
今天我們來講一下資料(data)。這邊我們主要會分成兩部分,分別為:
在機器學習中,通常我們會將蒐集到的資料切一部分出來當作測試資料(testing data),來評估模型的表現。但若以比較正式或說標準的劃分法,我們會將資料分成三類,分別是:
validation_split='比例'去劃分多少比例的訓練資料要當驗證集。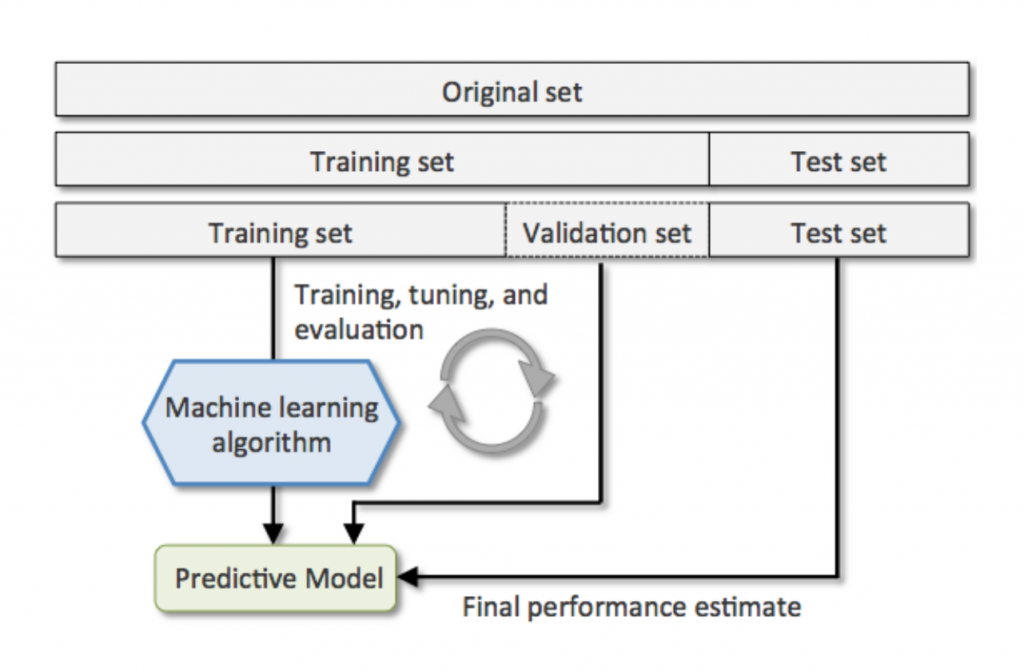
圖片來源:cross-validation:从 holdout validation 到 k-fold validation
若以考學測等大考來比喻,訓練集就像平常上課學習,我們根據課本講義裡的內容來掌握知識;驗證集就像平常的作業模擬考,透過作業或模擬考我們可以看自己的學習成果,看要繼續學還是要做調整;而測試集就像考學測等大考測驗,用來評估你的最終學習狀況。所以偷懶點當然也可以訓練學完就去考大考,不用驗證集。
在資料驗證的部分,這邊介紹兩種常用方法
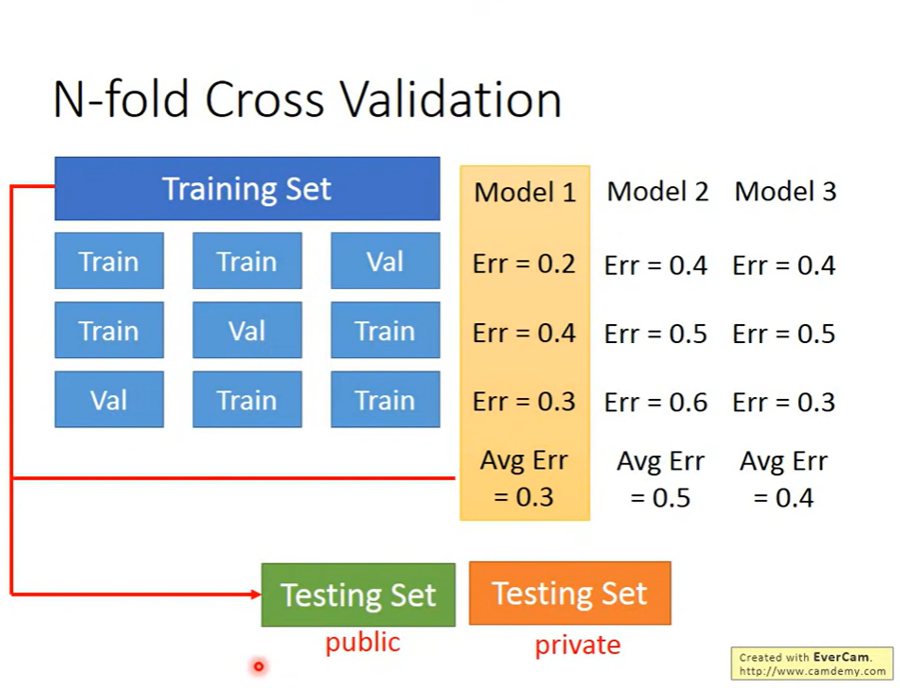
ps. 圖中 Testing Set 分成 public / private 這點我們會在後面講 Kaggle 的地方講。
用 Keras 疊一個神經網路需要先知道的幾個名詞 第6天(/6 days) 完成。
明天我們就可以開始用 Keras 套件疊起一個手寫數字辨識系統啦!
疊完我們再講怎麼調~

 iThome鐵人賽
iThome鐵人賽