2022 iThome 鐵人賽
分享至
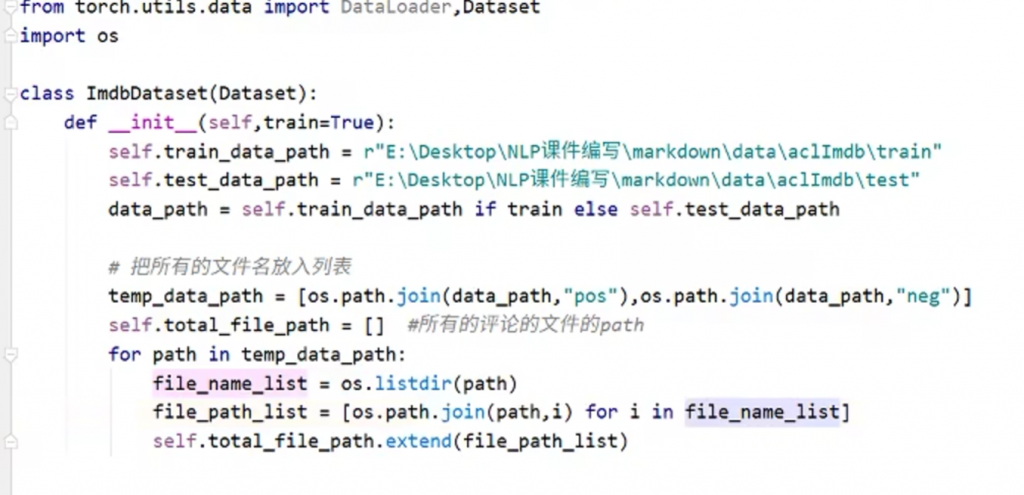
案例實作斯坦福大學的經典數據集IMDB,地址http://ai.stanford.edu.-amaas/data/sentiment/,這是一份包含了五萬條流行電影的評論資料,其中尋亂集25000條,測試集25000條資料結構是[序號和情感評分,評論內容]顯示按照路徑講資料取出來並放入dataset
按照網頁的分割符號講單詞一個個取出來裝進dataloader
最後先把訓練的模型寫好 明天繼續
IT邦幫忙