今天要做的是把目前的頁面的文章轉成字典,最後將其儲存至.json檔案。
一開始最重要的:
import json
接下就是將文章轉成字典:
articles = []
divs = data.find_all('div', 'r-ent')
for d in divs:
if d.find('a'):
title = d.find('a').text
author = d.find('div', 'author').text
push_num = d.find('div', 'nrec').text
publish_time = d.find('div', 'date').text
articles.append({
'title':title,
'publish_time':publish_time,
'author':author,
'push_num':push_num,
})
最後儲存成json檔案:
fn = 'd20.json'
with open(fn, 'w', encoding='utf-8') as fnObj:
json.dump(articles, fnObj, ensure_ascii= False, indent=2)
執行後會產出一個叫d20.json的檔案(名字可以自己取)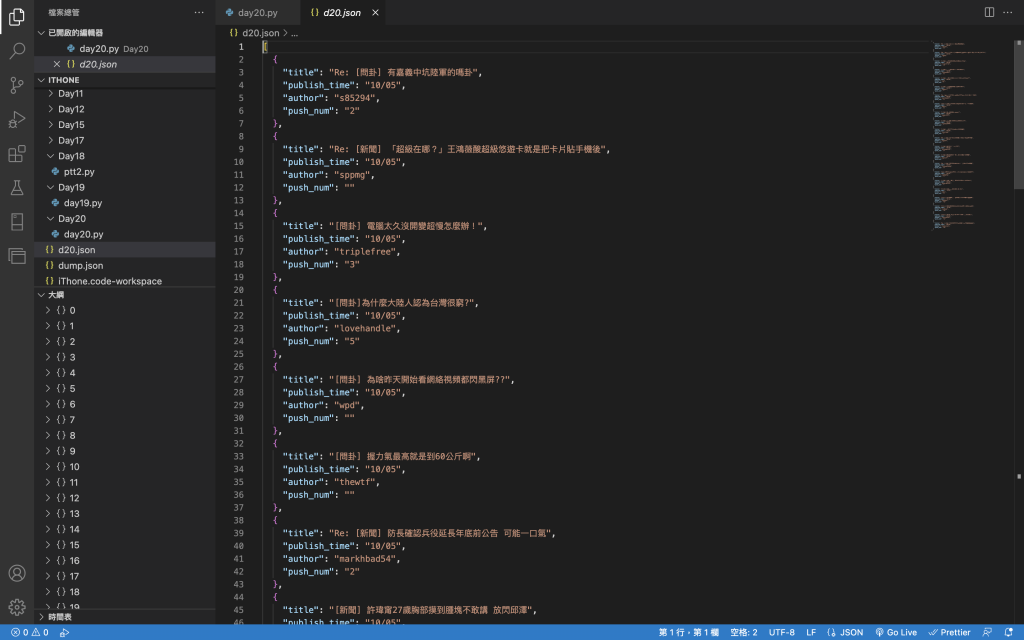
參考書籍:
洪錦魁 -- Python網路爬蟲:大數據擷取、清洗、儲存與分析:王者歸來 2019
林俊瑋, 林修博 --- Python:網路爬蟲與資料分析入門實戰 2018

