今天我們要來講講疊加模型
到目前為止介紹的模型像井字遊戲的決定下一步和inception對照片分類都只有簡單輸出,為了完善這些功能所以要讓AI識別出照片中物件的定界框,因為AI並不會對整張照片逕行分類而是對特定的目標逕行分析。
通常模型要輸出定界框是一件非常複雜的事情,因為他必須處裡各種不同類別以及重疊的框,所以與其花費心力用數學運算特別去清理不必要的類別不如專注在tensflow.js上用一個矩形框出我們所需要的,這就是所謂的本地化物件(object localization)。
今天本地化模型示範的模型用了名為Oxford-IIIT Pet Dataset的公開資料進行訓練,此模型需要輸入寵物256x256的RGB影像,並用四個輸入的數值來框出寵物臉部周圍的界定線
注意! 螢幕上泛指的螢幕坐標和我們日常用的笛卡爾坐標系唯一不同的是螢幕座標以螢幕的左上角視為原點。
總之這些點被表達0-1之間的值,以影像百分比表示。
首先先調整好張量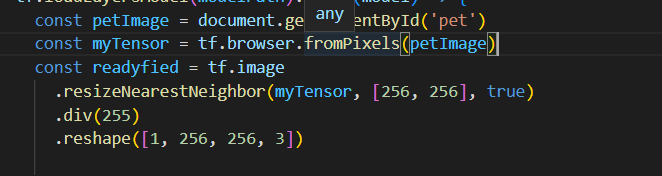
標記和偵測出結果,這是將我們的影像先放置在容器中,上面再蓋一層擷取框的畫布(這裡使用了CSS)
在框架中進行縮放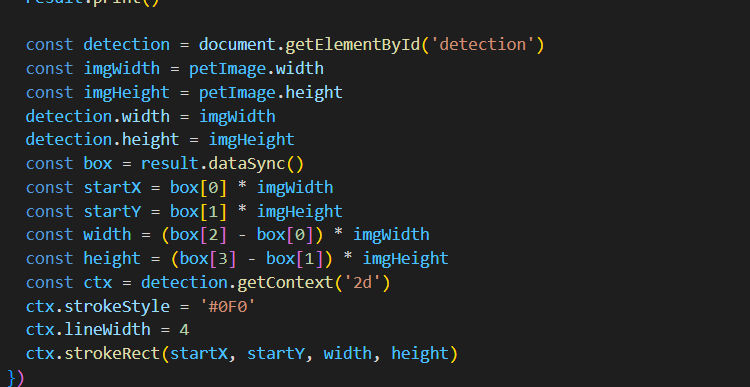
大概就這樣謝謝大家

