之前的文章有提到了基本的監控系統,接下來會是介紹為了專案各自的狀況而建立的特別監控系統。
首先是監控客戶系統的部分,背景故事其實相當單純。我們的系統在登入的功能上透過客戶的 API Gateway (APIGW),來與客戶的系統進行串接。
換個說法來講,如果今天客戶的系統出現了問題,那我們服務上面的使用者就會無法登入。為了快速排查問題,我們有必要對客戶的系統進行監控,以避免問題發生的時候我們找了半天才發現其實是客戶的問題。而我們原本的監控系統是針對我們的AWS帳號裡面的資源,因此就無法直接套用在該狀況中。
然而,我們一開始使用的監控方式被客戶給否決了,因此我們必須建置一個新的監控系統,在符合客戶預期的同時也要有辦法達成當初監控的需求,才能取代舊的監控系統。
請看下圖,是我們原本的監控系統:
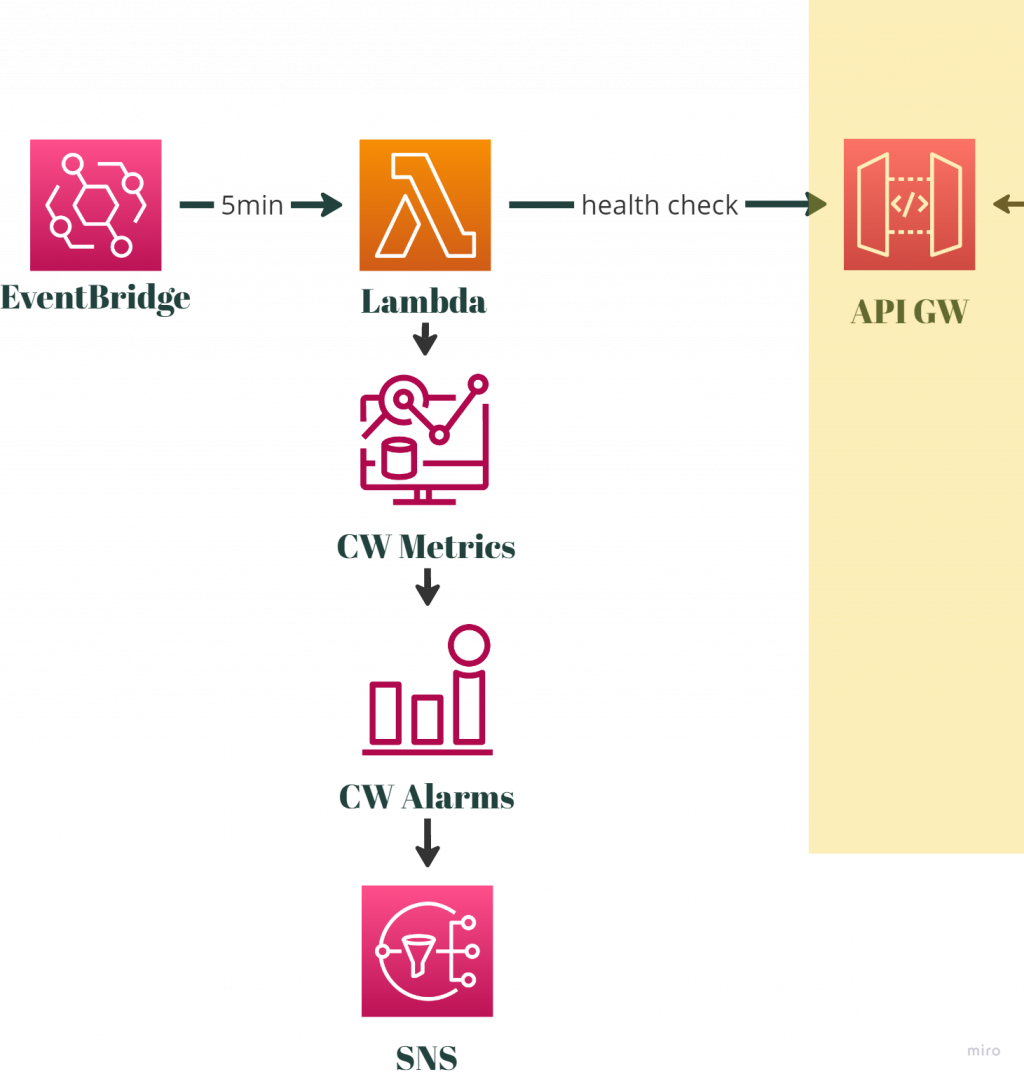
在這張示意圖裡面,右邊是客戶的系統,並透過 APIGW 的一個 endpoint 來對外開放。左半邊是我們舊的監控系統,該系統透過 Lambda 來針對 APIGW 進行健康度檢查(health check),並透過 EventBridge 來每5分鐘觸發一次檢查機制。同時我們也會把健康檢查的狀況定期傳送到 CloudWatch 做成 metrics 。
假設我們檢查到無法存取(APIGW壞掉)的狀況,CloudWatch metrics 就會出現異常的訊息,我們再透過 CloudWatch Alarm 來把訊息轉發給 SNS。後面就蹲循第一篇文章中有講過的,基本監控系統後面的老路。
至於這個監控系統為什麼不被客戶接受呢?主要是因為他們不希望有一種被監控的感覺。雖然我們也曾經試圖提出降低頻率(每10分鐘)監控一次的請求,但最後還是被全盤否決了。
無論這個請求是否合理,也許客戶有一些自己的考量,但因為這是客戶的要求,我們就必須要想出一個替代性的解決方案來處理這個問題。
這邊的思考邏輯是這樣,客戶的要求是希望我們不要以監控為目的,來主動向他們的服務發出請求,但是日常串接上時所發出的請求是完全沒有任何問題的。因此我們就會必須從後者,也就是已經存在的串接上面去下手。
下圖是我們目前現有已經存在的架構:
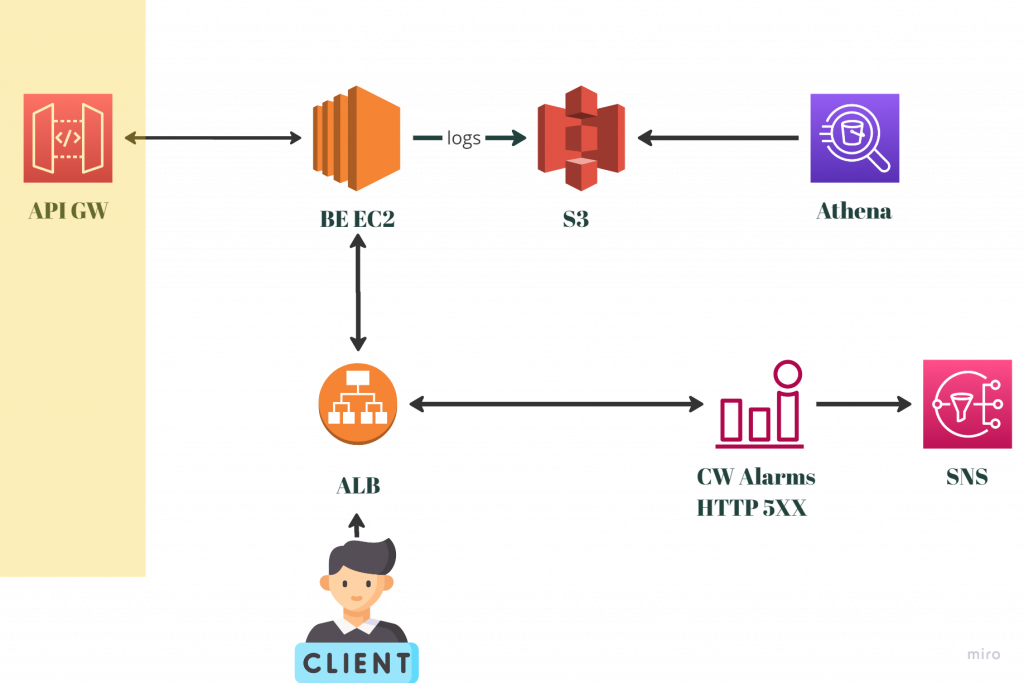
一般的使用者如果要登入,前端伺服器(圖中的CLIENT)會透過ALB(當然有經過DNS Routing)來存取後端EC2,該EC2會再向APIGW發出請求,成功驗證後使用者就可以正常登入。與此同時,EC2的所有日誌都會再存到S3中,並已經做成Athena Table供問題排察。
另外,在基本監控系統裡面,本來就已經有針對ALB本身有監控。當我們的ALB回應過多數量的5XX HTTP Status Code的時候,就會觸發警報。
以上面的架構為基礎,我們做出了如下圖的監控系統:
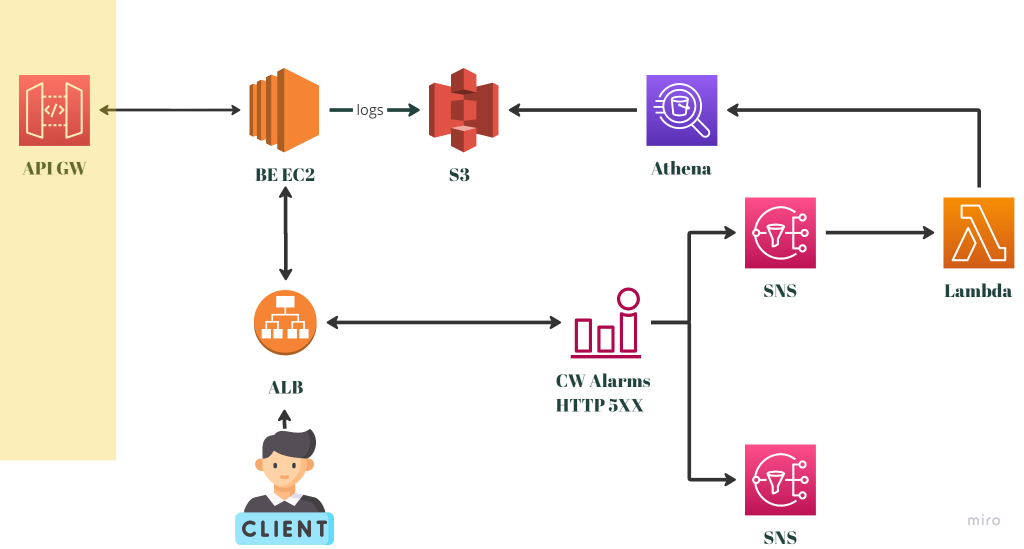
與前一張圖相比比較不一樣的地方,是CloudWatch Alarm在觸發後,多了一個SNS的訊息傳遞對象,接上Lambda後,會對已經建立好的Athena Table下一組Athena Query。
我們請後端工程師協助修改程式,在APIGW出問題的時候,把相關的日誌傳到S3保存。前面提到的Athena Query,就是用來判斷APIGW是否出問題的指令。假設下完指令後發現的確有問題,該Lambda就會再把訊息傳給出去給值班工程師,協助工程師判斷現在的系統狀況。
而整個監控系統的觸發有一個大前提,就是5XX HTTP Status Code的警報要先觸發。因為我們預期APIGW出問題而導致無法登入的時候,後端伺服器會吐出大量的5XX。
在這裡當然也可以有另一種做法,就是我們一樣透過EventBridge來每5分鐘要求Lambda來下指令,但這樣顯示會有費用上的疑慮。因為Athena Query跟據搜尋的資料範圍來計價。而我們存放所有的系統日誌,因此搜尋的量非常的大的情況之下,我們會希望能夠節省一些成本。
這邊還可以一提個外話,就筆者自己的認知而言,因為Athena Query其實目的是為了事後做資料分析用的,一開始就不是一個適合用來監控的服務。因此就架構上來講這邊如果請後端在程式面,直接串接CloudWatch Metrics,可能會是更好的方法。
但在現有的架構上,我們當初就是設計把日誌全部透過Fluentd來傳到S3的前提之下,我們最終還是選擇了一個不要與原本架構差異太大的方式。如下圖:
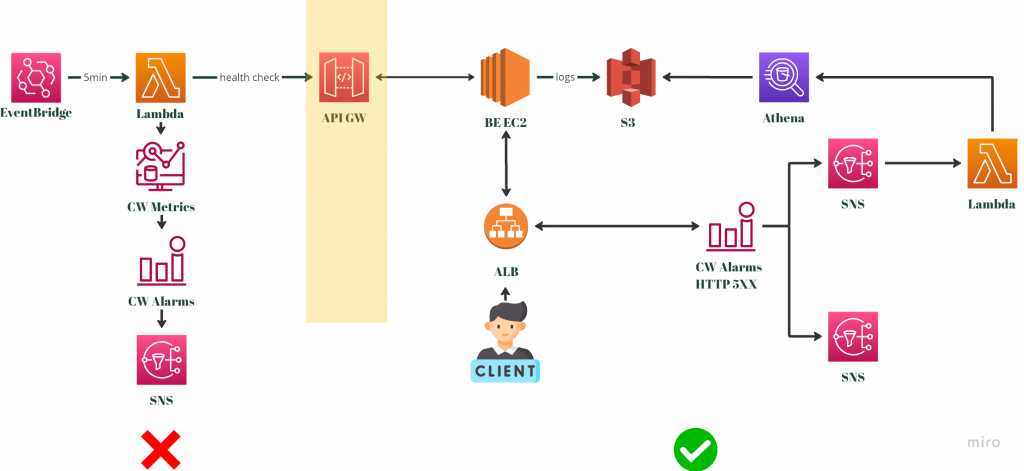
針對一個監控系統的做法可以是很多元的,這完全取決於當下的狀況來去判斷,事實上在最一開始的討論中,也曾經有想過在APIGW以及BE EC2中間加一層伺服器。跟APIGW有關的錯誤就在該伺服器中處理即可。
這對後端工程師來說自然是利多,因為他們可能從頭到尾只要修改endpoint的名字就可以了。不過在整體權衡之後,要維護一個新的伺服器的成本實在太高,比如該伺服器如果壞掉的話,那也直接會影響到我們的服務。變成是我們還得要再多監控那個伺服器本人才行。因此最後就沒有採用這個方案。
這邊提到了在建置這個監控系統時的各種狀況與討論,但實際上這個監控系統之後證實是無效的,留待下一篇文章再來分享。


 iThome鐵人賽
iThome鐵人賽