接續此系列,前兩天分別架設了環境可以重現於 EKS 環境 rolling update deployment 使用 ALB 作為 Ingress endpoint 會遭遇到 HTTP 502 錯誤。將探討要如何解決此問題。
由昨天流程可以知道 container process 接受到 SIGTERM signal 之後,如 Nginx 或是 Apache 網頁服務器,就不會再接收新的連線請求。container process 終止的速度遠快於 Load Balancer 取消註冊(deregister)此 Pod Target。為了讓 AWS Load Balancer Controller 接收 Endpoints Controller 更新後,可以有足夠的時間取消註冊 target(執行並完成 DeregisterTargets API ),故我們可以調整以下 Pod spec :
根據 Kubernetes Pod Lifecycle [1],當 Pod 要被刪除時會由 kubelet 觸發 Container runtime 發出 SIGTERM signal 給每一個 Pod 內 container 的 process 1,倘若超出了 terminationGracePeriodSeconds 所設定時間(預設 30 秒),則會發出 SIGKILL signal 強制終止 process 而造成不預期的錯誤。若其中 Container 中定義使用了 preStop hook,kubelet 會執行完 preStop hook [2] 後才會發出 SIGTERM signal。
如以下範例使用 sleep 命令保留 70 秒使可以先直執行 DeregisterTargets API。
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 70"]
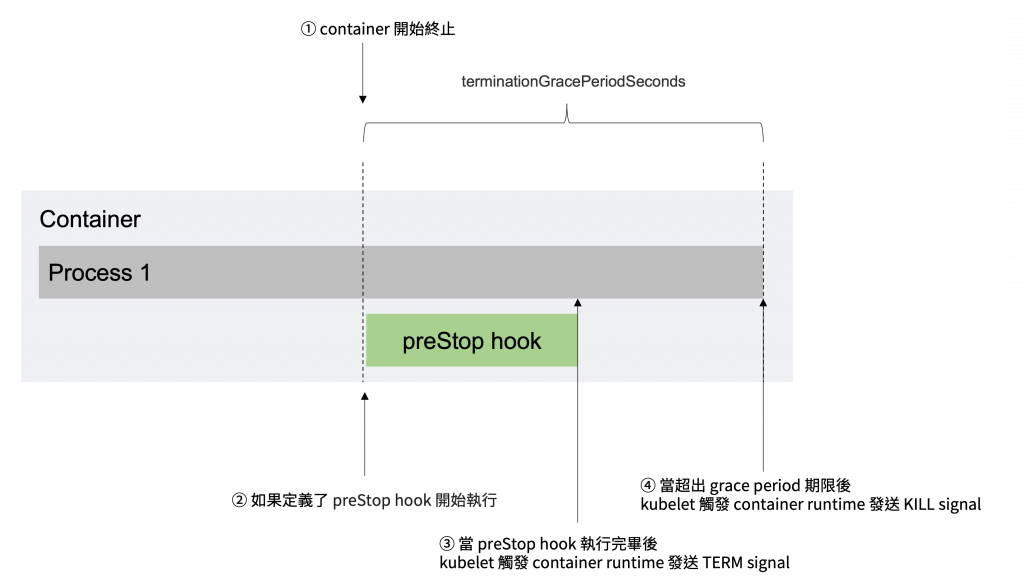
預設 terminationGracePeriodSeconds 時間僅 30 秒時間,其中包含了 preStop hook 所執行時間,倘若我們透過 sleep 命令定義超過 30 秒,我們則需要延長 terminationGracePeriodSeconds 時間,如以下範例,將 terminationGracePeriodSeconds 時間延長至 90 秒時間,允許 preStop 執行 sleep 命令 70 秒,在額外延長 20 秒時間,以確保應用程序可以正常關閉。
spec:
terminationGracePeriodSeconds: 90
containers:
- name: nginx
image: nginx:latest
[...]
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 70"]
sleep 究竟需要多久的時間?於 AWS Load Balancer Controller GitHub issue - How can we find right value of sleep time for zero downtime rolling update? [3],controller 開發團隊成員回覆:
controller process time:依據 EKS cluster 的大小或 loading 狀況而定,可由 controller metrics 查看。ELB API propagation time:與 ELB 團隊確認過,他們沒有 P99 metrics。 但對於 ALB,它應該小於 60 秒。HTTP req/resp RTT:依據應用程式而定。kubeproxy's iptable update time:一般而言,介於 10~30 秒,其上限定為 30 秒。總體來說,仍需要依據 EKS 使用狀況及應用服務於 Pod 上的終止、HTTP 響應時間最佳化。
aws-load-balancer-controller 預設提供了 metrics-server 於 8080 port 上。$ kubectl -n kube-system get deploy aws-load-balancer-controller -o yaml
...
...
containers:
- args:
- --cluster-name=ironman-2022
- --ingress-class=alb
command:
- /controller
image: 602401143452.dkr.ecr.us-west-2.amazonaws.com/amazon/aws-load-balancer-controller: v2.4.3
...
...
name: aws-load-balancer-controller
ports:
- containerPort: 9443
name: webhook-server
protocol: TCP
- containerPort: 8080
name: metrics-server
protocol: TCP
resources: {}
$ cat ./aws-load-balancer-prometheus-service.yaml
apiVersion: v1
kind: Service
metadata:
name: "aws-load-balancer-prometheus-service"
namespace: "kube-system"
spec:
type: NodePort
ports:
- name: prometheus-service
port: 8080
targetPort: 8080
protocol: TCP
nodePort: 30000
selector:
app.kubernetes.io/instance: aws-load-balancer-controller
app.kubernetes.io/name: aws-load-balancer-controller
[ec2-user@ip-192-168-63-79 ~]$ curl localhost:30000/metrics
...
...
...
# HELP workqueue_unfinished_work_seconds How many seconds of work has been done that is in progress and hasn't been observed by work_duration. Large values indicate stuck threads. One can deduce the number of stuck threads by observing the rate at which this increases.
# TYPE workqueue_unfinished_work_seconds gauge
workqueue_unfinished_work_seconds{name="ingress"} 0
workqueue_unfinished_work_seconds{name="service"} 0
workqueue_unfinished_work_seconds{name="targetGroupBinding"} 0
# HELP workqueue_work_duration_seconds How long in seconds processing an item from workqueue takes.
# TYPE workqueue_work_duration_seconds histogram
workqueue_work_duration_seconds_bucket{name="ingress",le="1e-08"} 0
workqueue_work_duration_seconds_bucket{name="ingress",le="1e-07"} 0
workqueue_work_duration_seconds_bucket{name="ingress",le="1e-06"} 0
workqueue_work_duration_seconds_bucket{name="ingress",le="9.999999999999999e-06"} 0
workqueue_work_duration_seconds_bucket{name="ingress",le="9.999999999999999e-05"} 0
Kubernetes 於 1.14 新增了 Readiness Gates [4] 功能,提供額外的 signal 作為 Pod status.condition。AWS Load Balancer Controller 基於此 upstream Kubernetes Readiness Gates 功能,將 ALB/NLB Target Group 健康檢查狀態注入於 Pod 的 status.condition 欄位。當新增的 Pod 註冊於 ALB/NLB Target Group 後,並健康檢查被更新為「健康」狀態後,Pod status.condition 才會被更新為 True。以下為啟用 Pod Readiness Gates 步驟:
elbv2.k8s.aws/pod-readiness-gate-inject=enabled。$ kubectl label namespace demo-nginx elbv2.k8s.aws/pod-readiness-gate-inject=enabled
namespace/demo-nginx labeled
$ kubectl describe namespace demo-nginx
Name: demo-nginx
Labels: elbv2.k8s.aws/pod-readiness-gate-inject=enabled
kubernetes.io/metadata.name=demo-nginx
Annotations: <none>
Status: Active
No resource quota.
No LimitRange resource.
$ kubectl -n demo-nginx rollout restart deploy demo-nginx-deployment
deployment.apps/demo-nginx-deployment restarted
status.conditions 查看到 ELB 註冊的 target group 的狀況。$ kubectl -n demo-nginx get po demo-nginx-deployment-6ff58f7b67-4kz2x -o yaml | grep -B7 'type: target-health'
status:
conditions:
- lastProbeTime: null
lastTransitionTime: null
message: Target registration is in progress
reason: Elb.RegistrationInProgress
status: "True"
type: target-health.elbv2.k8s.aws/k8s-demongin-serviced-610dd2305f
本文探討了兩種方式解決 ALB 遇到 HTTP 502 的可能性:
preStop 搭配 terminationGracePeriodSeconds:設定 preStop hook sleep 命令確保 Pod 終止前 ELB 可以有充足時間取消註冊 target。其中 controller
