Surprise 可以用來建立及分析協作過濾推薦系統的工具,今天我們來用它來實作矩陣分解 SVD 推薦系統。
我們用的數據集是昨天我們介紹的 Anime Recommendation dataset。
載入資料集到 padas 的 data frame 裡。
import pandas as pd
import numpy
from google.colab import drive
drive.mount('/content/drive')
animes = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/data/dataset/anime recommendation data/anime.csv", engine='python')
ratings = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/data/dataset/anime recommendation data/rating.csv", engine='python')
看一下前10筆資料
ratings.head(10)
得到ratings 的前10 筆資料如下: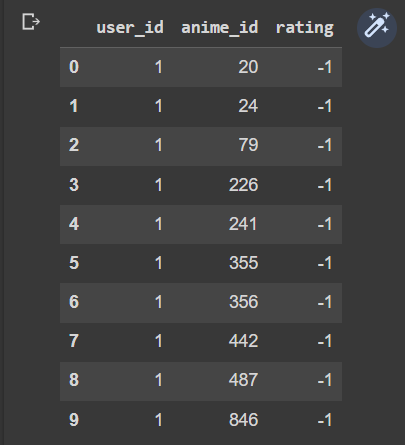
rating 為 -1 表示使用者只有來看,沒有評分。
看一下 ratings 的樣子:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7813737 entries, 0 to 7813736
Data columns (total 3 columns):
# Column Dtype
--- ------ -----
0 user_id int64
1 anime_id int64
2 rating int64
dtypes: int64(3)
memory usage: 178.8 MB
user_id, anime_id, rating 都被 pandas 認成 int64。
為了簡化今天的內容,我們將沒有評分的資料(也就是 rating = -1 的資料)通通刪除。
ratings = ratings.drop(ratings[ratings['rating'] == -1].index)
print(ratings.info())
得到下面的結果:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 6337241 entries, 47 to 7813736
Data columns (total 3 columns):
# Column Dtype
--- ------ -----
0 user_id int64
1 anime_id int64
2 rating int64
dtypes: int64(3)
memory usage: 193.4 MB
又由於資料裡有重複的評分,我們要去掉重複,只留下最新的。
droped_ratings = ratings.drop_duplicates(['user_id', 'anime_id'], keep='last')
print(droped_ratings.info())
就得到
<class 'pandas.core.frame.DataFrame'>
Int64Index: 6337234 entries, 47 to 7813736
Data columns (total 3 columns):
# Column Dtype
--- ------ -----
0 user_id int64
1 anime_id int64
2 rating int64
dtypes: int64(3)
memory usage: 193.4 MB
到這裡,資料準備好了。
安裝 serprise
!pip install surprise
引入相關package
from surprise import Dataset
from surprise import Reader
from surprise import SVD
from surprise import accuracy
from surprise.model_selection import train_test_split
from surprise.model_selection import cross_validate
開始訓練看效果
amount = 1000000 # 因為整個資料集有清理過後,還有 6 百多萬筆資料,為了展示方便,我們先只做100萬筆資料
epochs = 10 # epochs 數量
factors = 50 # 在矩陣分解時,要拆出多少個因子?
reader = Reader(rating_scale=(1, 10)) # 要告訴 suprise ,評分的範圍,這裡指1分到10分。等下要用
ratings_1m = droped_ratings[:amount] # 只拿100萬集資料
data = Dataset.load_from_df(ratings_1m[['user_id', 'anime_id', 'rating']], reader) #只要 3 欄 user, item, rating ,還有reader 要當參數
svd = SVD(verbose=True, n_epochs=epochs, n_factors = factors) # 選擇用SVD法來分解矩陣
cross_validate(svd, data, measures=['RMSE', 'MAE'], cv=3, verbose=True) # 做 3 遍看訓練成果
看訓練成果
Processing epoch 0
Processing epoch 1
Processing epoch 2
...
Processing epoch 9
Evaluating RMSE, MAE of algorithm SVD on 3 split(s).
Fold 1 Fold 2 Fold 3 Mean Std
RMSE (testset) 1.2096 1.2082 1.2057 1.2079 0.0016
MAE (testset) 0.9188 0.9174 0.9155 0.9172 0.0014
Fit time 14.29 15.14 15.08 14.84 0.39
Test time 3.86 2.65 3.69 3.40 0.54
{'test_rmse': array([1.20963929, 1.20819975, 1.20572289]),
'test_mae': array([0.91884906, 0.91736123, 0.91553868]),
'fit_time': (14.292129755020142, 15.13960313796997, 15.076768159866333),
'test_time': (3.8627843856811523, 2.6511662006378174, 3.693979263305664)}
預測 user_id = 3 對 item_id=199,會評幾分
uid = 3 # raw user id (as in the ratings file). They are **strings**!
iid = 199 # raw item id (as in the ratings file). They are **strings**!
# get a prediction for specific users and items.
pred = svd.predict(uid, iid, r_ui=9, verbose=True)
得到
user: 3 item: 199 r_ui = 9.00 est = 9.20 {'was_impossible': False}
看來不錯,四捨五入就對了
SVD 演算法提供許多參數可以調整,重要如下:
我們可以把這些參數放在 param_grid 裡,然後給定每個參數區間,讓 suprise 幫我們找到最佳組合。
from surprise.model_selection import GridSearchCV
param_grid = {"n_epochs": [5, 10], "lr_all": [0.002, 0.005], "n_factors": [50, 100,150]}
gs = GridSearchCV(SVD, param_grid, measures=["rmse", "mae"], cv=3, joblib_verbose=1, n_jobs=2)
gs.fit(data)
# 找出最好的 RMSE 分數
print(gs.best_score["rmse"])
# 印出最好的參數組合
print(gs.best_params["rmse"])
結果如下:
[Parallel(n_jobs=2)]: Using backend LokyBackend with 2 concurrent workers.
1.2061696137970779
{'n_epochs': 10, 'lr_all': 0.005, 'n_factors': 100}
[Parallel(n_jobs=2)]: Done 36 out of 36 | elapsed: 9.1min finished
拿最好的參數組合,重新做訓練及計算分數
# 找到最佳參數組合後,拿它來重訓練
algo = gs.best_estimator["rmse"]
trainset = data.build_full_trainset()
algo.fit(trainset)
predictions = algo.test(trainset.build_testset())
accuracy.rmse(predictions)
得到
RMSE: 0.9906 0.9905950115060409
用 Surprise 來實作評分表類型的協作過濾非常的簡單
參考資料:


 iThome鐵人賽
iThome鐵人賽