前言
在本系列文章中,我著重於如何透過良好的告警事件管理來減輕維運人員的負擔,並降低 MTTR(平均修復時間)等關鍵指標。維運人員常見的告警痛點包括:告警疲勞(過多的告警導致無法區分重要性)、告警雜訊(低價值或重複的告警信息),以及缺乏一個統一且高效的可視化管理介面來協助排查問題。
目前,雖然有些服務(如 Karma)可以顯示當下的告警狀態並進行操作,但無法進一步查看告警的歷史或進行分析。基於這個思路,我在尋找解決方案時發現了 yakshaving-art/alertsnitch 這個專案,其理念與我的目標相契合。如果我們能對所有告警歷史紀錄進行持久化,並且透過 Grafana 提供的可視化介面找出寶貴的見解,並提高告警的透明度。
話不多說,讓我們趕緊一探究竟。
AlertSnitch 是什麼
AlertSnitch 是一個能夠將 Prometheus AlertManager 格式的告警內容,透過 WebHook API 的方式存入持久性後端的服務。
在現代的複雜雲原生系統中,如何有效地管理和追蹤系統告警已成為一項關鍵任務。為了滿足這一需求,我們擴充了原本的 AlertSnitch 專案。
在 yakshaving-art/alertsnitch 中,AlertSnitch 支援使用 MySQL 或 Postgres 作為持久化的儲存後端。而在我個人的分支出來 MikeHsu0618/alertsnitch 中,我著重於遵循原有的程式架構,新增 Loki 相關的寫入功能,使其成為擴展的持久化儲存後端,並提供更豐富的 Loki 版本 Grafana Dashboard,來強化告警分析的功能。
AlertSnitch 架構
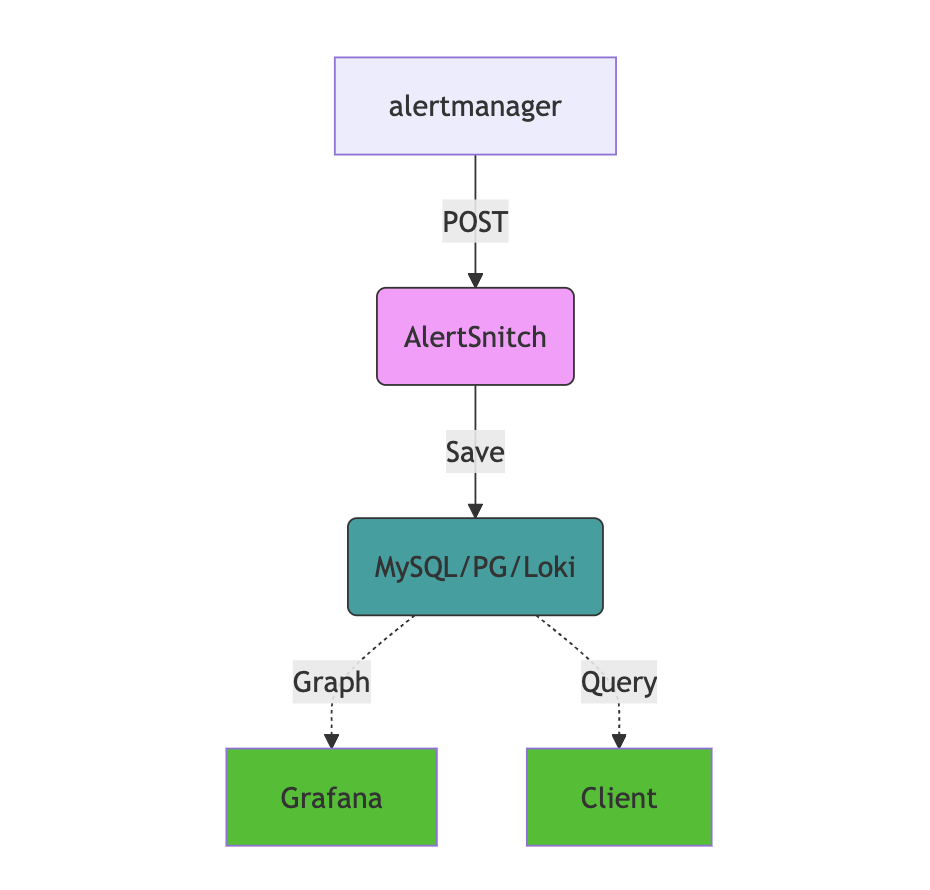
AlertSnitch 的架構與目的相當簡潔明確:
- WebHook Server:AlertSnitch 能夠做為 Prometheus Alertmanager 通知訊息格式相容的告警數據接收端點。每當有告警觸發或改變狀態時,AlertSnitch 能夠通過 WebHook 接口接收告警數據,並且將其傳入持久性儲存後端保存。
- 多種後端支援:當告警事件被收到後,AlertSnitch 會根據配置的後端選擇,將告警信息保存到對應的存儲系統中。對於 MySQL 和 Postgre,AlertSnitch 會自動檢查數據庫模型的版本並進行相應的升級;對於 Loki,告警數據會以結構化的日誌格式進行存儲。
- Grafana 高度整合:透過與 Grafana 的整合,可以使用 MySQL Data Source、PostgreSQL Data Source 或 Loki Data Source 來創建自定義的儀表板。這些儀表板可以用於顯示告警的趨勢、頻率、MTTR(平均修復時間)等重要指標,幫助團隊更好地了解系統的穩定性。
為何需要這類型的功能?
傳統的告警系統往往只關注於即時的告警通知,缺乏對歷史告警的系統性保存和分析。這導致了以下問題:
-
無法追溯歷史事件:缺少對過去告警的記錄,使得問題的根源分析變得困難。
-
缺乏統計分析:無法統計關鍵指標,如MTTR,影響了對系統穩定性的評估。
-
資訊孤島:不同的系統和工具之間缺乏整合,資訊無法共享。
解決方案:持久化和視覺化
透過將告警訊息持久化至 Loki,我們實現了對歷史告警的完整保存。結合 Grafana 強大的視覺化能力,使用者可以:
-
深入分析歷史告警:查看每一個告警的詳細資訊,包括觸發條件、影響範圍等。
-
監控關鍵指標:透過統計MTTR等指標,評估團隊的響應效率和系統的穩定性。
-
自定義報表和儀表板:根據需求創建個性化的視覺化介面,提升決策效率。
與Grafana的高度整合
Grafana 作為業界領先的開源視覺化工具,提供了豐富的 Dashboard 和 Plugin。我們的解決方案與Grafana 無縫結合,帶來了以下優勢:
-
即時更新:告警資料可以即時呈現在Grafana儀表板上,方便監控。
-
靈活的查詢語言:利用 Loki 的查詢語言,可以輕鬆篩選和分析特定的告警資訊。
-
擴展性強:可以與其他數據源整合,打造全方位的系統監控平台。
告警歷史可視化
為了讓使用者能夠直觀且深入地了解系統告警情況,我結合了原來的告警設計了一個與 Grafana 高度整合的 Loki 版本 Dashboard。這個 Dashboard 結合了多個關鍵區塊,透過視覺化的方式,提供從即時監控到歷史分析的全方位告警資訊。
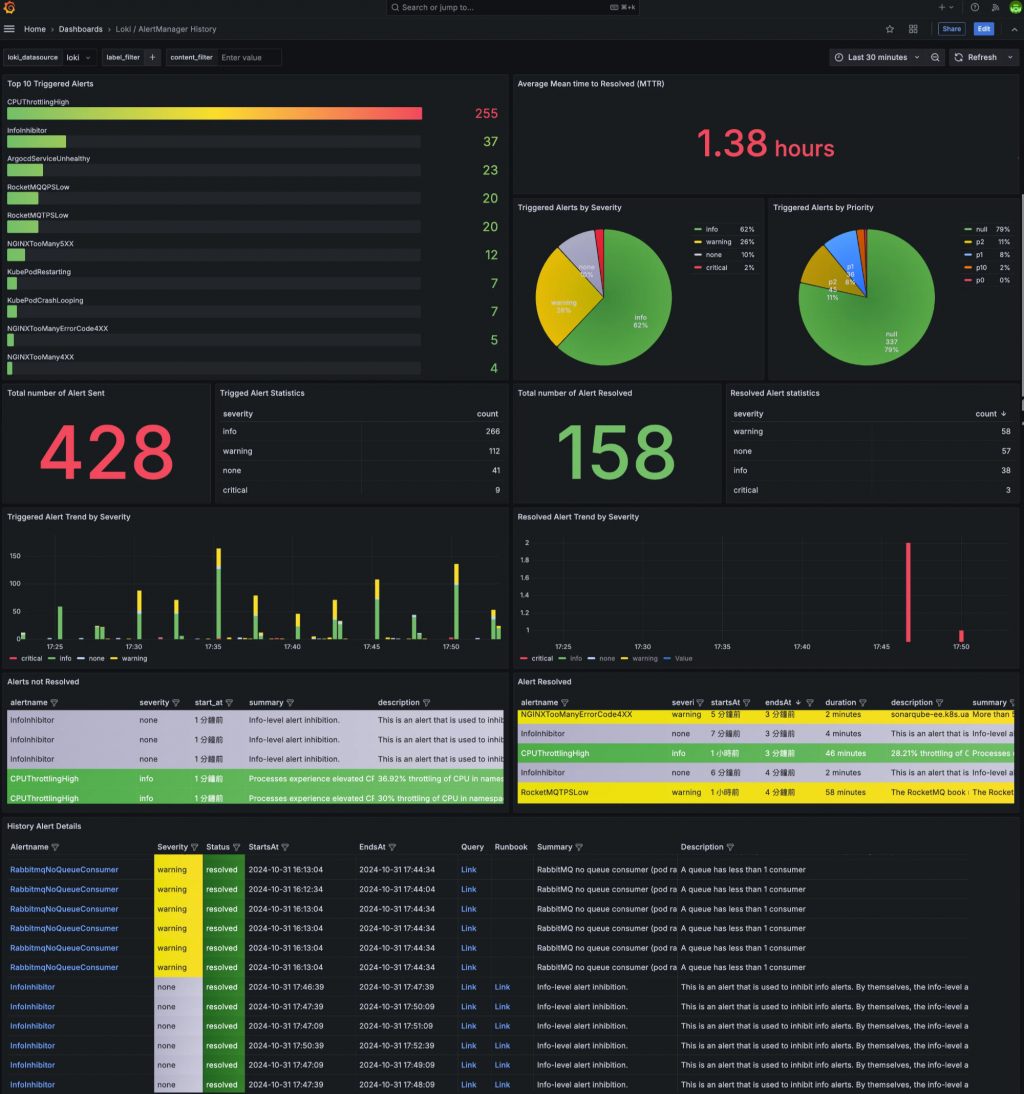
主要區塊介紹
1. 告警總覽與關鍵指標
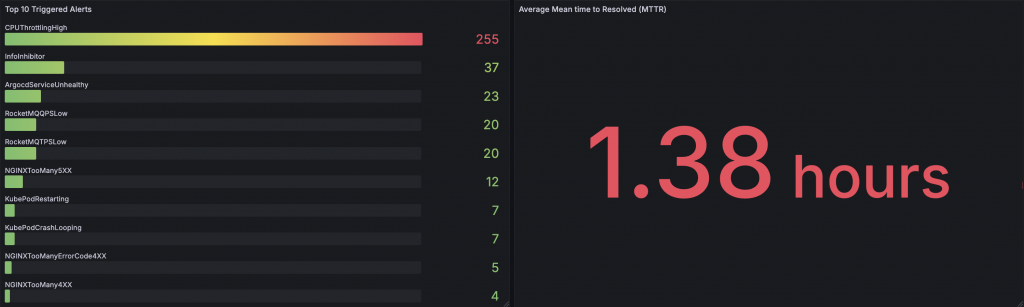
-
Top 10 觸發的告警:以柱狀圖展示最常被觸發的前十個告警,幫助使用者快速識別系統中最需要關注的問題。
-
平均修復時間(MTTR):計算告警從觸發到解決的平均時間,提供關鍵的運維效能指標,協助團隊提升問題解決效率。
2. 告警分類可視化
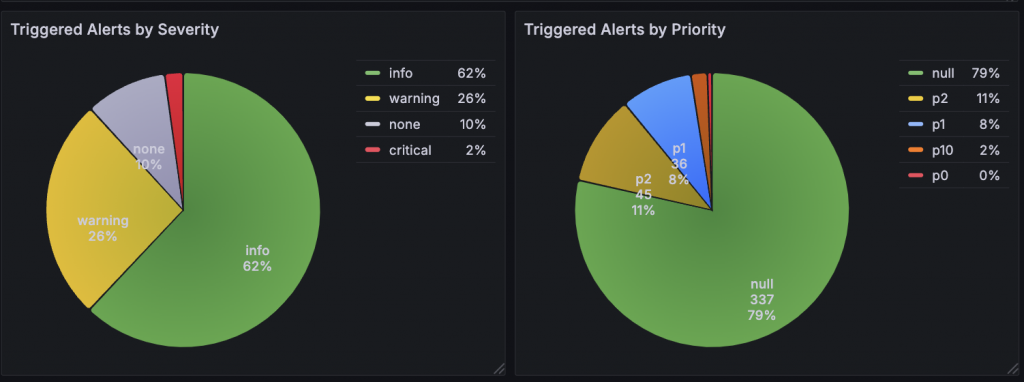
-
依嚴重程度分類的告警:使用圓餅圖呈現不同嚴重程度的告警比例,讓使用者直觀了解告警的嚴重性分佈。
-
依優先級分類的告警:同樣以圓餅圖展示不同優先級的告警,協助團隊優化資源分配。
3. 告警統計與狀態

-
總告警數與已解決告警數:透過統計卡片,分別顯示總告警數與已解決的告警數,提供整體的告警處理進度。
-
告警與解決統計表:以表格形式列出不同嚴重程度的告警數量,區分為「觸發中」與「已解決」,方便進行深入的數據分析。
4. 告警趨勢分析

-
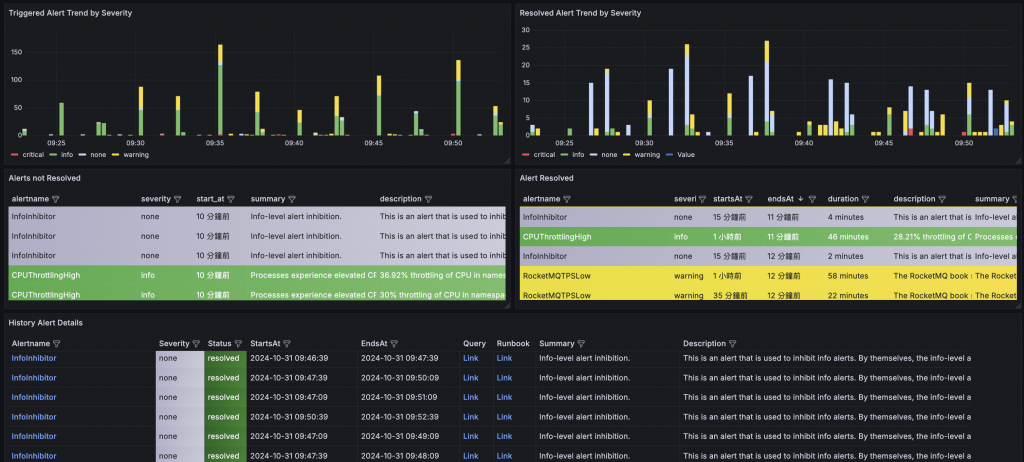
告警觸發趨勢:透過時間序列圖展示告警觸發數量的時間變化,並依照嚴重程度分類,幫助使用者觀察告警的發生趨勢。
-
告警解決趨勢:同樣以時間序列圖呈現已解決告警的數量變化,協助團隊評估問題處理的效率和速度。
5. 告警詳情與歷史記錄
-
未解決的告警列表:提供一個詳盡的表格,列出所有尚未解決的告警,包括告警名稱、嚴重程度、觸發時間等關鍵資訊,方便快速定位問題。
-
已解決的告警列表:列出已解決的告警,並計算每個告警的持續時間,為團隊提供改進 MTTR 的依據。
-
歷史告警詳情:完整記錄所有告警的歷史資訊,包括狀態變化、描述、開始與結束時間等,為問題的根源分析和歷史回溯提供強大的數據支持。
-
預定義連結:將 Prometheus AlertManager 預定義的 GeneratorURL、RunbookURL 等通用欄位,透過 Table 中的超連結快速跳轉至操作介面。
結語
我們探討了如何透過建立一個完善的告警事件管理系統來減輕維運人員的負擔,並優化關鍵指標如 MTTR(平均修復時間)。面對現代系統運維的常見痛點:告警疲勞、告警雜訊,以及缺乏可視化的管理介面,我們嘗試將告警歷史記錄進行持久化,並利用 Grafana 提供的強大可視化工具進行深入分析。
透過 yakshaving-art/alertsnitch 專案的架構,以及我在個人分支中添加的 Loki 整合,這套系統能夠有效保存和分析告警歷史數據,進一步提高系統的透明度和運維效率。希望這個系列能幫助我們更好地解決實際運維中的挑戰。
最後,覺得這個專案有趣的朋友歡迎也歡迎斗內你們的小星星:MikeHsu0618/alertsnitch

