
昨天介紹了基礎的分散式系統元件,今天會進一步講如何加入機係學習的部分,關於機器學習,這一個由 AWS 針對 Fraud Detection 的 Example 很好的介紹了一個常見的流程,今天我們先從這個流程開始說起
這個流程我們已 AWS Fraud Detection 的範例為例,這個題目是要判斷某個汽車保險的索賠是否為欺詐行為,和我們要做的題目非常類似,都是要針對欺詐做一個 Binary Classification Model:
基本上這一系列的 Notebook 可以把最後產出先簡化成一個 Serving Endpoint,換句話說一個 HTTP API,輸入模型特的特徵值,輸出模型分數的結果,這結果在這邊是一個 0 ~ 1 的浮點數來做二元分類的輸出分佈代表可能是欺詐的機率
在善用了 OLAP 資料庫並搭配上面建模的步驟後,最終產生了一個模型的 Endpoint 來預設某個用戶再提晚當下是否為本人操作,現在的問題是要怎麼把這 Endpoint 放入整個架構之中,下圖是一個簡單的架構圖
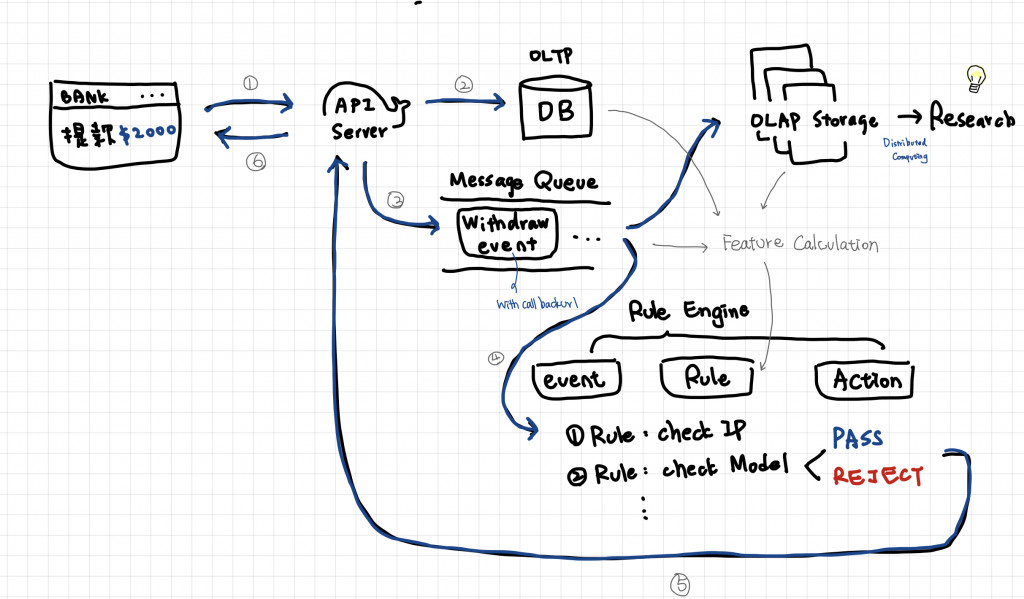
我們來介紹裡面兩個元件
首先我們需要有一個計算元件,針對資料庫的資料來計算我們會用到的特徵,一般我們會把這個元件叫做 Feature Calculation Pipeline,其中我們會更細分為 Computational Component 和 Storage Component
先講 Storage Component,直觀的來說,最後計算出來的特徵值需要有一個地方存放,這就是 Storage Component 的目的,存放計算結果,但當然有些特徵值需要透過緩存的方式來做 Counting,也會需要 Storage Component 的協助
至於 Computational Component 就是計算的邏輯,如果直接消費 OLTP DB,很容易遇到我們之前說的 Locking 問題,如果直接從 OLAP 拿,則會遇到延遲的問題,通常 OLAP 的 Query 都會有比較高的 Latency,所以一個常見的 Pattern 是透過 Message Queue 來分流資料並做到實時特徵計算
以上兩個部分我們會在 Serving 的部分再更近一步說明
有了特徵跟模型後,我們還需要一個 Service 叫做 Rule Engine,我們就以開源軟體 Drools的架構來介紹的架構來介紹這一個 Service,這套系統將整個判斷過程抽象化成一個 Event - Rule - Action 架構,我們直接用一個例子說明
這裡有幾點要注意
到這我們大概勾勒出了一個模型會怎樣放入系統,先在這裡提出一個問題,你認為在我們 Account Takeove Detection Model 中,有較好的 True Positive 表現比較重要還是有較好的 False Negative 表現比較重要呢?
