Cassandra 在 2008 年由 Facebook 開源,主要作者為 Avinash Lakshman (他也是 DynamoDB 的作者之一) 和 Prashant Malik,目前為阿帕契基金會的專案項目之一。參考 Google BigTable 的資料模型設計和 DynamoDB 的分散式架構,讓它單 Row 最多可以高達 20 億個欄位,並具備高度可擴展性。Cassandra 提供了 CQL 語言(Cassandra Query Language),讓開發者在資料操作的體驗更貼近關聯式資料庫。
Cassandra 的架構中採用 Peer-to-Peer 模型,叢集中所有的節點是一樣,這種架構帶來的好處是不會有單點失效導致其他節點連帶被影響的問題,且方便增加或移除節點,資料分片也使用一致性雜湊法,這些設計和 DynamoDB 差不多。由於沒有節點負責主控所有的節點,因此每個節點自己要有辦法告訴叢集中的其他節點自己狀態,並確保擁有最新版本的資料,Cassandra 選擇使用 Gossip Protocal 達成此需求。
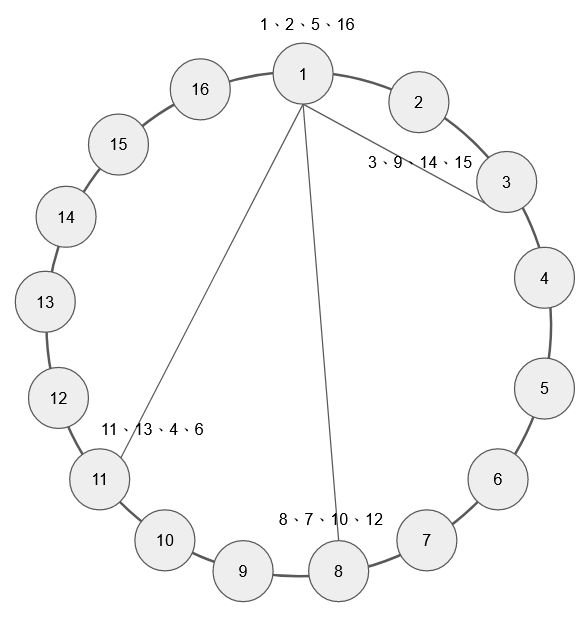
Gossip Protocal 簡單來說就是讓每個節點的狀態像流言一樣,節點與節點之間透過傳遞自己和自己知道的流言給其他節點知道,進而達成每個節點知道所有其他節點的狀態,而不用每個節點都和所有其他節點進行確認。當叢集中只有三個節點時,花一點點時間和左右兩個節點交流狀態不是太大的負擔,但當叢集裡有數十數百或成千上萬的節點時,這一點點的交流時間和流量成本就不容小覷。
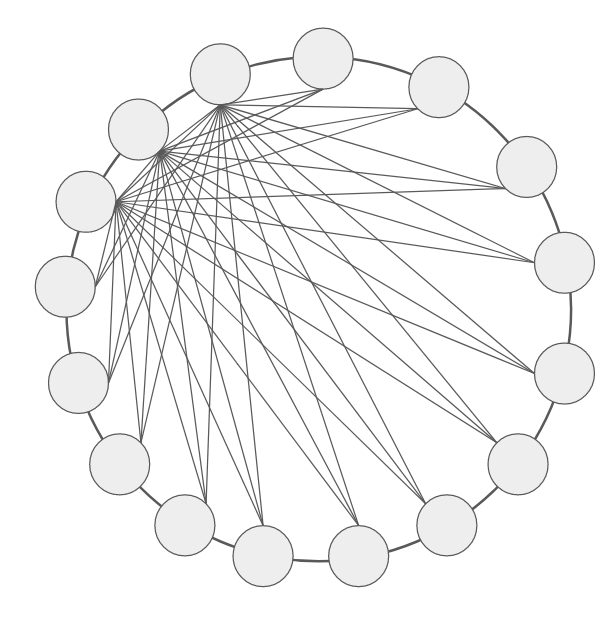
我畫三個點就累了,剩的線請大家自行想像......
若節點不用與每個節點都維持聯繫,而是將自身的狀態和自己所知道的部分散佈出去給其中一些節點,同時從那些節點「聽說」到其他節點的狀態,就可以更有效率的讓所有節點知道彼此之間的狀態。
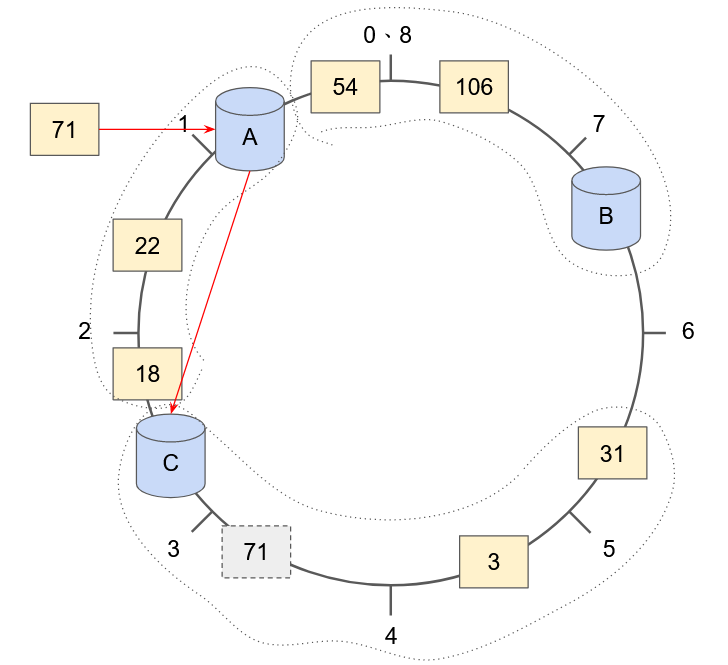
除此之外,Column Family Database 注重提供穩定的資料寫入功能,因此當負責該資料的節點暫時無法處理寫入請求時,其他的節點必須「暫時幫忙 Hold 一下」該請求,用這種方式達成永遠允許資料寫入的特性。如下圖所示,資料經過雜湊計算後可得知該資料應該被 C 節點處理,這時收到請求的 A 節點會根據自身所知 C 節點的狀態判斷,如果 C 節點現在的狀態是可提供服務的,那這個請求就會被傳送給 C 節點進行處理;反之,若 C 節點暫時無法提供服務,這個請求則會由 A 節點握著,直到 C 節點可進行處理,再進行後續流程。
Cassandra 也有提供索引等資料庫常見的功能,可以在它的官方網站查看更多資訊。

