在上一篇文章中介紹了基本的監控系統,並簡單帶到在發生警報時值班工程師的必須要做到的行動。這篇文章主要會介紹比較詳細的警報SOP,以及設置警報時的各種考量。
我們的警報按照嚴重程度,主要分成P0、P1、P2和normal這4種等級。每個等級都有一個對應的Slack頻道來接收訊息。
這些警報頻道,各自的設計邏輯如下:
以一個P0警報的範例如下圖
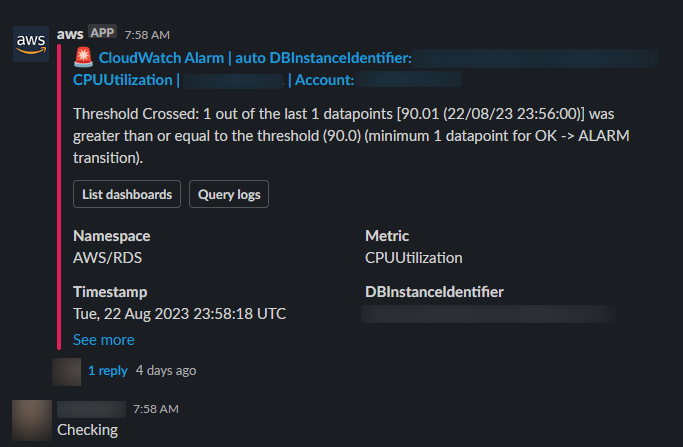
在這個P0警報的範例中,我們的其中一台資料庫伺服器發生了CPU大於90%的狀況,可以在下面看到,我們盡責的值班工程師在1分鐘內就已經回報「正在查看」的訊息。
一般而言,值班工程師本人在處理完系統問題並確認回歸正常後,只要在頻道中告知大家即可。但有些時候會發生嚴重影響服務,且無法馬上處理的狀況。這個時候我們就會將P0警報升級為P0事件。
在一個P0事件中,會由執班的維運產品經理(Operation Product Manager,或OPM)主持這個緊急會議。執班的SRE工程師在處理問題的同時,OPM會負責協調整個處理流程,比如協助聯繫客戶和其它工程師,並負責各種資訊的傳達等等。
提個外話,從筆者的角度來看,OPM在緊急會議當下要做的事情不只繁雜,還可能要在理解技術問題之後,透過不同的語言來進行資訊的傳遞,也實在是相當不容易。
而我們身為SRE工程師在此時,可以的話也會盡可能用比較簡單的方式來解釋系統狀況,避開難以理解的詞彙來讓OPM能夠正確傳達資訊。
但筆者也有遇過資訊實在太過複雜,導致必須跳過OPM,直接與客戶口頭解釋的狀況。這部分也會在之後「重大P0事件」的系列中與大家分享。
因為發生P0警報或事件的當下,通常會處於非常混亂的狀況,因此一開始在設計相關警報的時候,通常我們就會盡可能去遵循某些原則,來幫助值班工程師釐清當下的狀況。
比如說,在設置警報的時候,我們一定會先詢問以下2個問題:
就第一點而言,如果一個警報在觸發之後,值班工程師根本就沒有事情可以做,那顯然就沒有設置該警報的需要。比如在有自動擴展的前提下,如果針對單一伺服器設置警報,那值班工程師能夠做的也就只有等待自動擴展去新增新的機器而已。
就第二點而言,在觸發之後,因為後續行動太過複雜而導致執班工程師其實無力完成,或容易出錯,那我們也應該要盡可能簡化流程。這邊的狀況通常是在說,某些客製化的功能因為太過複雜而需要開發該功能的工程師團隊協助才能處理。
但SRE團隊做為第一線的處理團隊,有時候也可以稍微協助做一些初步的問題排察。這時候我們SRE就可能會需要對方提供比較簡單的工具來協助讓我們在出事的時候使用,而該工具不能因為太複雜而難以操作,導致最後我們還是需要請對方團隊處理。
總而言之,這一連串的警報設定,主要的目的還是希望盡可能避免工程師人力的浪費,希望工程師能夠把時間花在真正能發揮價值的地方。事實上,我們也有針對這些警報的設定去做過一系列的調整。這之後也會在「重大P0事件」的系列中再與大家分享。
值得一提的是,筆者做為一個超級菜鳥剛進公司的時候,才第二週就因為不小心誤觸警鈴而被另一個團隊的主管電翻。當時還以為馬上就要待不下去了XD。現在回想起來,真的還是非常感謝自己團隊的主管與同事們的包容。
雖然讀者看到現在,也許會覺得接P0警報實在是一件有夠恐怖的事情,尤其在夜深人靜的時候,只有一個人在默默處理看不懂發生什麼問題的警報的時候,這種感覺特別嚴重。但實際上,筆者做到現在大概一年多,還是覺得SRE是一份非常有趣的工作。希望在接下來的文章中說明,能夠成功地傳達它有趣和吸引人的地方給讀者們。


 iThome鐵人賽
iThome鐵人賽