之前提到的日常維運工作,主要源自於某個重大的 P0 事件。雖然我們一般會有大型維運工作都是因為某些不能忽視的 P0 事件,但也不全然是如此,比如接下來要分享的維護模式工具。
大部分的系統在版本更替的過程中,跟據佈署的策略或實際的更新項目而言,或多或少都有機會需要進入維護模式。在敝公司中,主要由SRE負責協助服務進入維護模式。由於系統龐大,如果以有效率且好管理的方式來在維護模式與一般模式中切換,就會是這裡的重點。
維護模式主要分三個階段。首先,進入維護模式後,所有人進入網站都會看到維護模式的頁面,而嘗試直接存取 API endpoint 的請求也都會收到 HTTP status code 503 的回應;第二階段,在新功能的部署已經完成後,要透過白名單的機制來開放 QA 或其它測試人員進來測試,但一般使用者進來的時候仍然要看到維護模式的頁面;第三階段,等到測試與一切其它工作結束後,要離開維護模式,讓服務重新上線。此時所有人都應該要可以開始正常存取網站。
SRE 負責開發維護模式的工具,而跟據上面的需求,該工具應該要有下面四個主要功能
跟據上面的描述,其實第4個功能不太會用到,但為了避免測試時發現要重新部署之類的狀況,因此仍然在一開始就將該功能列為需要開發的目標。
事實上,在筆者剛進入公司的時候,已經有一套正在運行中的舊工具,其架構如下圖:
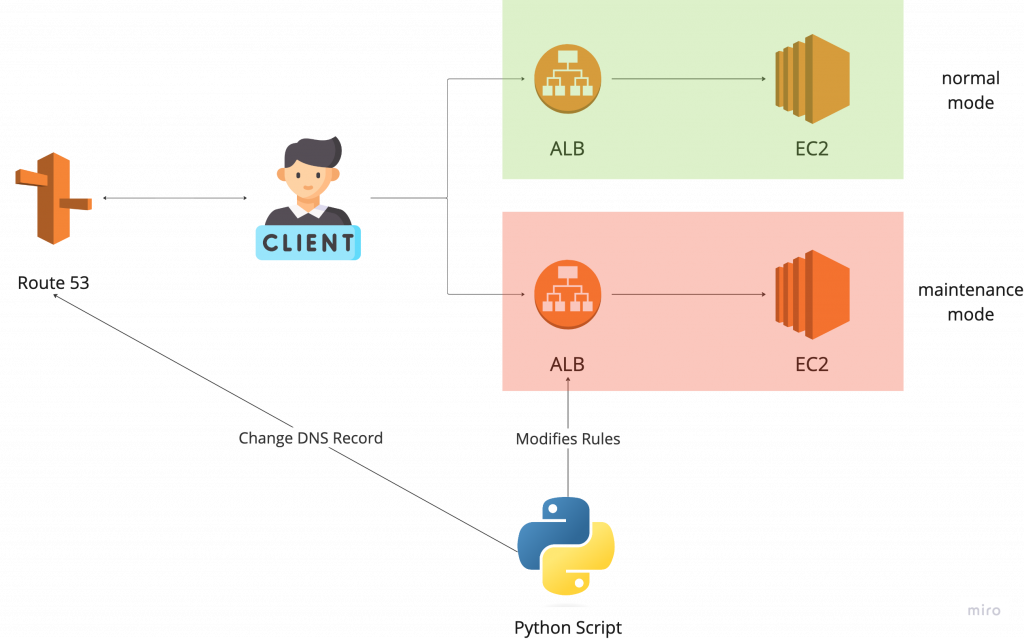
如上圖所示, Client 在一般情況下要存取服務的時候,會透過 Route 53 的 DNS routing 來獲得並存取 ALB 的 endpoint ,再進入後方的 EC2 來存取服務本身(綠色的部分)。我們建立了另一支 ALB 來做為維護模式的入口點,並透過切換 Route 53 上的 DNS routing 規則,將 Client 的請求導向維護模式的 ALB ,以此來達到在一般模式與維護模式中切換的效果(前述功能中的第1點和第2點)。
此外,我們透過修改 ALB 的 rule 的方式,來設定可以存取的的 IP 或應該要阻檔的 IP ,以此來達到開關白名單的效果(前述功能中的第3點和第4點)。這兩件事情都透過一支Python script來完成。
這個架構設計本身是可以運作的,不過這會有至少以下兩個問題:
針對第一點,我們都知道 DNS 因為 TTL 的關係,所以切換的當下並不會馬上生效,因此我們會必須要等待一段時間才能確認進入維護模式。如果 TTL 的時間是確定的,這其實並不一定是什麼大問題,就只要約好共同等待 TTL 設定的時間即可。
然而 DNS Cache 的問題就比較難辦了。這可能會導致我們自己在測試時已經確認進入維護模式,但這個世界上的某一群人其實還可以繼續存取服務的狀況。如果在使用者仍然可以存取的情況下進行部署,有可能會導致許多預期之外的結果。比如我們部署前要進行的資料庫備份作業,如果因為使用者的存取導致資料庫沒有備份到某個使用者的操作,而部署又遇到問題而需要那份備份映像檔的話,那就可能會發生一連串的問題。
針對第二點,我們可以看到,除了維護一般模式下的架構之外,其實我們還會需要再額外維護一套維護模式下的架構。這裡的額外一套架構,除了 ALB 和 EC2 本身外,也包含了 Route 53 的 DNS Record 。而如果每一個單一服務都需要兩套架構的話,且每個環境都要遵守這個設計原則的話,那就會變得非常雜亂無章,維護起來會相當辛苦。
針對第三點,在筆者開啟這個研究的當下, ALB 的每一個 rule 只能允許 5 個 IP 。換言之,可能會因為白名單數量過多的關係,導致同樣一套規則,必須每 5 個 IP 都設立一個 rule 。而這大幅增加了 Python script 的維護困難度,因為筆者會常常會在 tracing 的時候迷失在 rule 的迷宮裡面。
下一篇文章會分享筆者如何改善這裡這個工具。


 iThome鐵人賽
iThome鐵人賽