在日常維運系列文章中,曾經有提到過一個關於棒球賽的大流量維運工作,當時的進度停留在透過資料庫加開來因應,也分享了一些加開過程中觀察到的有趣現象,並提到未來有可能透過快取機制來分擔流量問題。
在鐵人賽完之後,快取機制正式上線,不出意外的話果然出意外了。這篇文章就是要來分享接下來的發展。
從資料庫(RDS)的角度來看,我們分擔流量的狀況可以說是相當優秀。請參考下圖:
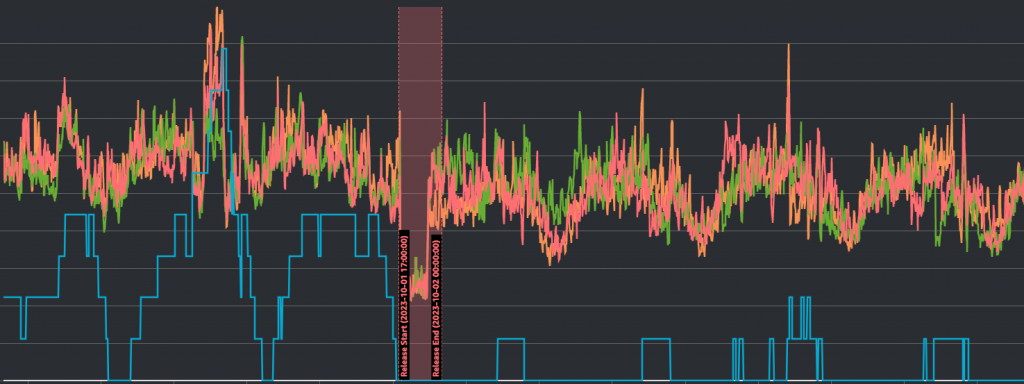
橫軸是時間(大約是一週),縱軸則分別是CPU使用量(%數)和資料庫reader的數量(台數);藍線是資料庫隨時間的數量改變,另外三條色彩繽紛的則是三台基礎reader的CPU使用狀況;中間紅色區域則是我們部署新版本的時間。
可以看到,資料庫的數量在部署前後的數量變化差異非常大,流量高峰時額外需要的台數前後差距可能高達5-6倍之多,但reader的CPU使用狀況卻沒有差上非常多,足以證明我們流量轉換有相當巨大的效果。
此外,可以看到在新版本上線後,資料庫的CPU使用狀況也有一度衝高過,且同時伴隨著資料庫台數比其他時間還要多的狀況。事後觀察當下的數據,發現當天的流量瞬間衝高到接近棒球賽冠軍賽等級的流量,但因為快取還是非常有效地處理了大部分的流量,因此資料庫所需要的數量還是不多,而且也沒因為CPU衝高而出現無法使用的狀況。
換句話來說,我們成功透過快取機制大幅改善了系統的效能和可用性。這部分也非常感謝後端工程師的協助。
改善歸改善,說服客戶就又會是另一個工作了。在與產品經理以及客戶協商之後,我們決定透過接下來3次的棒球賽事來測試目前系統的效能。在第一場棒球賽事中,我們會嘗試先加上比較保守數量(比較多)的伺服器來觀察系統效能,順利的話在第二場嘗試只加上一點點伺服器來觀察系統效能,如果也順利的話就在第三場時透過完全不要事先加開了確認系統可以負荷。
說實話,這除了是為了說服客戶之外,筆者自己也不敢非常肯定完全不需要加開伺服器,因此透過幾次實驗來確認也是相對穩健的做法。畢竟快取機制的最終目標本來再也不需要預先加開資料庫,如果最後能確認達到這個目標就再好不夠了。
然而,就在加開計畫訂出來後的第一天晚上,系統出現了快取伺服器(Amazon ElastiCache for Redis)的CPU使用量過高的警報,而且該警報維持了幾乎是整個晚上,並在接下來的平日晚上(沒有棒球賽)都接連發生。
雖然在整個警報的過程中我們服務都可以正常存取,但看起來在流量導向之後,也許快取伺服器會成為繼資料庫伺服器之後的下一個流量過高的受害者也說不定。如下圖所示:
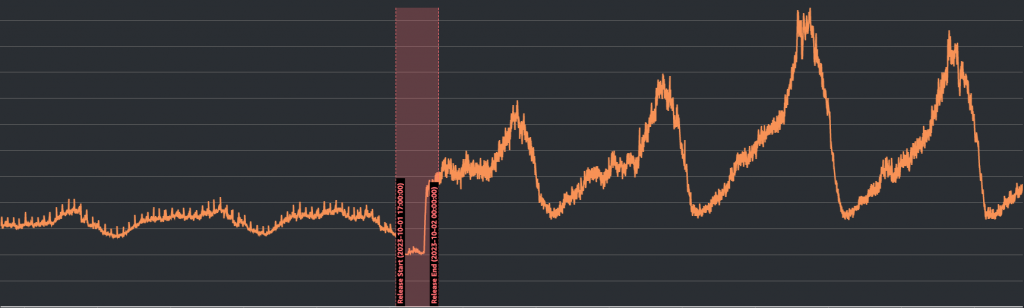
上圖顯示的是快取伺服器隨時間的CPU使用量變化。在新版本上線後,CPU使用量不只有顯著提升,還會在流量高峰時衝到危險數值。
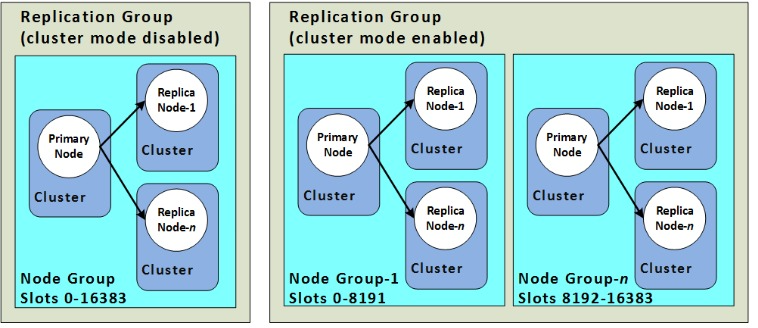
先簡單介紹一下我們使用的快取服務為Amazon ElastiCache的Redis服務,其中最小單位為Node或Shard。前者是一般狀況,後者則是啟用Cluster Mode之後的最小單位。數個Node或Shard會組成一個Cluster(Replication Group),通常我們所連接的對象都會是以Cluster為主。詳情可以參考下圖以及AWS針對Redis Replication的官方文件。
p.s. 這裡的Cluster有兩種含義,一個是以數個Node或Shard會組成一個Cluster(Replication Group),另一種則是決定是否有sharding功能的Cluster Mode。因為非常容易混淆,接下來會以Replication Group和Node Group來指涉數個Node或Shard組成的單位,而Cluster Mode就是在針對是否有sharding。
在調查的初期,因為以快取伺服器來承擔大部分流量本來就是既有的目標,因此一開始思考的方向是以加大快取伺服器的機器等級做為出發點。然而在整個調查的過程中,後端工程師卻發現預期要承受流量的對象似乎與他們預想的不同。我們似乎接錯Replication Group了,原本是想要接到有啟用Cluster Mode的那組,但接到的卻是另一組沒有啟用的。
實際上,後端程式所對接的endpoint是Route53上的domain,並透過CNAME來轉址到ElastiCache的endpoint,但CNAME轉址的對象卻是舊的Replication Group。而這個接錯的狀況似乎已經維持非常久,久到找不到當初設定的人或是這樣設定的理由,現在會發現也只是因為警報響了的關係。
雖說單純修改Route53上的設定相對單純,因此幾天後我們就解決這個問題了,但是當初會啟用Cluster Mode的其中一個理由,就是為了在sharding之後可以增加快取伺服器的可用性,因此修正這個設定一定程度上應該可以改善警報頻繁的狀況。請參考下圖:
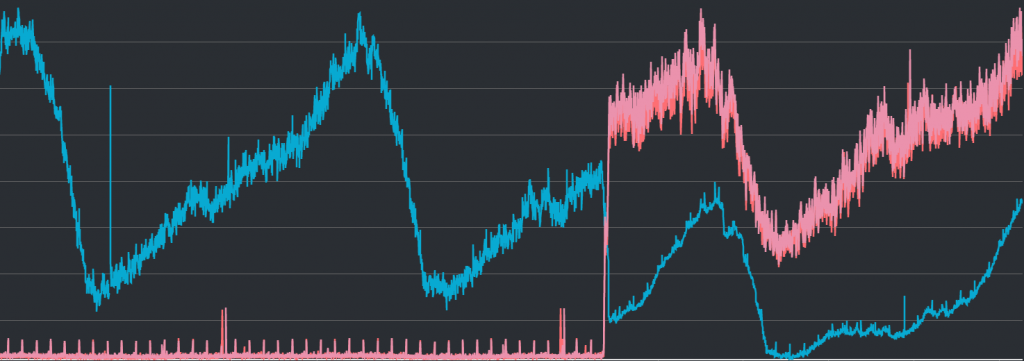
上圖顯示的是快取伺服器隨時間而改變的CPU使用狀況。藍線是沒有啟用Cluster Mode的Replication Group,而紅線則有啟用(因為sharding設定為2個,因此可以看到2條)的2個Node Group。
除了接錯對象之外,我們後端工程師的Team Lead非常厲害地發現了監控目標上的問題。這應該是來自於警報的觸發與我們服務的可用性之間似乎沒有什麼直接關聯,因此讓他開始懷疑我們是否其實監控錯了東西。
上面有提到,我們監控的目標是快取伺服器的CPU使用量,具體而言我們所監控的東西名稱是EngineCPUUtilizaiton,而跟據AWS的官方文件以及部落格文章所建議,因為我們所使用的Node類型皆使用2個vCPU,因此應該要監控CPUUtilization才對。如下方截圖:


而翻開過去的數據,似乎也可以證實這件事情。比如下圖:
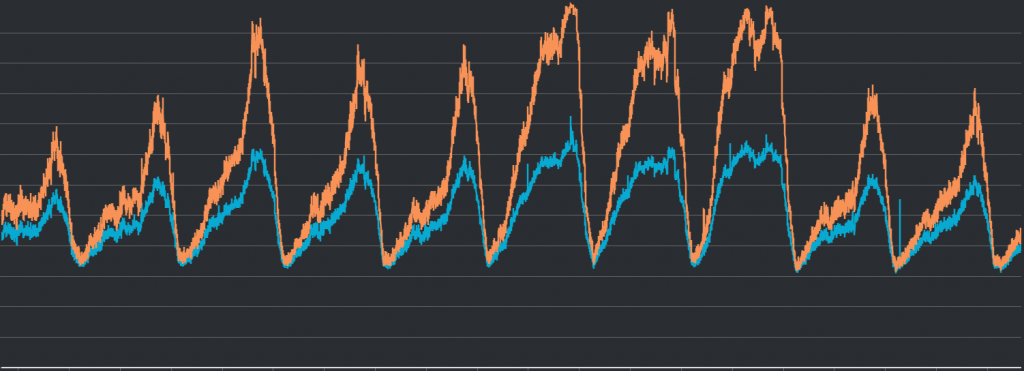
該圖中顯示的分別是EngineCPUUtilizaiton(黃線)和CPUUtilization(藍線)隨時間改變的狀啎。可以看到在黃線衝高的時候,藍線其實根本就還維持在正常水位。請再參考下圖:
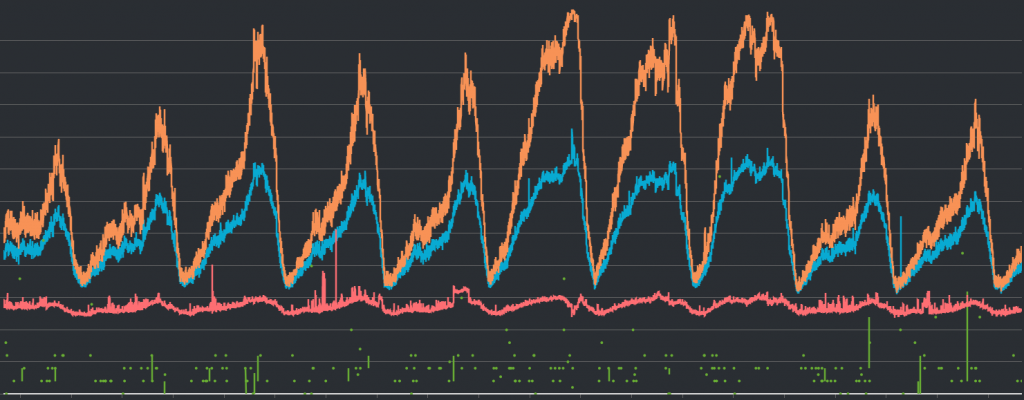
該圖相較於前一張圖加上了紅線與綠線,分別代表GetTypeCmdsLatency與ClusterBasedCmdsLatency(AWS文件)。因為服務本身延遲根本沒有影響的關係,我們也可以藉此確認目前的CPU水線其實是處在相對安全的範圍內。
至於應該怎麼設定比較好,我們仍然在與AWS諮詢中。實際上,筆者對於為什麼CPUUtilization對低於EngineCPUUtilizaiton仍然非常困惑,因為官方部落格文章的說法提到建議監控前者的理由是「the CPUUtilization can reach 100% before the EngineCPUUtilization」,但這應該代表CPU要比EngineCPU更容易衝高才對不是嗎?希望這能夠在接下來的諮詢中找到解答。
在AWS關於ElastiCache for Redis的自動擴展文件中有提到,該服務似乎是有自動擴展功能,但至少要Redis engine 6.0以上才行。如下圖:
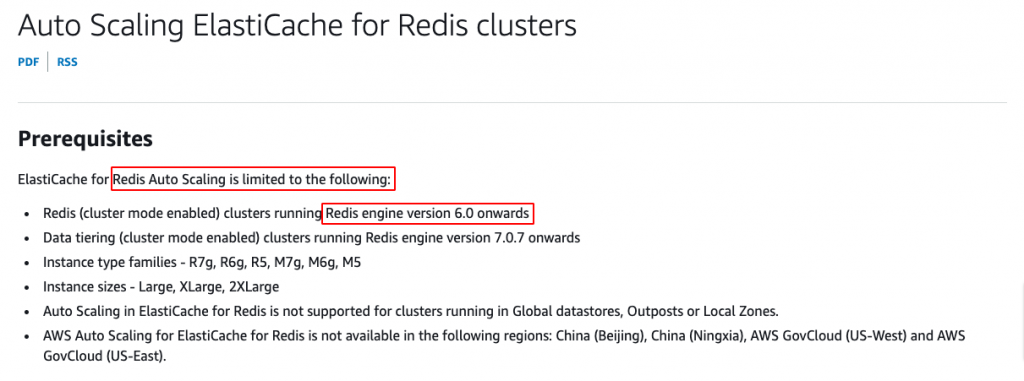
實際上,我們目前的Redis engine仍在使用4開頭的版本。因此,後端Team Lead也有提到,在未來遇到效能瓶頸的時候,除了非常直覺地提高機器等級或增加sharding之外,也許透過升級engine版本並啟用自動擴展的功能,也會是一個值得考慮的方向。
這整個過程中雖然是發生在鐵人賽完賽之後,但因為過程實在是太過精彩有趣,筆者覺得不寫下來實在對不起讀者,因此就額外放在這裡做一個番外篇贈送給大家吧。
事實上,筆者自己在過去對於ElastiCache並不怎麼關心,唯一一次也只是因為收到AWS要求升級engine版本的關係,最主要的原因應該還是在於我們原本就不怎麼使用ElastiCache吧。此外做為一個全托管式的服務,原本筆者還以為自動擴展之類的東西都會跟它沒有關係。
但從這次事件裡意外得知非常多設定上的細節,之前就一直搞混的兩種cluster也趁這個機會順便釐清了一波。SRE 果然還是一個非常有趣的工作吧,無論何時都會有意想不到的事情,從意想不到的角度出現在我們面前。


 iThome鐵人賽
iThome鐵人賽