 有個硬傷是其仰賴第三方伺服器。雖然 PCM 同樣仰賴 proxy 來傳遞 attribution reports,但維護 leader 與 helper node 顯然比 anonymous proxy 更複雜與高成本。也許 OS 與 browser vendor 會扮演這個角色,但除了 Mozilla 自己以外,很難想像還有誰會想維護這些服務。
而且很現實的一點是 Firefox 的市占率有夠低,也不像是 Apple 有自己的 OS 可以強推,即使有 Meta 加持,其他廠商有多少誘因是 implement IPA 仍然是可疑的。
最後,IPA 目前還是 proposal 階段,也還有許多問題需要解決(事實上目前的 spec 漏掉蠻多細節的),例如目前假設 helper node 是 honest-but-curious,有沒有辦法 relax 這個要求。
雖然還有很多想寫的,但 30 天就這樣過去了,所以 privacy-preserving web tracking 需要先斷在這邊。我們一開始討論了 FLoC 如何嘗試挑戰 privacy-preserving 的使用者興趣分析,其作法又有什麼問題,FLoC 的取代者 Topics API 則嘗試處理這些問題,雖然好像沒有很成功,此外還有 Unified ID 2.0 等嘗試。接著我們討論了兩種不同的 conversion measurement 機制,分別是 Apple 的 PCM 與 Mozilla & Meta 的 IPA,其實另外還有 Google 的 Attribution Reporting API,只是我覺得它相對沒有那麼有趣,所以沒挑出來介紹。
目前我是打算把鐵人賽寫的文章集結一下放到一個網站上,賽後再陸續把之前跳過的主題補上去,以及重寫一些我沒有很喜歡的文章。如果有空,明天應該還會再發一篇結語,屆時再多做討論。
Spec: https://docs.google.com/document/d/1KpdSKD8-Rn0bWPTu4UtK54ks0yv2j22pA5SrAD9av4s/edit
Interoperable Private Attribution (IPA): A Non-technical introduction (大推,如果想對 IPA 有直觀的理解,絕對不能錯過這份簡報)
Interoperable Private Attribution (IPA) Explained
Overview of Interoperable Private Attribution

 iThome鐵人賽
iThome鐵人賽