昨天說到loss怪怪的,因此今天我又改了二維資料格式這次改成13x13大小
[12, 50, 38, 36, -1, -1, 32, 47, 4, 78.9, 39.0, 0, 1, 1, 0]
/ | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | J | Q | K | A
------------- | -------------
strength | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 12
flop0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 50
flop1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 38 | 0 | 0 | 0
flop2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 36 | 0 | 0 | 0
flop3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | -1
flop4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | -1
hand0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 32 | 0 | 0 | 0 | 0
hand1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 47 | 0
hands_level | 0 | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
player1_chips | 78.9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
player2_chips | 0 | 39.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
0 1 1 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
隨機亂數防止過度擬合 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
在隨機亂數防止過度擬合這行裡,採用2個隨機亂數分配在前半段與後半段
size[j, random.randrange(0,5,1)] = random.randrange(0,100,1)#防止過度擬合
size[j, random.randrange(5,13,1)] = random.randrange(0,100,1)#防止過度擬合
但是訓練成果依舊不理想,因此又想了,
方法二:batch size過大,原本是64後來改成16。(沒用還是一樣,看來不是這個問題)
方法三:數據集打亂,快速打亂數據。(一樣沒用,看來不是這個問題)
from sklearn.utils import shuffle
x_train, y_train = shuffle(x_train, y_train, random_state=0)
方法四:將activation='relu'改成tanh(一樣沒用,看來不是這個問題......)
有一些說法是relu由於對於很大的數值直接複製,所以會對softmax產生不好的影響,從而輸出不好的結果。所以可以使用tanh代替relu。(參考訓練集準確率很高,驗證集準確率低問題)
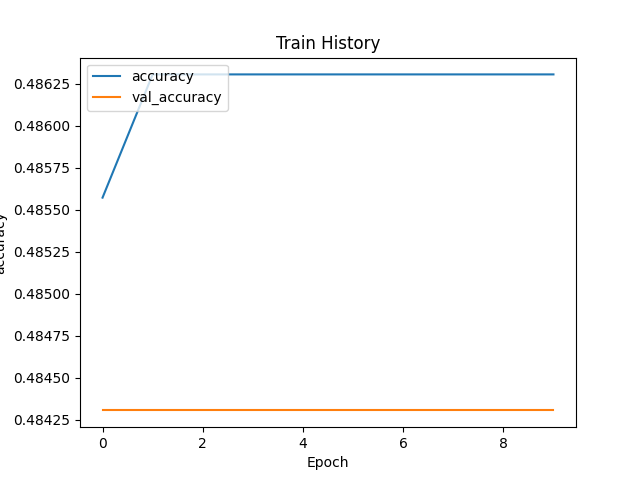
再附上新一次訓練的成果: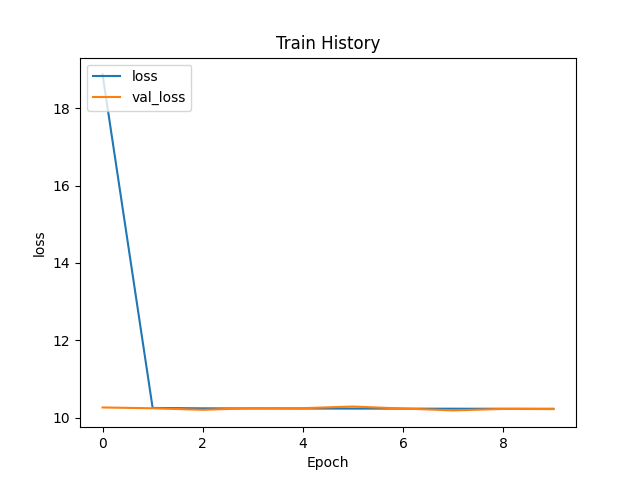


 iThome鐵人賽
iThome鐵人賽