首先,我們必須明確理解 OpenAI API 和 ChatGPT 之間的根本差異。OpenAI API 是一個基礎工具集,可讓你自行建立對話機器人或AI助理。相對而言,ChatGPT 是一個功能完整的聊天機器人,擁有記憶功能,能呼叫外部插件並根據需求生成統計圖表。
接下來的幾篇文章,我們將透過 OpenAI API 的探討,逐步揭開實做聊天機器人的所有重要概念,在我們正式開始之前,請確保你已完成以下基本環境和設定。
Google Colab 帳號註冊
OpenAI API Key 申請
在上述網站註冊和申請後,您可以在這裏開啟我們本篇的 Jupyter Notebook :
https://colab.research.google.com/drive/18vOjiWzr2NFacDezkRiPOFoEr8zixbYO?usp=sharing
開啟連接後,先在找到下方截圖的地方輸入你的 api key,請記得也要拿掉大括弧。
輸入完 api key 後,我們的第一個訊息先來跟 AI 助理打個招呼
#這裏是使用者的訊息
user_message = f"""你好,很高興認識你!"""
messages = [
{
'role':'user',
'content': f"{user_message}"
},
]
# 呼叫 ChatCompletion
response = get_completion_from_messages(messages, verbose=True)
print(response)
Chat completion 的回應:
你好!我是一個AI助手,很高興認識你!有什麼我可以幫助你的嗎?
在上面的程式碼中,有幾個重要的元素值得我們特別注意。首先,user_message 是用來儲存使用者發送的訊息的變數。其次,messages 是一個用來儲存所有互動訊息的資料結構。我們會在本文稍後進一步詳細介紹這個資料結構的整體設計和運作原理。
當使用者的訊息被存入 messages 這個訊息陣列後,我們就能利用 get_completion_from_messages 函式來呼叫 OpenAI的 ChatCompletion API,進而取得該API回傳給使用者的訊息。
值得一提的是,get_completion_from_messages 函式實際上是我們對 OpenAI ChatCompletion API 進行的一層簡單封裝。這樣做的目的主要是為了便捷地獲得 ChatCompletion 的回覆訊息,無需進行過多的設定或操作。如此一來,我們能更專注於實現對話流程和其他功能,下方則是我們封裝的 get_completion_from_messages 的內容:
# 這個是所有訊息可以共用的 ChatCompletion 的呼叫函式
def get_completion_from_messages(messages,
model="gpt-3.5-turbo", # 語言模型
temperature=0, # 回應溫度
max_tokens=500, # 最大的 token 數
verbose=False, # 是否顯示除錯除錯訊息
):
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
)
if verbose:
print(response)
return response.choices[0].message["content"]
在這個函式中,有幾個關鍵參數特別值得注意,例如模型選擇(model)、訊息記錄(messages)、以及溫度(teperature)等。下面我們會一一進行詳細說明:
模型可以被簡單地理解為一個用來完成特定任務的"黑盒子"。在文字生成的情境中,這個模型的任務就是根據我們的輸入訊息來產生一個相應的回應訊息。
以實作AI助理為例,我們主要會使用到 ChatCompletion API 的端點。該端點的功能就是利用特定模型來生成對話訊息。該模型的版本由我們在呼叫 API 時指定的 model 參數來決定,如預設版本是 gpt-3.5-turbo。
我們可選擇的 Chat Completion 模型還包括例如 gpt-3.5-turbo-0613、gpt-4、gpt-3.5-turbo-16k 等。其中,gpt-3.5-turbo-0613 是在06/13釋出的 GPT-3.5 Turbo版本,而 gpt-3.5-turbo-16k 則是可讓我們使用 16,000 個 tokens 的變種版本。
至於**gpt-4** 的部分,這個版本的模型在邏輯理解、問答精確度等方面表現更優,但其使用費用相對也更高。例如,gpt-4 預設的 8k token 版本的輸出費用是每 1k token 需要 0.06 美金,而 gpt-3.5-turbo 則是每 1k token 只需 0.002 美金。
最後,除了文字生成模型之外,OpenAI 還提供了如圖像生成、語音辨識、文字嵌入等不同類型的模型。若您對 OpenAI 提供的所有模型類別有興趣,更多資訊可參考這裡:Models - OpenAI API。
當我們第一次使用 Chat Completion API 獲得完整回應時,你會注意到 choices[0].message["content"] 中不僅包含了返回給我們的訊息,API 也會一併回傳一個有關 "token usage" 的訊息 - total_tokens。
{
"id": "chatcmpl-7p1cAzC0h94kpmRgDrdfjw6IupSl7",
"object": "chat.completion", // chat completion 的回應物件
"created": 1692395290, // 建立時間
"model": "gpt-3.5-turbo-0613", // 模型版本
"choices": [ // 回應資料
{
"index": 0,
"message": { //
"role": "assistant",
"content": "\u4f60\u597d\uff01\u6211\u662f\u4e00\u500bAI\u52a9\u624b\uff0c\u5f88\u9ad8\u8208\u8a8d\u8b58\u4f60\uff01\u6709\u4ec0\u9ebc\u6211\u53ef\u4ee5\u5e6b\u52a9\u4f60\u7684\u55ce\uff1f"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 21, // 提示(輸入)的 token 數
"completion_tokens": 42, // 回應(輸出)的 token 數
"total_tokens": 63
}
}
// 下方其實就是 choices[0].message["content"] 的內容
你好!我是一個AI助手,很高興認識你!有什麼我可以幫助你的嗎?
什麼是 token 呢?
在語言模型的訓練過程中,尤其是對於像英文這類能夠以詞素無窮組合出詞彙的語言,我們經常會先將詞彙進行分割成有限單位(也稱為 tokenization)。這些被分割後的單元就稱為「Token」。例如下圖則是使用 OpenAI 的 tokenizer 來做分割的結果: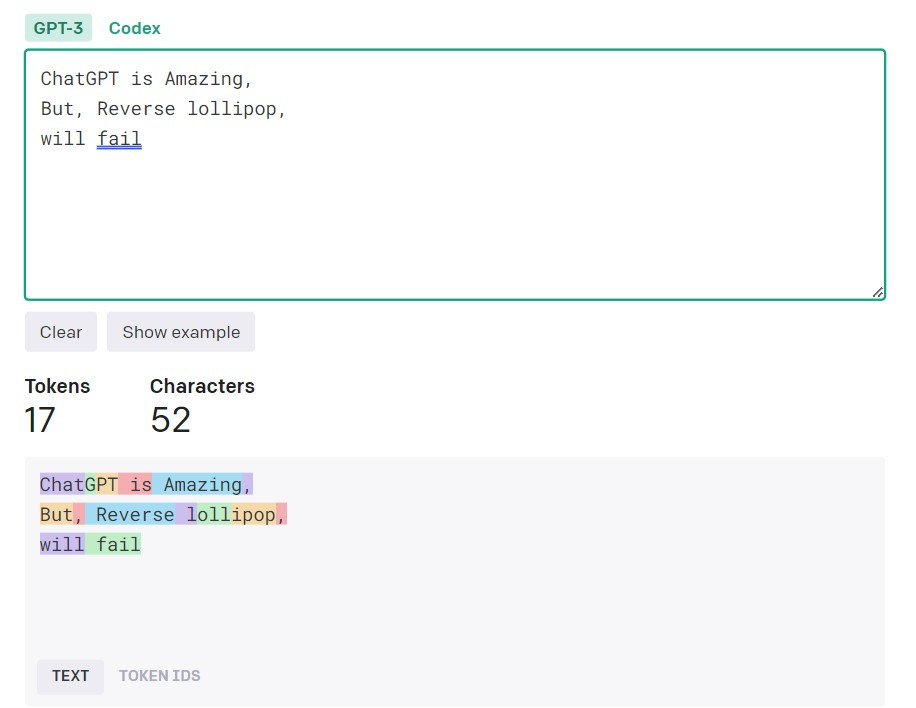
在上圖下方所示的結果中,每一塊不同顏色的區域代表一個 Token。以 ChatGPT 為例,它被分割成 "Chat"、"G" 和 "PT" 這三個 Token。通常情況下,大約每 3到4個字元會構成一個 Token。這些 Token 不只是技術上的分割單位,也是我們在使用 OpenAI ChatCompletion API 時的計費單位。以 GPT-3.5 Turbo 模型為例,其 4K 版本對於每 1K 輸入 Tokens 的費用是 0.0015 美金,而每 1K 輸出 Tokens 的費用則是 0.002 美金。
最後關於 Token 有一個很有趣的狀況,雖然聰明如 ChatGPT 這類的應用,你卻無法要求它正確的將 lollipop 到過來寫,如下: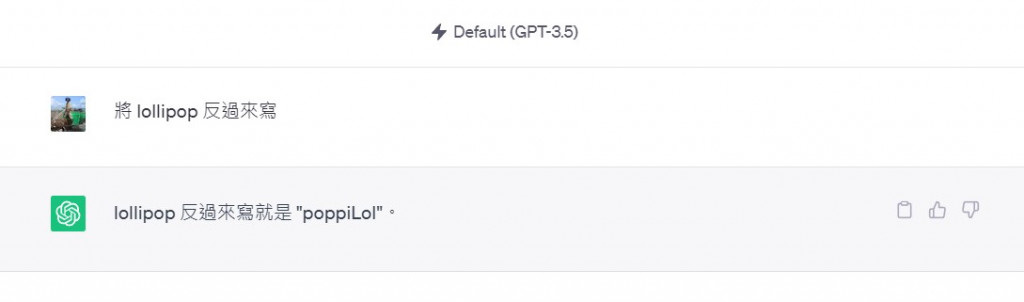
這個現象的根本原因就是本節提到的 token 的問題。如果您希望它能正確地反寫,您可以嘗試以下提示指令:
將 l-o-l-l-i-p-o-p 反過來寫
最後一個與 Token 有關的參數是 "max_tokens" ,這在我們使用 chat completion 功能時是一個重要的考慮因素。該參數的目的是為了限制 chat completion 在處理時的最大 Token 數量。例如,如果我們將 "max_tokens" 設定為 500,那麼在呼叫 chat completion 時,輸入和輸出的總 Token 數不能超過 500 個。若超過此限制,系統將會回傳一個錯誤訊息。
最後,我們來探討一個在 chat completion 中相當重要的參數—"temperature"。這個參數主要用於調整生成文本的隨機性和創造性。
當設定較高的 "temperature" 值(如 1.0)時,生成的文本將呈現更高的隨機性,結果將更加多元和不可預測。這樣的設定可能會產生一些不太連貫或偏離常規的回答,但也增加了生成出具創意和驚奇結果的機會。
相對地,較低的 "temperature" 值(如 0.2)會降低隨機性,使生成的文本變得更穩定和可預測。這通常會導致更為合乎邏輯和連貫的回答,儘管可能會稍微欠缺於變化和創造力。
在開發過程中,這個參數是一個值得深思熟慮並細心調整的因素。因此,了解如何適當地設置 "temperature" 參數,對於最終生成的文本品質有著不可或缺的影響。
透過這篇文章,我們探討了很多 OpenAI Chat Complete API 的基本觀念,如模型(model)選擇,以及什麼是 token 和其計費方式等,希望這篇文章能為您提供一個清晰的概觀,並幫助您更容易地踏入使用 OpenAI API 的世界。未來的文章中,我們將會進一步探討更多進階的應用和使用案例,期待在下一篇文章再次與您相見。


 iThome鐵人賽
iThome鐵人賽