前幾天,我爸突然問我說,excel有沒有辦法自己幫我更新某幾個特定欄位阿,不然我每天自己手動填那些股票的收盤價好累喔,原本我以為可能五六隻而已,結果一看才發現,是五六十支,看來,又是一個學習的機會了!
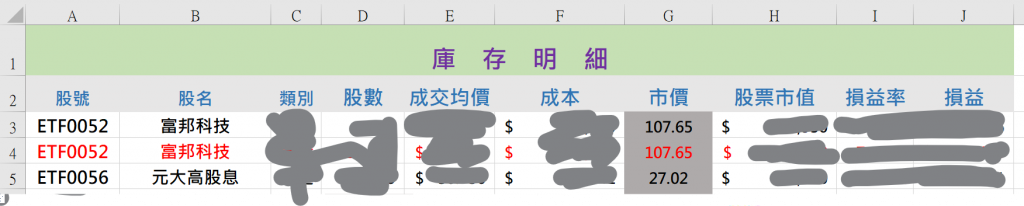
先看一下他自己設計的表格,我計畫是先抓取股號那一欄 ( A ) 的資料去爬蟲後再把爬到的資料塞到市價 ( G ) 對應的那一欄。
這邊一開始看不是很懂沒關係,只是之後會用到必須先設定
url = "https://tw.stock.yahoo.com/quote/" # 奇摩股市url
targetfile = '投資總表.xlsx' # 目標檔案
targetsheet = '庫存股票' # 目標工作表名稱
targetnumber = '' # 目標股號
column = 1 # 工作表目標 欄
targetrow = 3 # 工作表目標 列
pricecol = 7 # 目標股價 欄
excel的欄雖然在使用excel的時候是A、B、C、D這樣的表示方法,不過在openpyxl選擇第幾欄還是使用數字,並且是從 1 開始。
import openpyxl
需要用的的python套件是openpyxl,這個套件可以建立、開啟、讀寫、儲存excel檔案
注意 老的excel版本openpyxl可能無法支援,但具體要多新我並沒有去查。
# 開檔案
workbook = openpyxl.load_workbook(targetfile)
workbook指的是一個excel檔案,targetfile需要填入欲讀取的檔案名稱,不在同一資料夾的話要給予相對路徑。
# 抓到所有資料表
sheet = workbook.worksheets
sheetlength = len(sheet)
# 搜尋所有資料表的名字假如與targetsheet相同就跳出去執行搜尋股價的程式
for targetsheetnumber in range(0,sheetlength):
if sheet[targetsheetnumber].title==targetsheet:
break
sheet為工作表,在這邊因為我不確定未來會不會再增加其他的表在目標的前後,所以先讀取所有工作表再去比對我要的是哪一個。
搜尋是由大而小搜尋抓到檔案之後先找到目標工作表 ( targetsheet ) ,當找到想要的 title 之後就立刻跳出 ( break ) 此迴圈往下走。
# 台股總共971支(應該)不會紀錄超過這個range
for row in range(targetrow,900):
# 如果為空單位即停止搜尋
if sheet[targetsheetnumber].cell(row,column).value==None:
break
從 row = 3 開始搜尋,儲存格的內容讀取方式是 .value 。
# 讀取儲存格資料強制字串化
targetnumber = str(sheet[targetsheetnumber].cell(row,column).value)
# strip()去除前後空白 split('ETF')分割資料為純str(數字) 並且只留下股號的部分
targetnumber = targetnumber.strip().split('ETF')
targetnumber = targetnumber[len(targetnumber)-1]
需要強制字串化是因為excel會有預設數字的問題,可能在讀到資料後把向 0050 變成 50 從而導致之後的爬蟲失敗。
為確保爬蟲時的url正確,首先先把空白去除乾淨,並且在紀錄時可能會有ETF紀錄的出現,必須先行濾除只留下股號,最後因為 split( ) 會讓原本一個字串變成兩個陣列所以只選取最後一個陣列資料存進 targetnumber。
# 必須import
import requests
# 整理 html 必須的套件
from bs4 import BeautifulSoup
# 要求資料requests.get(url , headers , timeout) , headers timeout逾期時長為選填
r = requests.get(str(url)+str(targetnumber), timeout=5)
把前置作業做完之後就來到了爬蟲時刻。
# 如果成功要求到資料則執行
if r.status_code == 200:
# 整理
soup = BeautifulSoup(r.text,"html.parser").select("#atomic .Fz\(32px\)")
# 取出數字輸出
for price in soup:
price = price.text
print(targetnumber , price)
# 目標股價儲存格更改
sheet[targetsheetnumber].cell(row,pricecol).value=float(price)
else:
print(targetnumber , "未讀取到資料")
sheet[targetsheetnumber].cell(row,pricecol).value="-"
Beautifulsoup 想必有再用爬蟲的人都不陌生,整理一個漂亮的 html 不香嗎。
else 的部分是如果沒有 get 成功會先在 cmd 視窗裡顯現並且在儲存格理儲存一個 " - "。
workbook.save(targetfile)
!!!絕對要記得!!!,這是最重要的一步,沒有做儲存,前面的爬蟲阿處理阿全部都沒用。
把這些東西都搞定測試完之後我又再去搜尋python 台灣股市爬蟲,結果發現有一個專門的套件可以爬台灣歷史股市,叫做twstock,瞬間覺得我幹嘛這麼累,哈哈哈哈哈哈。
請問為什麼不抓證交所與櫃買中心的API呢?
他感覺就菜鳥吧 亂搞一通XD
主要是我都搞定之後我才看到證交所有開放API
我的確真的菜
就跟我名字後面的稱號一樣新手五級
先感謝cdj500 coding撰寫的想法提供
以及jason07對於本文及本人的評論
這兩天花了點時間研究了一下
這是我找到的證交所api
裡面有非常多不一樣的資料
但是在使用上他沒辦法顯示當天(例如現在2/17 11:30)的股價
給予的資料都是歷史股市紀錄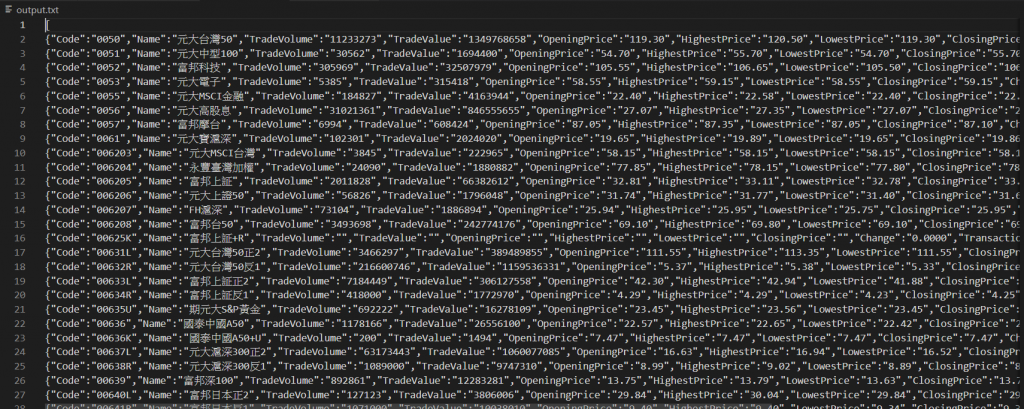
只是我的需求是要顯示當下的個股股市價格
所以這個 api 比較不適用我這個小專案
或是說有甚麼其他的 api 可以抓到當下的股價呢?
 走得歪七扭八的孩子
走得歪七扭八的孩子

 iThome鐵人賽
iThome鐵人賽