
隨著雲原生服務的發展,越來越多的應用程式逐漸容器化、微服務化,並且搬到雲端服務上執行,雖然能夠讓應用程式擁有可移植性、擴展性方面的好處,卻也讓系統架構變得越來越複雜,當應用程式出問題時,若對系統不夠了解,往往得花好一番功夫解決。

以前應用程式可能是在跑在機房實體機上的一個 Process,當發生問題時,可以從機器或是從應用程式上尋找問題。
現今的雲原生應用程式放在雲端上,並且又掛了一層 Kubernetes ,當發生問題時需要從更多層面去尋找。
在分散式且複雜的應用程式中,要如何讓團隊更好的監控應用程式,就需要提高系統的 Observability (可觀測性),Observability 讓我們更好了解系統發生什麼樣的行為,當問題出現可以迅速的定位,當系統有異常時也能提前示警。提升 Observability 的方式有很多,這裡舉幾種常見的方式
而現今主要的作法,是蒐集系統中的 Metrics、Logging與Tracing三大訊息,並搭配開源軟體如 Prometheus、Fluentd、Jaeger 來實現對系統的資料蒐集、示警、可視化等功能
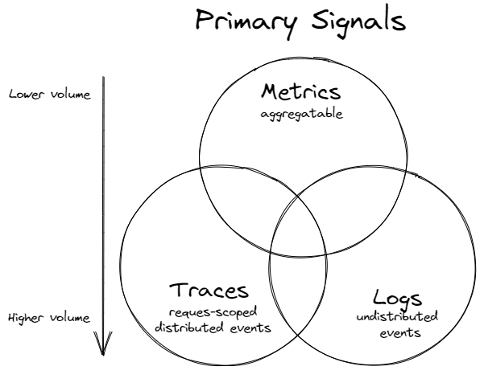
圖片取至 microsoft.github.io
Metrics 代表系統中的數值資料,例如 CPU、Memory 的使用量,或是呼叫 HTTP 請求的次數,將這些資訊根據時間記錄下來,就能了解各個時間時系統的狀況為何。
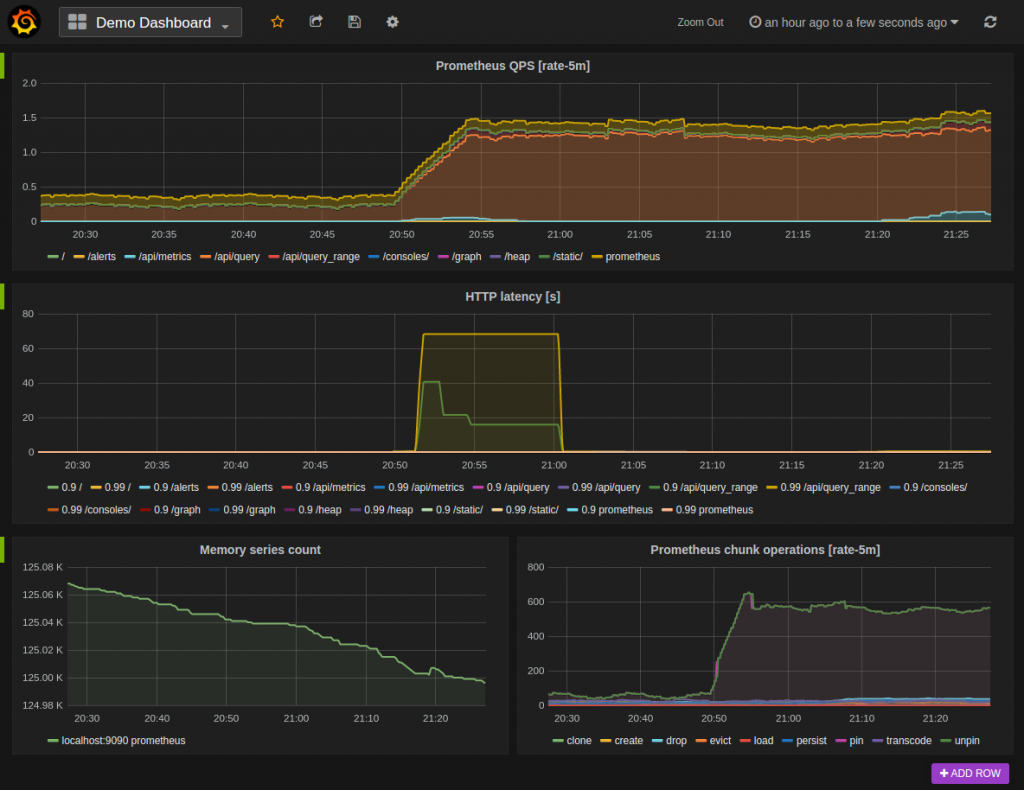
圖片取至 prometheus.io,利用 prometheus 儲存 Metrics 並用 grafana 將資料可視化,就可以建置系統的圖表
Logging 就是應用程式發出的 Logs ,這些資料龐雜且觸發時間不固定,但對於解決問題是非常有用的資訊,需要做的是如何蒐集不同應用程式的 Logs , 讓使用者可以輕鬆方便的查找。
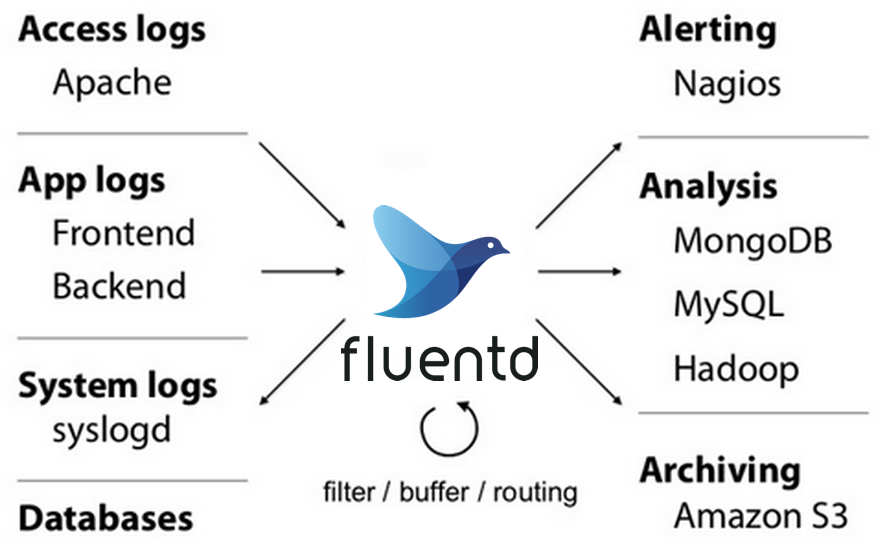
圖片取至 fluentd.org, fluentd 能幫助我們蒐集不同格式的 Logs
Tracing 指的是單次請求範圍內系統的所有數據,如一次 HTTP 請求時經過所有 Microservices 的資料,透過 Tracing 能夠讓我們能更好掌握應用程式效能的瓶頸。
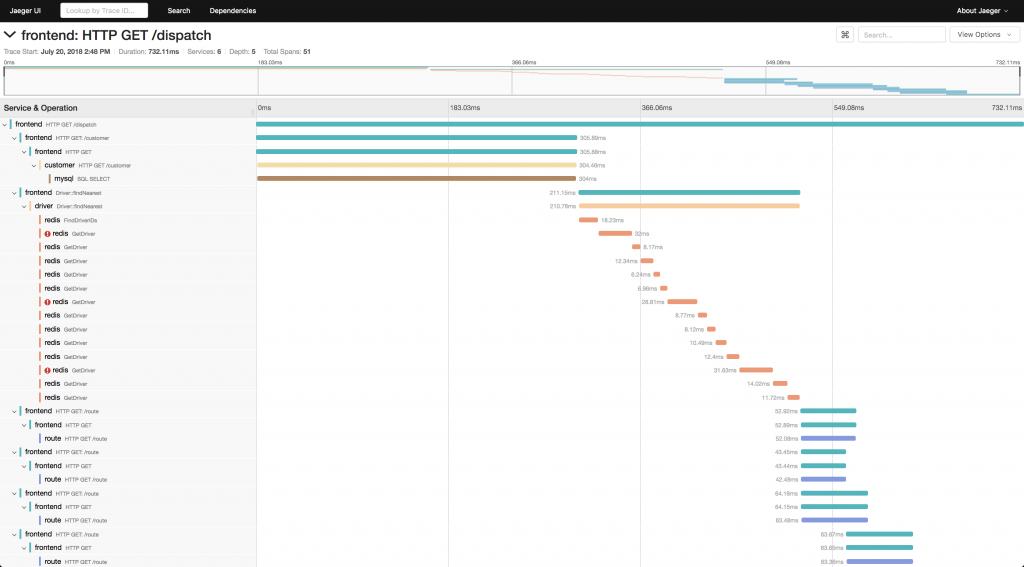
圖片取至 jaegertracing.io,jaeger 能幫助我們可視化 Tracing 資訊
本篇介紹的基礎 Observability 概念,後面幾篇將會使用不同的開源工具,在 Istio 上實現 Observability。

 iThome鐵人賽
iThome鐵人賽