
在 Day16 - Observability 介紹 中了解了 Metrics、Tracing 和 Logging 三大資訊,其中 Logging 和 Metrics 概念上都比較直觀,都是紀錄單一服務下的系統資料。那 Tracing 是什麼?為什麼在 Microservices 架構下會需要它?本篇就來跟大家介紹。
Distrubuted Tracing 能夠追蹤單次請求在系統內部的行為,主要用在 Distributed System 或是 Microservices,透過可視化的方式將延遲時間、觸發行為等資訊顯示在 Dashboard 上,幫助使用者追蹤故障位置或是效能瓶頸等原因。
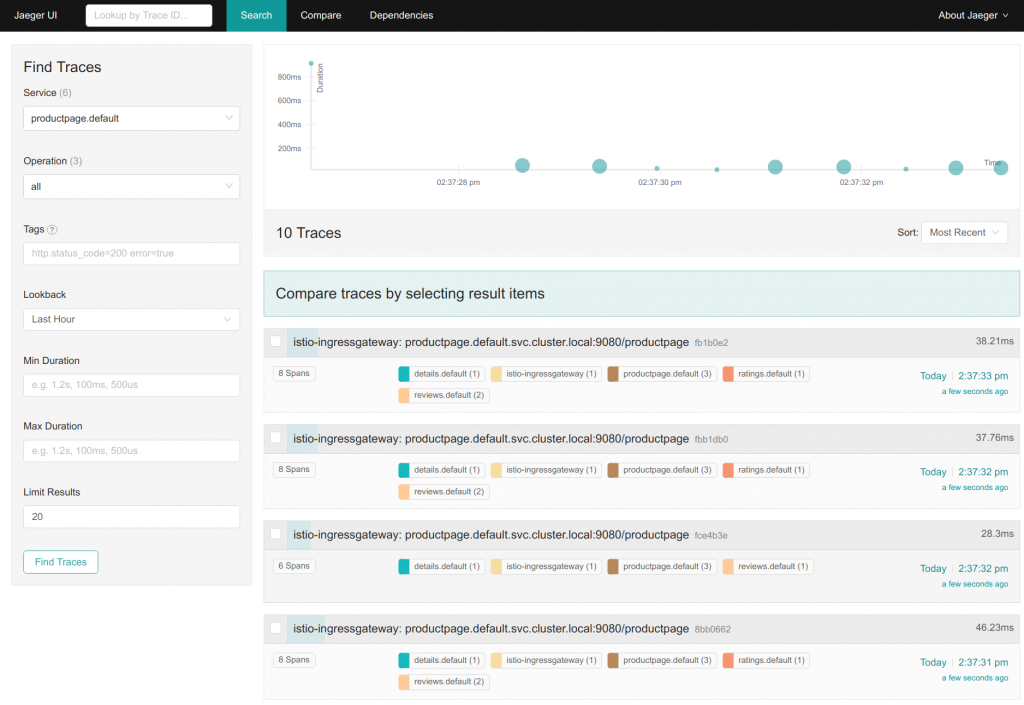
Jaeger 的 Tracing Dashboard,圖片取至 Istio Document - Jaeger
使用 Metrics 及 Logging 資訊能清楚呈現單一 Service 資訊,但若是放到 Microservices 架構,因為系統是由多種元件所組成,單一請求會跟多個元件進行互動,若只對 Service 個別監控,在遇到複雜的問題時沒有統整資料,對系統 Troubleshooting 時會較為困難。
試想若是單一請求故障或是延遲時間過長,比起針對可能出狀況的元件一一查看 Metrics 及 Logs,如果有一個統整所有元件的資訊,會幫助我們更輕鬆的釐清問題。
而 Distributed Tracing 能夠將單次請求在系統內部是如何處理的方式,包括經過哪些元件、元件之間的溝通時間、呼叫的路徑為何給記錄下來,讓我們完整的了解請求是如何被 Microservices 處理的,以此提升系統的 Observability。
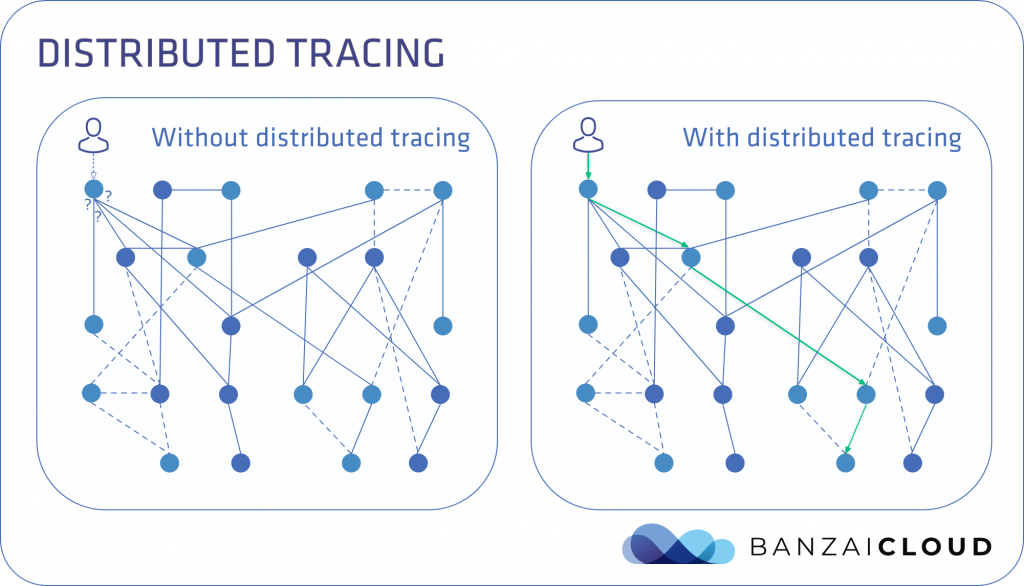
Distributed Tracing 能追蹤單次請求內系統是如何處理,在故障時能夠更好找出原因,圖片取至 Cisco Tech Blog
而 Tracing 到底紀錄了什麼資訊?一個 Trace 其實是由一到多個 Span 所組成,每個 Span 會紀錄事件名稱、開始與結束時間等資料,透過將單一請求所產生出的 Span 統整起來即成為 Trace。
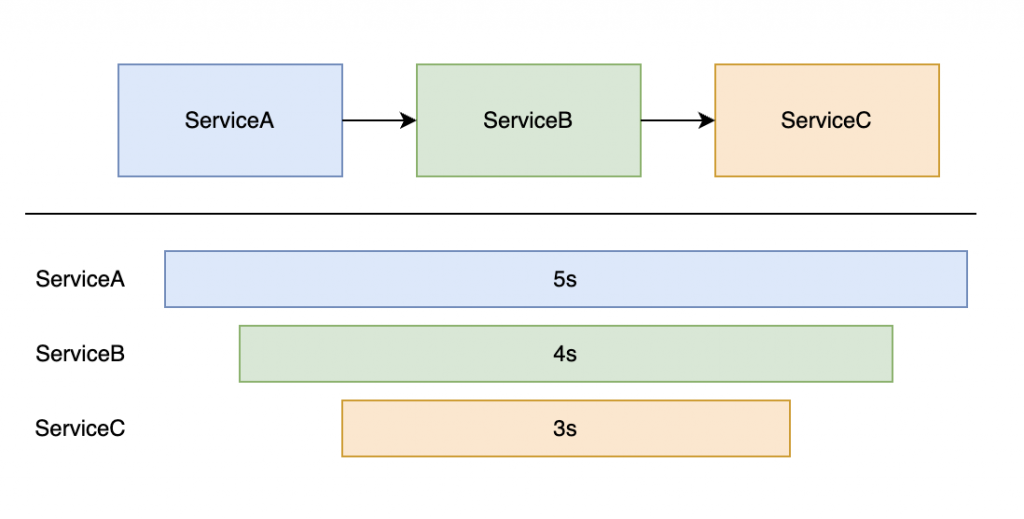
如圖所示,底下單一 Bar 為 Span,合在一起即為 Trace
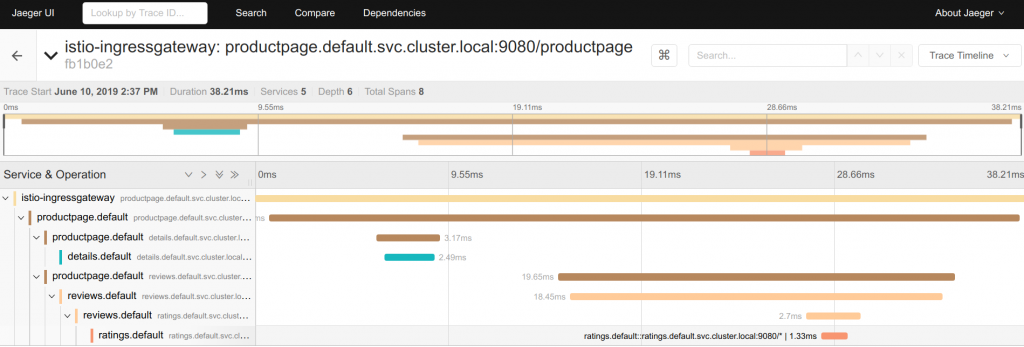
Jaeger UI 呈現的 Tracing 資訊,圖片取至 Istio Document - Jaeger
在 Istio 是如何實現 Distributed Tracing?其實是靠 Sidecar 的 Envoy’s distributed tracing 功能來完成的,Istio 會在每個元件旁都注入 Sidecar, Service 之間的流量都會藉由 Sidecar 來代理,當 Request 進來時,Proxy 就能紀錄每個 Service 產生的 Span ,並在 HTTP Headers 紀錄此次 Request 的獨立 Id,以此就能將分散的 Span 資料形成完整的 Trace。
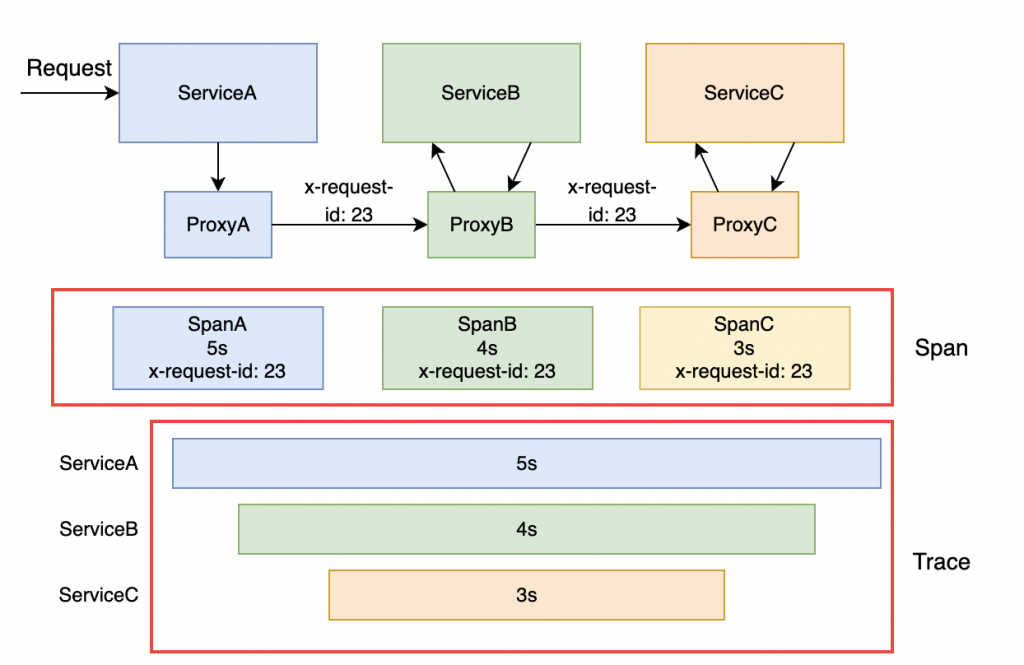
Istio 透過 Sidecar 擷取 Service 間的流量,紀錄 Span 資料,並藉由 HTTP Headers 上的 Request Id 將 Span 統整成 Tracing 資訊。
之前有提到說使用 Istio 不需要改動應用程式即可享有 Service Mesh 的功能,但在 Tracing 時是個例外,雖然 Proxy 能夠設定 Http Headers 紀錄 Request Id,但應用程式若是沒有實作 Headers 相關的規則,傳出來的封包可能就會將這些 Headers 給清除掉,所以在應用程式需要實作 Trace Context Progagation ,簡單講就是讓進入與流出應用程式的流量都能保有 Tracing 所需的 Headers,詳細要如何設定可參考 Istio Document - trace-context-propagation
可以在 Bookinfo Application 中的 productpage.py 原始碼看到 Tracing 所需的 Headers 資料需要在應用程式實作將其保留。
本篇介紹完了 Distributed Tracing 概念,下一篇就來介紹如何使用 Jaeger 工具在 Istio 蒐集 Tracing 資料。

 iThome鐵人賽
iThome鐵人賽