今天要做的是繼續往下爬一頁。
先定義好昨天寫的程式碼,這樣之後只需要呼叫定義就可以執行。
(記得要將url變數移到下面,定義內的程式碼也要記得縮排!)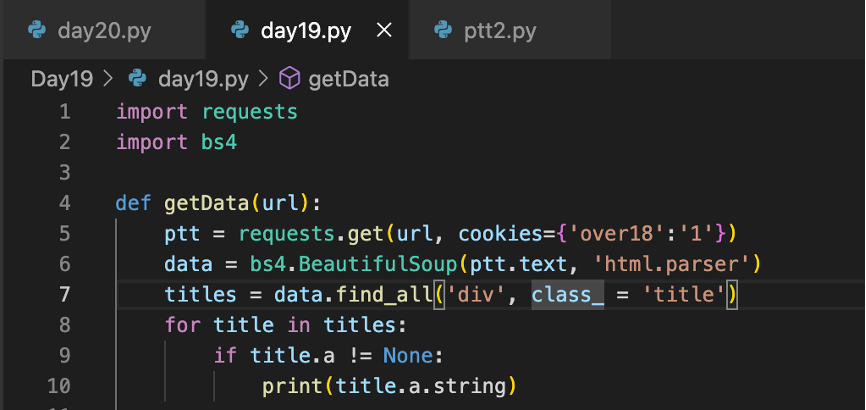
接著我們需要找到上一頁這個按鈕的元素,一樣按下f12
點擊我圈起來的地方之後點選你想查看的那個按鈕。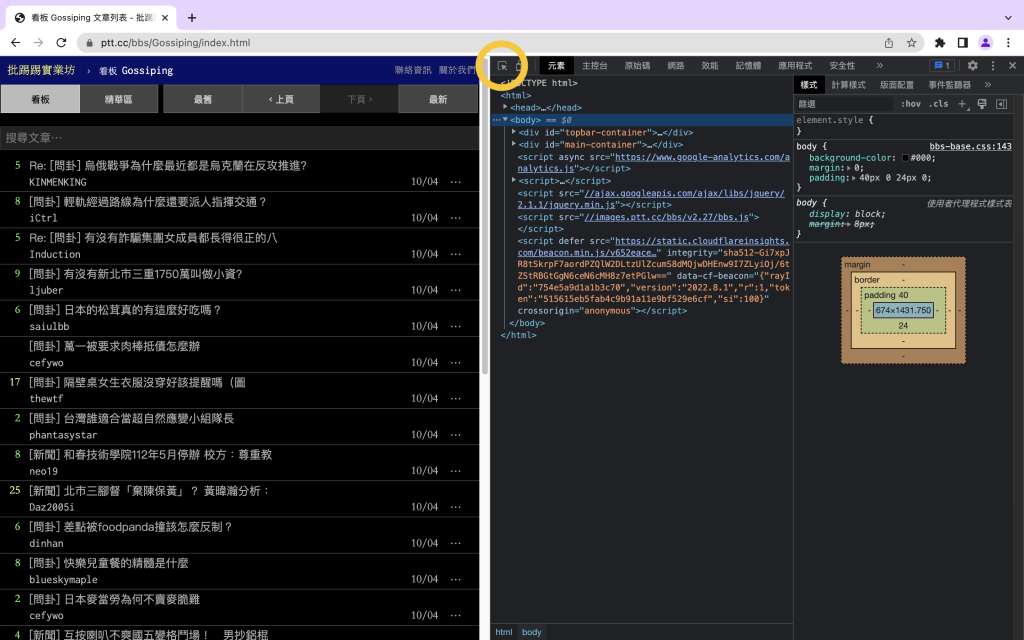
這裡我們想看上一頁這個按鈕的元素,所以就點選上一頁的按鈕。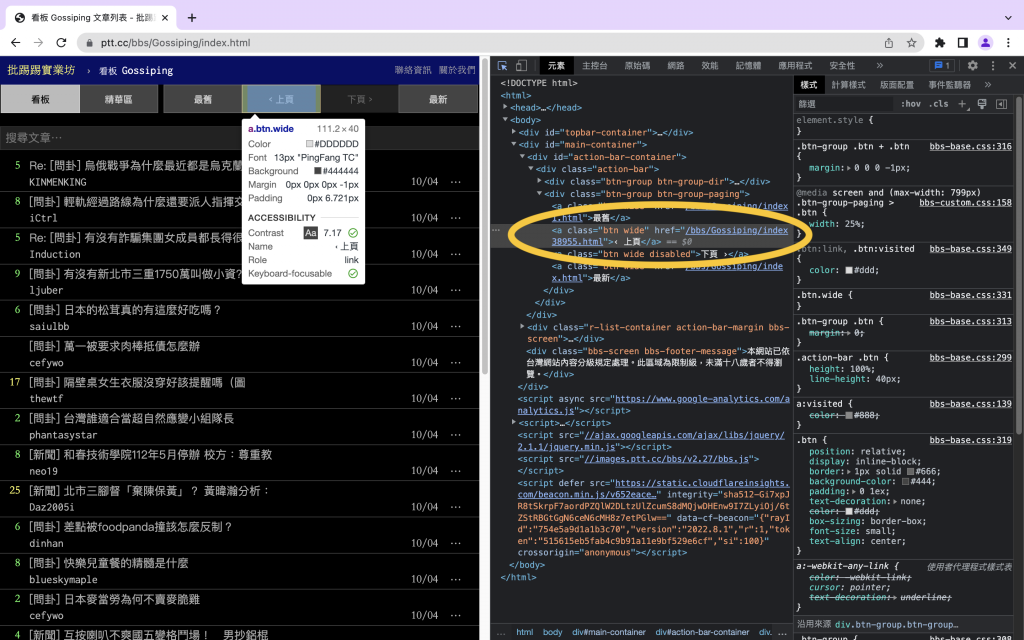
prepage = data.find('a', class_ = 'btn wide', text = '‹ 上頁')
newUrl = 'https://www.ptt.cc' + prepage['href']
return newUrl
最後設下迴圈,如果你想要爬更多頁只要把迴圈次數更改就好。
for i in range(4):
url = getData(url)
input:
import requests
import bs4
def getData(url):
ptt = requests.get(url, cookies={'over18':'1'})
data = bs4.BeautifulSoup(ptt.text, 'html.parser')
titles = data.find_all('div', class_ = 'title')
for title in titles:
if title.a != None:
print(title.a.string)
prepage = data.find('a', class_ = 'btn wide', text = '‹ 上頁')
newUrl = 'https://www.ptt.cc' + prepage['href']
return newUrl
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
for i in range(4):
url = getData(url)
output: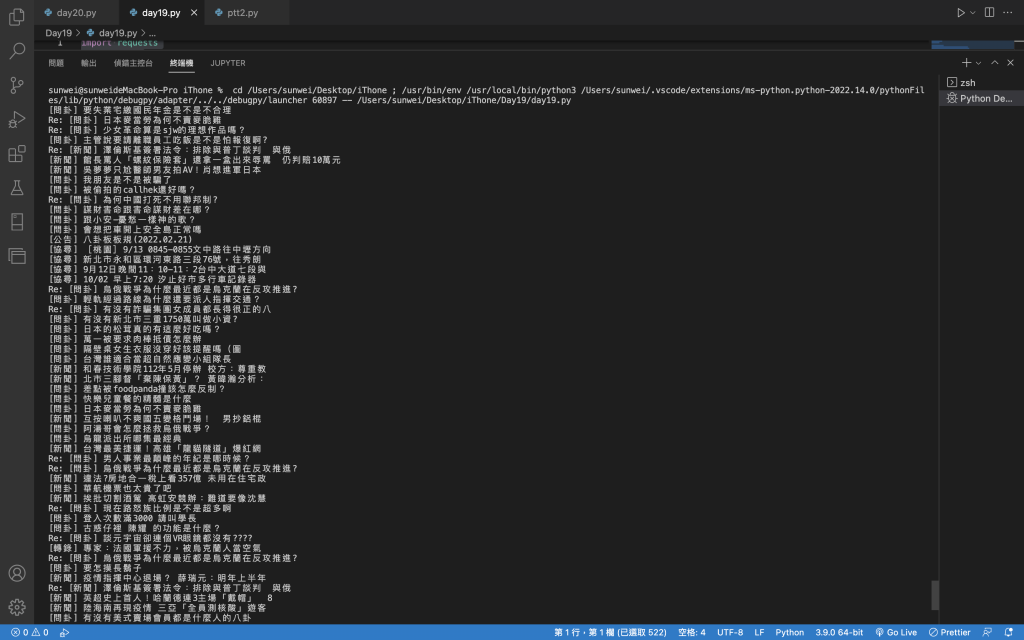
參考書籍:
洪錦魁 -- Python網路爬蟲:大數據擷取、清洗、儲存與分析:王者歸來 2019
林俊瑋, 林修博 --- Python:網路爬蟲與資料分析入門實戰 2018

