我們昨日學習了如何進行詞彙的劃分以及建立標記器,今天我們將繼續進階內容,探討模型如何理解文字。今日的主要學習內容將包含以下三點:
詞嵌入(Word Embedding)的理論分析與程式應用可視化(Visualization)方式在自然語言處理的領域中,一種常見的資料前處理(Data Preprocessing)技術就是One-Hot Encoding(獨熱編碼),其主要功能是將詞彙轉換成一個向量空間,透過這種方法,我們能夠創建出一個與詞彙表相同大小的向量。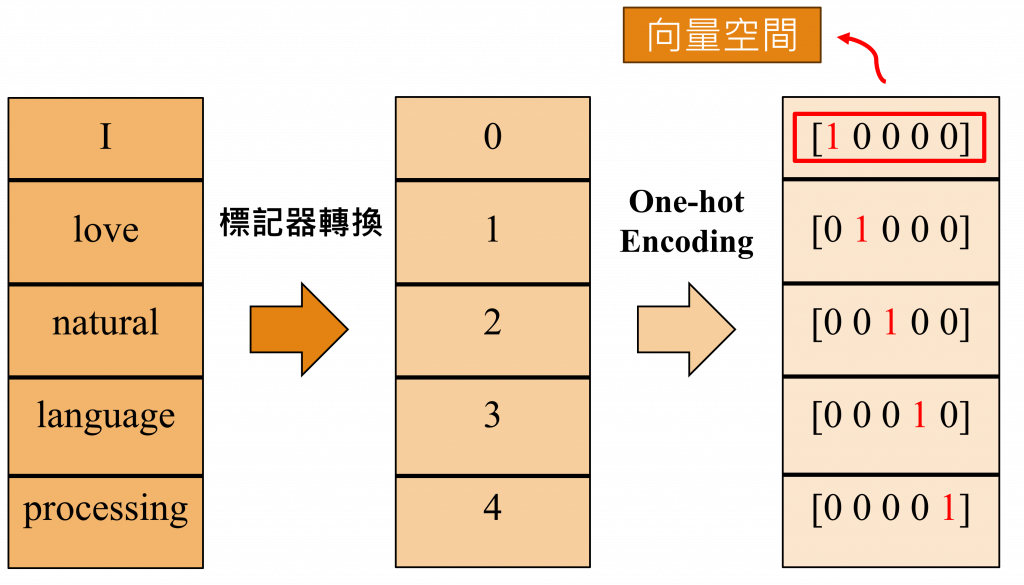
如上圖所示在這個向量中,絕大部分元素都是0,只有單一個元素為1。這個元素值為1的索引,對應到的就是標記器所轉換出的數字,如此一來我們就能將每一個詞彙轉換成向量空間中的一座標點。
不過使用這種方法將會有稀疏性的問題,因為在One-hot Encoding中的大部分元素都是0,導致生成的向量非常稀疏,這意味著如果詞彙量過大,使用該表示方式會產生非常龐大的向量。
如上圖中的例子,即使只有5個詞彙,也會產生一個5*5的向量,而在一個語言模型中通常有30000個以上詞彙,這代表將會有一個30000*30000的向量,這不僅增加了記憶體的負擔,還會降低模型的運算速度。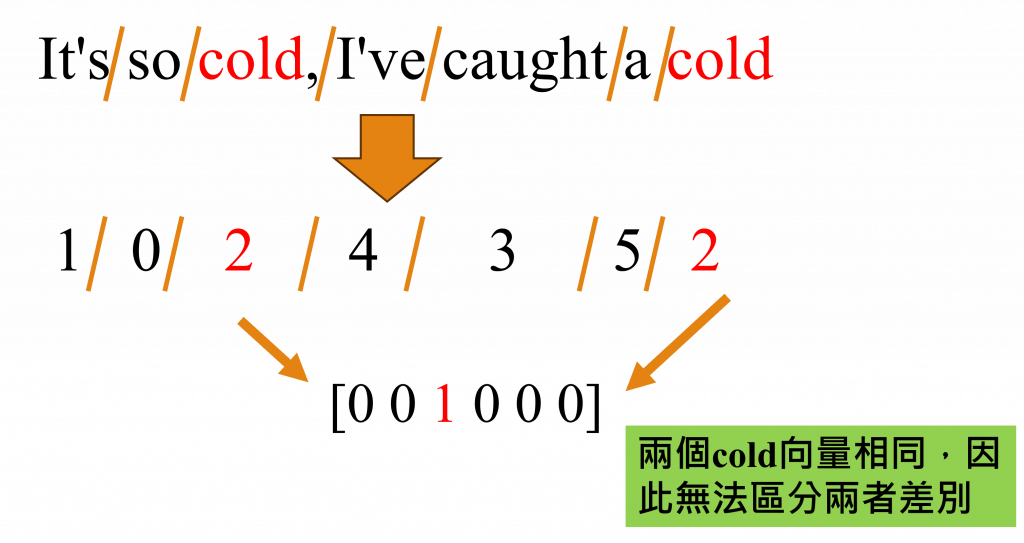
並且One-Hot Encoding的方法存在一些嚴重問題,我們以圖中的「It's so cold, I've caught a cold」這句為例,在這個句子裡,我們可以看出前一個「cold」的意思是代表「寒冷」,而後一個「cold」則代表「感冒」。
但在One-Hot Encoding的轉換中,每個詞彙都會被賦予一個獨一無二的向量,這就導致了文字之間並沒有關聯性與無法表達出一詞多意的概念等問題,於是出現了改良這中方式的技術,該技術的名稱就是詞嵌入(Word Embedding)
詞嵌入是將文本中的詞彙轉變成連續向量的技術,這種技術將詞彙映射到高維度的向量空間中,使具有相似意義的詞彙能在同一個空間聚集。
這點可能用說得過於抽象,所以我將以程式語言的方式,逐步介紹詞嵌入層在進行什麼樣的運作,首先我們需要先導入並安裝必須的函式庫。
首先我們將初步安裝Pytorch與matplotlib,來幫助我們將詞彙映射至詞嵌入層(Embedding Layer)與可視化(Visualization)詞嵌入的動作,我們可以透過pip指令來安裝這兩個函式庫。
pip install torch
pip install matplotlib
當完成安裝後,我們可以透過import和from這兩種方式使用該函式庫的功能,而在以下的程式中我還會使用昨天在【Day 2】電腦該怎麼理解人類的語言 (上) - 文字怎麼輸入到模型中中創建的類別來做為我們的標註器。
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from tokenizer import Tokenizer # 昨日建立的類別
在我的GitHub上方已建立了
tokenizer.py這一檔案,你可以直接下載該檔案或到昨天的內容中取得該程式碼。
在建立完程式環境後,我們還需建立一些詞彙,並從類別中取得token2num與num2token兩個用於詞彙轉換建的字典,以便後續能在可視化詞嵌入中的計算結果。
negative_words = ["disappointed", "sad", "frustrated", "painful", "worried", "angry"]
positive_words = ["happy", "successful", "joyful", "lucky", "love", "hopeful"]
# 建立初始值
all_words = negative_words + positive_words
tokenizer = Tokenizer(all_words, special_token = ['[UNK]','[PAD]'], max_len = 1)
token2num, num2token = tokenizer.token2num, tokenizer.num2token
首先我們需要先取得num2token的字典,並將其轉換成張量(Tensor)。這樣做的原因是GPU和TPU等硬體加速器上進行張量計算效率極高,這對於深度學習中大規模的數值運算十分重要,並且神經網絡通常有著大量的參數和數據需要處理,這種方式還能夠追蹤每一個神經元的梯度變化,以達到優化模型的目的。
# 取得所有轉換後的詞彙
token_nums = torch.tensor([i for i in num2token])
# 創建一個詞嵌入層(Embedding layer)
emb = nn.Embedding(len(token_nums), 2)
# 將Token映射到詞嵌入層中
embedding_matrix = emb(token_nums).detach().numpy()
在這裡我們建立了一個函數,用於視覺化這些向量,而這個方式非常簡單,因為在建立詞嵌入的時候,我們只使用了兩個維度,所以可以直接將這兩個軸視為平面上的x和y軸,作為我們視覺化向量的方式,不過在當前我們的數據資料是數字型態,於是我們需要用到num2token字典,將已經轉換成數字的詞彙替換回來。
def visualization(embedding_matrix, num2token):
# 提取降維後的坐標
x_coords = embedding_matrix[:, 0]
y_coords = embedding_matrix[:, 1]
# 繪製詞嵌入向量的散點圖
plt.figure(figsize=(10, 8))
plt.scatter(x_coords, y_coords)
# 標註散點
for i in range(len(embedding_matrix)):
plt.annotate(num2token[i], (x_coords[i], y_coords[i]))
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Visualization of Embedding Vectors')
plt.show()
visualization(embedding_matrix, num2token)
從下圖中我們可以發現,在詞嵌入被建立的過程中,每一個文字初始都是隨機定位的,然而在深度學習模型的幫助下,我們可以通過調整這些文字在空間上的位置來找到最合適的向量,使電腦能理解與這些詞彙之間的相關性與涵義。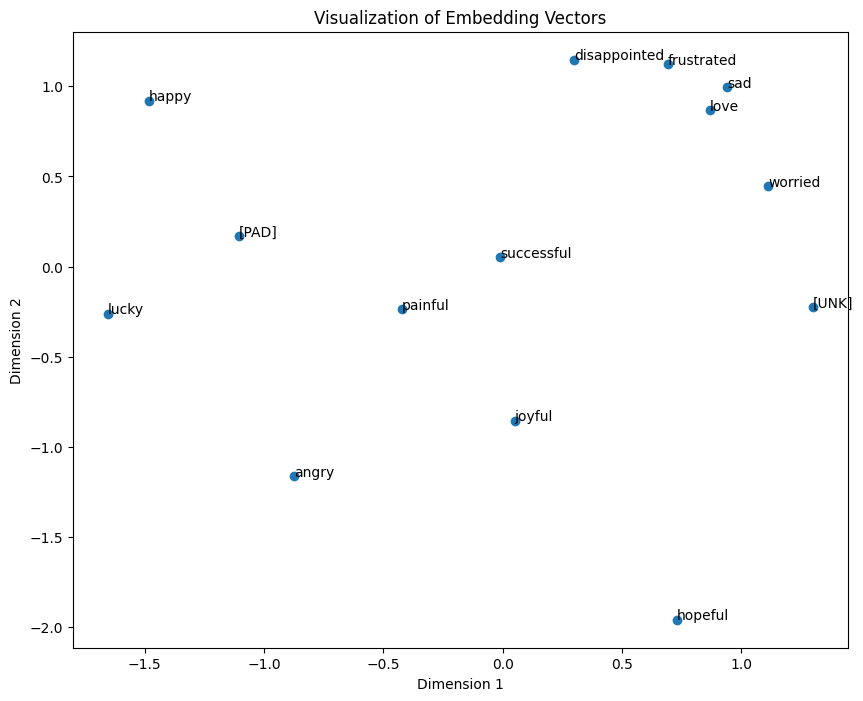
若詞嵌入的向量設定超過2時我們還需要使用到許多降維(Dimension Reduction)的技術, 例如:主成分分析(Principal Component Analysis, PCA),t-隨機鄰近嵌入法(t-distributed Stochastic Neighbor Embedding, t-SNE)等,才能夠將這些維度顯示出來。
因為並未在前文中提及模型訓練的概念,不過為了方便理解被訓練過後的詞嵌入向量究竟會長什麼樣子,所以我已經利用訓練模型的方式來調整這些詞嵌入的權重,該權重已公開於我的GitHub中,我們需要做的就是下載這些權重並放至指定的檔案路徑以方便我們進行讀取的動作。
emb = nn.Embedding(len(token_nums), 2)
emb.weight = nn.Parameter(torch.load('embedding_weights.pth')) # 讀取權重
embedding_vector = emb(token_nums).detach().numpy() # 建立向量
visualization(embedding_vector, num2token) # 視覺化
現在我們可以明確地看到正向詞彙如"happy"、"successful"、"joyful"和負向詞彙如"disappointed"、"sad"、"frustrated"被清楚地區分出來,這就是一個很好的詞嵌入層,通過這一層我們可以進行後續的運算,例如將這些向量透過某種時間序列模型(Time Series Model)來計算文字之間的語句上下文關係,而這種方法也能在後續運算中考量到向量中相近的詞彙特性,使模型能更全面的考量詞與詞之間的關係。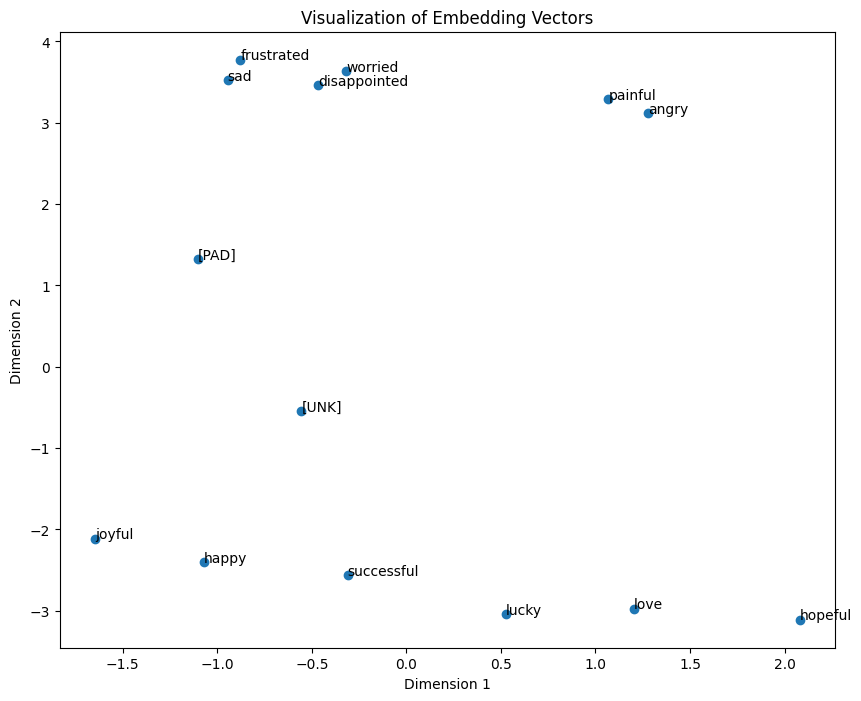
以上就是電腦理解文字的方式,在後續的內容中我將透過不同的模型來訓練詞嵌入層,以加深我們對詞嵌入層的理解。
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from tokenizer import Tokenizer # 昨日建立的函式庫
negative_words = ["disappointed", "sad", "frustrated", "painful", "worried", "angry"]
positive_words = ["happy", "successful", "joyful", "lucky", "love", "hopeful"]
# 建立初始值
all_words = negative_words + positive_words
tokenizer = Tokenizer(all_words, special_token = ['[UNK]','[PAD]'], max_len = 1)
token2num, num2token = tokenizer.token2num, tokenizer.num2token
def visualization(embedding_matrix, num2token):
# 提取降維後的坐標
x_coords = embedding_matrix[:, 0]
y_coords = embedding_matrix[:, 1]
# 繪製詞嵌入向量的散點圖
plt.figure(figsize=(10, 8))
plt.scatter(x_coords, y_coords)
# 標註散點
for i in range(len(embedding_matrix)):
plt.annotate(num2token[i], (x_coords[i], y_coords[i]))
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Visualization of Embedding Vectors')
plt.show()
# 取得所有轉換後的詞彙
token_nums = [i for i in num2token]
# 轉換成Tensor
token_nums = torch.tensor(token_nums)
# 創建一個詞嵌入層(Embedding layer)
emb = nn.Embedding(len(token_nums), 2)
# 將Token映射到詞嵌入層中
embedding_matrix = emb(token_nums).detach().numpy()
# 顯示該向量
visualization(embedding_matrix, num2token)
emb = nn.Embedding(len(token_nums), 2)
emb.weight = nn.Parameter(torch.load('embedding_weights.pth'))
embedding_vector = emb(token_nums).detach().numpy()
visualization(embedding_vector, num2token)
看到這裡我相信你對於電腦如何理解文字已經有了一定程度的了解,但你可能仍然對某些內容不太熟悉,因此我打算先讓你放鬆一夏,所以我在明天只教你如何安裝Pytorch的GPU版本以及一個在自然語言處理中非常重要的函式庫TorchText,你可以在這段時間中好好的統整這兩天的知識,以便更好理解後續章節的內容。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days


 iThome鐵人賽
iThome鐵人賽