對啊,這也是一種世界。也是我心中的可能性。現在的我並不只是我,還可以有很多種自我。
《新世紀福音戰士》碇真嗣
循環神經網路(Recurrent Neural Network),作為神經網路的其中一種變體,是在所有神經網路的模型中,最常被拿來應用在自然語言處理任務的模型之一。原因有二,首先,相對於其他的神經網路模型,循環神經網路模型的輸入資料較為彈性,意即當其他的神經網路只能接受固定的字數時,循環神經網路亦能透過不同長度的文本輸入進行訓練;二,語言中我們常說要了解上下文、語境,才能對語言有更完善的判斷,而循環神經網路的記憶功能就可以做到考慮文本上下文的效果。因為以上兩種原因,循環神經網路才會是所有神經網路中最常應用在自然語言處理上的深度學習模型。讓我們一起來看看為什麼吧!
在正式進入架構之前,要先將循環神經網路跟其他神經網路進行區別。跟先前所介紹的神經網路模型相同,一個完整的循環神經網路模型同樣也有輸入層、隱藏層,以及輸出層,但既然基本架構都相同,那最關鍵的差異點在哪裡呢?我們先來觀察以下這兩張圖。上圖是人工神經網路,是輸入,
是輸出;下圖則是循環神經網路,
是輸入,
則是輸出,其中
是隱藏層。

Credit: Speech and Language Processing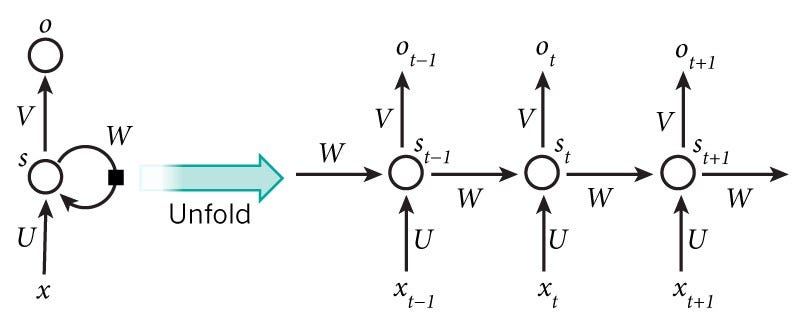
Credit: kdnuggets.com
不知道大家有沒有發現到,這兩張圖之中最大的差異就在於,循環神經網路的隱藏層會自我循環,也就是說,若將隱藏層拆開來看的話,隱藏層中的節點會接收上一個隱藏層節點所傳過來的權重。也就是說,對資料的每一個節點來說,就像是碇真嗣所說:「現在的我並不只是我,同時也包含了過去到現在的很多種自我。」所以我們重新回來看神經網路的圖示架構可以發現,正是因為這樣的特性,循環神經網路才有記憶的功能。
理解循環神經網路最大的特色之後,再讓我們回來看其中的數學運算原理。其實除了隱藏層之間的連接特性之外,循環神經網路的計算也跟一般的神經網路大同小異。首先是輸入資料與權重
相乘,接著再跟上一個隱藏層神經元所學習到的資訊
與權重
相乘,再把兩者相加,把相加之後的值加入激勵函數
,稱為當下隱藏層的輸出
,接著當下的輸出層即是隱藏層輸出乘上另一個權重
,再經由激勵函數產生輸出
。

除此之外,循環神經網路彈性的輸入與輸出特性,也讓我們在各種下游任務間來去自如,其輸入與輸出及對應的功能如下:
那該如何解決梯度消失以及梯度爆炸的問題呢?其實一般來說,在自然語言處理的任務中,不會僅僅只用循環神經網路,也會在裡面再加上另外一層深度學習模型:長短期記憶(LSTM)。同時應用循環神經網路以及長短期記憶模型,就可以有效避免梯度消失以及爆炸的問題了。
那我們明天就相約在長短期記憶見囉!
下一篇文章
若你有空,也歡迎來看看其他文章
➡️ 【NLP】Day 14: 神經網路也會神機錯亂?不,只會精神錯亂...深度學習:前饋神經網路
➡️ 【NLP】Day 13: 可不可以再深一點點就好?深度學習基礎知識:你需要知道的這些那些
➡️ 【NLP】Day 12: 豬耳朵餅乾跟機器學習也有關係?機器學習:羅吉斯回歸

