今天的主要內容是快速理解文字輸入給模型時所需進行的轉換動作,而這些轉換的概念和技術則是自然語言處理領域中的基本操作。對於深入研究和應用自然語言處理技術來說,這些基礎技術是至關重要的,所以在後續的內容中將會補充這些技術的最新應用。
今天的內容主要包括以下4點:
斷詞(Word Segmentation)在中文與英文上的差別詞彙(Token)
標記器(Tokenizer)的方式在我們開始學習自然語言處理之前,應該先了解電腦如何理解人類的文字。
在文字領域中,我們無法像圖片一樣使用能通過三元色(RGB)的像素(pixel)來將一張完整的圖片數值化(Digitization),因此我們勢必要使用其他方法來轉換這些文字,所以接下來我會用2個步驟來帶你瞭解文字是如何被轉換成模型能接受的格式。

在自然語言處理的領域中,首要的任務是通過斷詞(Word Segmentation)的方式來建立一個包含人類常用的詞彙(Token),這個任務在英文上相對較簡單,但對中文而言卻是非常困難的,這是因為中文字並不是通過空白分隔而成,針對這個問題我們先看到以下例子來方便理解:
english = 'I love natural language processing'
english_tokens = english.split(' ') # 通過空格分割
chinese = '我喜歡自然語言處理'
chinese_tokens = chinese.split(' ') # 通過空格分割
print(english_tokens)
print(chinese_tokens) # 無法分割
#---------------------輸出---------------------
['I', 'love', 'natural', 'language', 'processing']
['我喜歡自然語言處理']
我們可以看見在英文中每個詞彙都是通過空白分隔來建立的,因此最基礎也是最簡單的斷詞方式,就是直接使用Python中的split()函數來進行斷詞的動作,因此在英文斷詞的方式上通常會較為容易。
不過對於中文就會沒有效果,所以對於中文的斷詞方式就需要使用到許多統計學的數學模型才能夠進行斷詞的動作,而常見的方法則有:隱藏式馬可夫模型(HMM)、Byte Pair Encoding(BPE)...等算法,這些算法不只能運用在中文的斷詞上,而是可以用於各種語言中,因此在後續的章節中我會向你介紹該算法的特性與目的,這邊我們只要稍微的知道許多斷詞算法都是通過統計學的數學模型所達成的技術。
讓我們先回到程式的例子中,在以上的程式裡儘管它具有簡單且快速的特性,但仍存在一些問題,我們可以看到以下兩個問題:
火山矽肺症(Pneumonoultramicroscopicsilicovolcanoconiosis),該文字其實是由:關於肺部的(pneumono)、超過(ultra)、極微小的(microscopic)、矽(silico)、火山(volcano)、塵埃引致的疾病(coniosis)這6個詞彙組成,這6個詞彙也能很好的表達該症狀的特徵,但在該算法上卻會將火山矽肺症視為一個新的單字而忽略文字間該有的特性。所以這種方式並不嚴謹,但在瞭解後續改良的算法之前,我們仍然需要瞭解這種經典的算法的缺點與特性。
小提示:
在理解中文斷詞方式之前,仍需要掌握許多相關知識。因此在今天的講解中,我將使用英文的資料來進行說明。直到後續的內容,我將展示如何對中文進行斷詞,並再次討論這個問題,同時介紹最新且實用的斷詞技術。
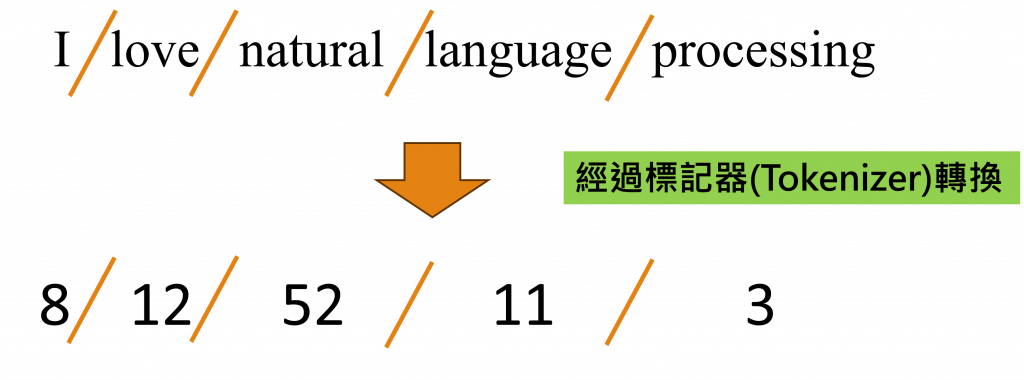
經過了上一個小節,我們獲得該句子的所有詞彙,但對於在現實情況中,我們往往需要使用程式的迭代功能來獲取整個文本資料中的詞彙,但對於電腦而言我們還需要將這些詞匯轉換成數字,因為電腦只能理解數值類型的資料,所以為了進行斷詞和轉換的動作,我們需要建立一個標記器(Tokenizer),而建立標記器的第一步是獲得所有的詞彙,所以我們需要使用程式來進行此步驟:
#假設該資料集中的句子如english_sentence
english_sentence = [
'I love natural language processing',
'Hello Python',
'I like Apple',
'I am a human',
'You are a robot',
]
tokens = []
for sentence in english_sentence:
tokens.extend(sentence.split(' ')) # 將一段句字進行斷詞後加入列表(List)
tokens = set(tokens) # 通過set()過濾重複單字
print(tokens) # 注意此時的資料型態是集合(Set)
#---------------------輸出---------------------
{'like', 'am', 'natural', 'I', 'Apple', 'You', 'robot', 'Python', 'love', 'language', 'a', 'are', 'Hello', 'human', 'processing'}
當上述程式執行完成後,我們將能夠取得該資料集的詞彙,不過我們還會遇到一些問題,在所有的文字中,我們很難僅依靠手上的資料收錄到現實中的所有的詞彙。
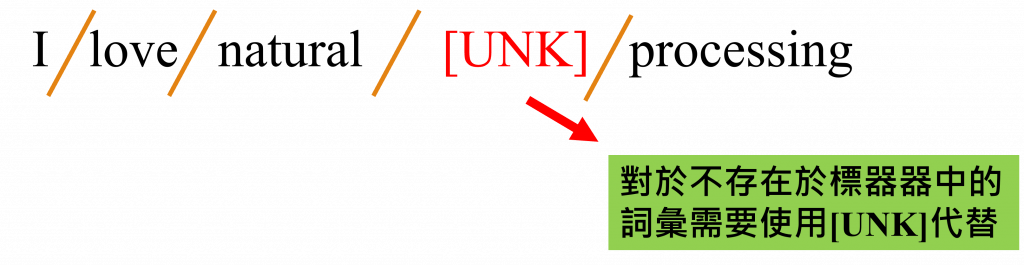
所以當這些未被收錄的詞彙輸入到模型時就會導致模型錯誤。因此我們需要處理這些未知的詞彙,其中最常使用的方式是建立一個特殊標籤[UNK]來表示這些未知的詞彙已保留該文字的部分特徵。
另外還需要有一個特殊標籤,這個特殊標籤是因為在深度學習的模型中,每筆資料輸入的長度是需要固定的所以我們需要對過短的文字進行截長補短的動作,使模型在運算的過程中不會因為輸入大小不同而導致錯誤,對於這種狀況我們則是會創立一個名為[PAD]的特殊標籤。
小提示:
[UNK]和[PAD]都只是識別符號,你可以用你自己喜歡的特殊符號來替換它們,只要你自己能理解就可以了。不過這兩個符號通常在許多大型語言模型(Large Language Model, LLM)中都被這樣表示,所以我們通常不會去修改這些標籤。
我們可以通過以下程式將這些特殊符號加入到我們所得到的詞彙中,以便進行後續的標記器建立。
special_token = ['[UNK]','[PAD]'] # 建立特殊的詞彙表
tokens = special_token + list(tokens) # Tokens為Set型態,因此需要轉型成List才能夠相加
print(tokens)
#---------------------輸出---------------------
['[UNK]', '[PAD]', 'Hello', 'love', 'are', 'natural', 'robot', 'am', 'a', 'You', 'processing', 'language', 'I', 'Python', 'like', 'human', 'Apple']
當我們建立完所有的詞彙後還需要建立一個能夠將詞彙和數字互相轉換字典(Dictionary),這樣子我們可以通過字典的特性來進行快速轉換的動作,當然我們還能夠建立一個將數字轉換為詞彙的字典,使我們之後想要觀看轉換後的結果。
token2num = {tokens:num for num, tokens in enumerate(tokens)} #詞彙轉數字
print(token2num)
#---------------------輸出---------------------
{'[UNK]': 0, '[PAD]': 1, 'processing': 2, 'Apple': 3, 'natural': 4, 'are': 5, 'love': 6, 'I': 7, 'robot': 8, 'Hello': 9, 'like': 10, 'You': 11, 'human': 12, 'Python': 13, 'a': 14, 'language': 15, 'am': 16}
num2token = {num:tokens for num, tokens in enumerate(tokens)} #數字轉詞彙
print(num2token)
#---------------------輸出---------------------
{0: '[UNK]', 1: '[PAD]', 2: 'like', 3: 'are', 4: 'natural', 5: 'human', 6: 'am', 7: 'I', 8: 'language', 9: 'love', 10: 'Apple', 11: 'You', 12: 'a', 13: 'Hello', 14: 'Python', 15: 'robot', 16: 'processing'}
完成上述步驟後我們就能夠建立出標記器,使其能夠幫助我們進行斷詞、填充(Padding)、轉換的動作,在這邊我使用了函數的作法使其能夠被重複使用。
def tokenizer(input_text, token2num, max_len = 5):
UNK_IDX = token2num['[UNK]'] # 取得未知詞彙的索引值
PAD_IDX = token2num['[PAD]'] # 取得填充詞彙的索引值
tokens = input_text.split(' ') # 斷詞
output_num = []
for token in tokens:
num = token2num.get(token, UNK_IDX) # 轉換成數字(不存在於字典時轉換成[UNK])
output_num.append(num)
padding_num = max_len - len(output_num) # 計算需填充的數量
return output_num + [PAD_IDX] * padding_num # 補齊最大長度
input_text = 'I like Banana'
output_num = tokenizer(input_text, token2num)
print(f'原始輸入: {input_text}')
print(f'轉換結果: {output_num}')
#---------------------輸出---------------------
原始輸入: I like Banana
轉換結果: [16, 7, 0, 1, 1]
這時你可能會想要觀看轉換後的文字究竟轉換成什麼樣子,因此為了方便查看輸入給模型的文字內容,我們還需要撰寫一個將數字轉換回詞彙的函數。
def num2tokens(input_list):
output_list = [num2token[num] for num in input_list]
return ' '.join(output_list)
restore_text = num2tokens(output_num)
print(f'還原結果: {restore_text}')
#---------------------輸出---------------------
還原結果: I like [UNK] [PAD] [PAD]
到這邊我們已經完成了完整的詞彙轉換程式,使我們能夠將輸入的詞彙被電腦識別。但上述的程式碼比較分散且不易重複使用。因此我將上述的程式碼進行改寫,並轉換成類別(Class)的形式,這樣在未來中我們就能夠重複使用該程式碼了。
class Tokenizer:
def __init__(self, english_sentence, max_len = 5, special_token = None, padding = True):
tokens = []
for sentence in english_sentence:
tokens.extend(sentence.split(' ')) # 將一段句字進行斷詞後加入列表(List)
tokens = set(tokens) # 通過set()過濾重複單字
if special_token is not None:
tokens = special_token + list(tokens)
self.token2num = {tokens:num for num, tokens in enumerate(tokens)}
self.num2token = {num:tokens for num, tokens in enumerate(tokens)}
self.max_len = max_len
self.padding = padding
def __call__(self, input_text):
tokens = input_text.split(' ')
UNK_IDX = self.token2num['[UNK]']
PAD_IDX = self.token2num['[PAD]']
output_num = []
for token in tokens:
num = self.token2num.get(token, UNK_IDX) # 轉換成數字(不存在於字典時轉換成UNK_IDX)
output_num.append(num)
padding_num = self.max_len - len(output_num) # 計算需填充的數量
return output_num + [PAD_IDX] * padding_num # 補齊最大長度
def num2tokens(self, input_list):
output_list = [self.num2token[num] for num in input_list]
return ' '.join(output_list)
# 所有句子
english_sentence = [
'I love natural language processing',
'Hello Python',
'I like Apple',
'I am a human',
'You are a robot',
]
# 建立初始值
tokenizer = Tokenizer(english_sentence, special_token = ['[UNK]','[PAD]'])
#使用建立的Tokeizer
input_text = 'I like Banana'
output_num = tokenizer(input_text)
restore_text = tokenizer.num2tokens(output_num)
#顯示結果
print(f'原始輸入: {input_text}')
print(f'轉換結果: {output_num}')
print(f'還原結果: {restore_text}')
今天原本打算一次性寫完有關電腦如何理解文字的部分,但在過程中發現在建立Tokenizer的動作越寫越多,所以我將這一部分分成了兩個章節。在今天的內容中,我主要教你如何將文字作為模型輸入的方式。而在明天的內容中,我將開始探討電腦如何理解文字。希望通過這種分章的方式能讓你更全面地了解自然語言處理的基本概念。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days

