昨天最後的結果看起來還是很亂對吧,我們可以用要BeautifulSoup,將我們想要的內容清理出來。可以用檢查功能選取文章,發現文章的元素都放在div.r-ent 裡面。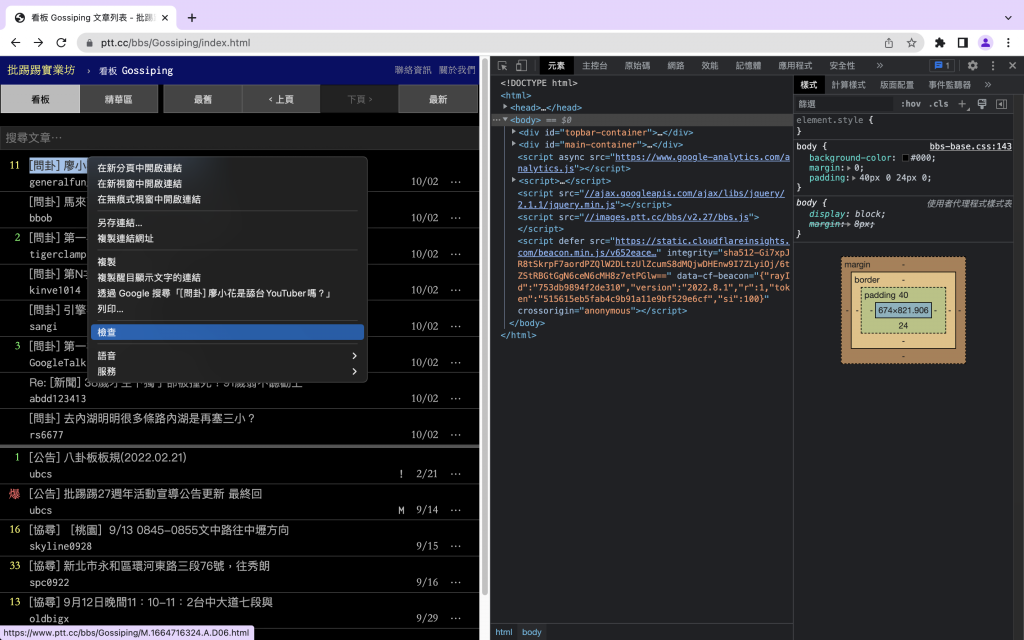
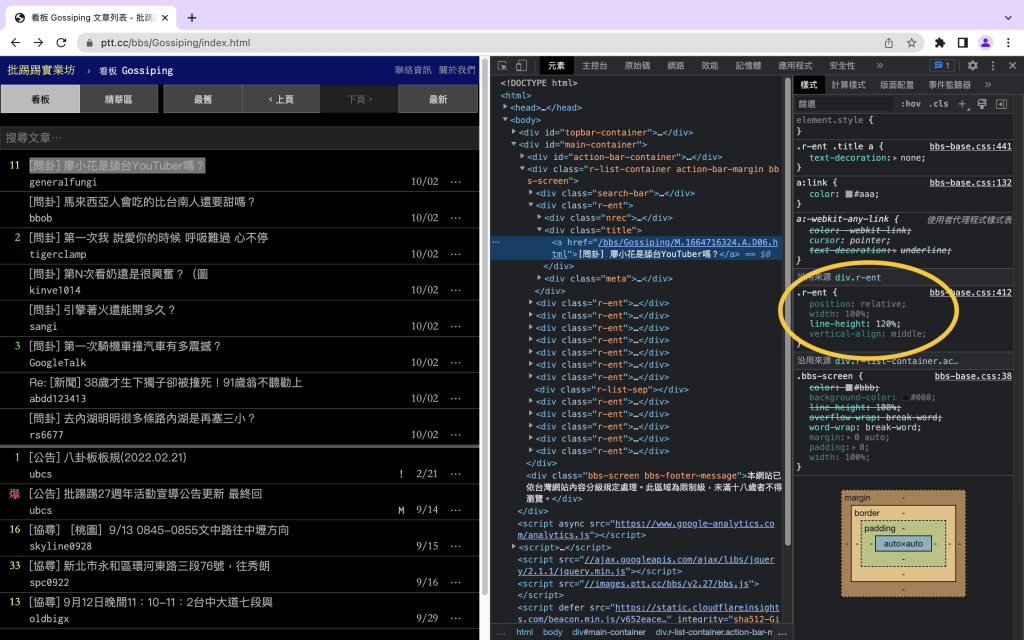
接著就延續昨天的程式碼
import requests
import bs4
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
ptt = requests.get(url, cookies={'over18' : '1'})
data = bs4.BeautifulSoup(ptt.text, 'html.parser')
titles = data.find_all('div', class_ = 'title')
for title in titles:
if title.a != None:
print(title.a.string)
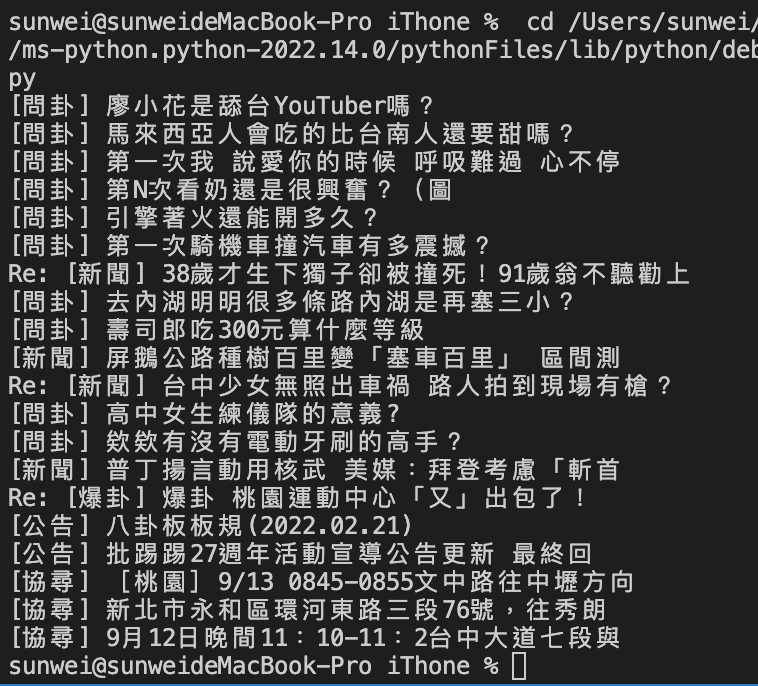
這樣就乾淨多了!!
參考書籍:
洪錦魁 -- Python網路爬蟲:大數據擷取、清洗、儲存與分析:王者歸來 2019
林俊瑋, 林修博 --- Python:網路爬蟲與資料分析入門實戰 2018

