Stable Diffusion是由Stability AI所訓練開發並且開源提供免費使用的圖像模型。可透過文字轉換為圖像(文生圖,txt2img,各式各樣的模型),也可以利用現成圖像搭配輔助文字轉換成其他圖像(圖生圖,img2img)。
Stable Diffusion是一種擴散模型(diffusion model)的變體,叫做「潛在擴散模型」(latent diffusion model; LDM)對偏學術理論這部分想深入研究的可再去Google找相關論文來看。或是參考下面影片講解關於Stable Diffusion 背後運作生成的原理。

對於AI初學者的我來說,去閱讀這些模型背後的專業術語與原理實在很痛苦,每個字我雖然都認得,但神經網路真的非常難懂。最後我只能用自己理解的簡化方式去架構一個輪廓,方便後續實際操作生成圖像時,知道各參數的調整是大致對應到圖像生成的哪個步驟階段,以便掌握出圖方向能盡量如自己所預期就好 。
把Stable Diffusion當成一個畫家,執行繪畫的過程實際上是一個計算的過程,他是很多神經網路和解碼器的並用。它會把每張圖像反覆進行”加噪聲”和”去噪聲”的過程(每一步加噪、去噪都讓圖片只比上一步模糊/清晰一點點,讓過程中對原圖的畫法/樣貌都能以數值的方式呈現,讓機器能夠去加以學習和辨認,並且同時搭配上圖片對應的文字資訊(Caption),同事搭配文本學習的模型,進而學會特定物件主體/風格的特徵和畫法。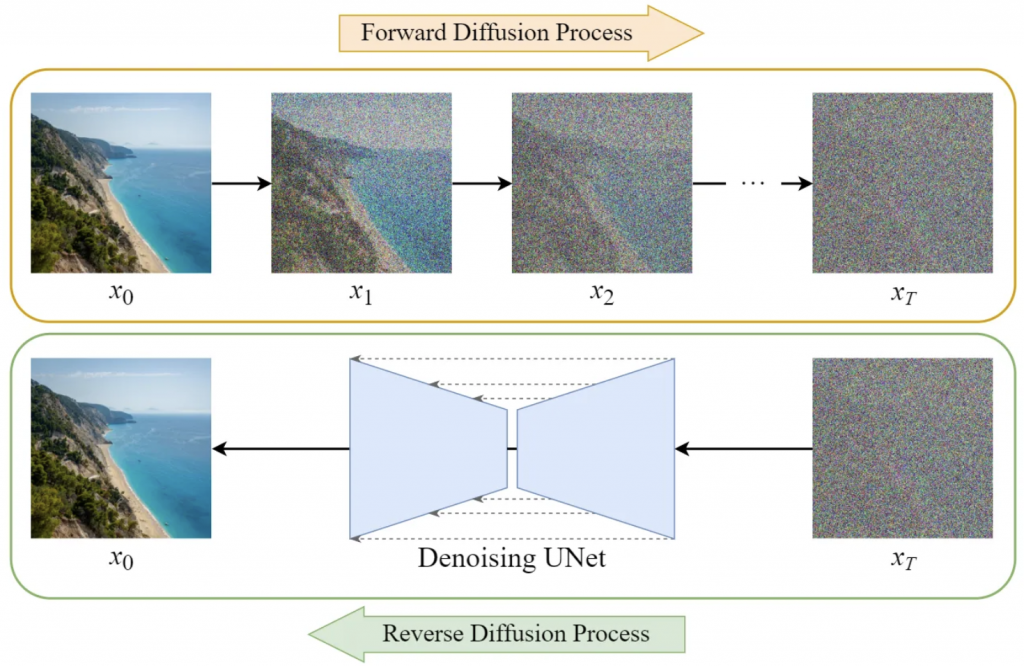
當餵給學習模型大量的圖片,反覆同樣動作學習後,就成為可供我們進行AI繪圖使用的圖像模型。
有了這個圖像模型後,當我們要求它畫一張xx主題的圖時,給它一段文字指令/或是文字指令加上參考圖片,它就會根據指令將隨機產生佈滿噪聲的圖一步步Denoising(去噪)成像。而Stable Diffusioin操作介面中的各式參數(ex. Clip skip、CFG Scale、Denoising strength等等)或外掛(ex. ControlNet等等),分別就在成像的過程中介入到對應的階段進行加不同模型的運算,讓生成的圖像往我們需要的方向產出。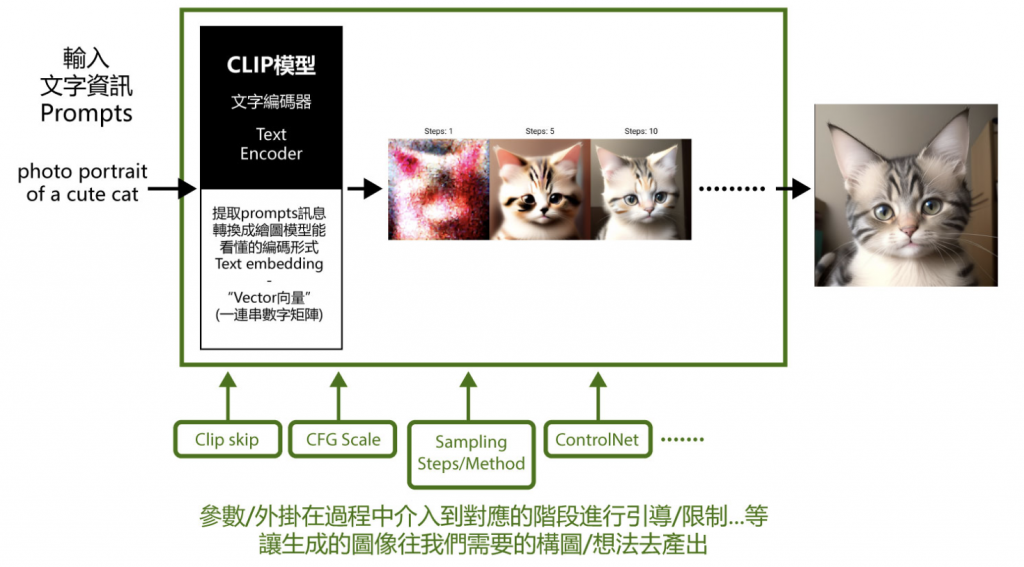
大多數AI繪圖工具都會對一些特定”不適當/不健康(NSFW)”的關鍵字進行管制,無法生成。而使用Stable Diffusion則就沒有這方面的限制,完全自由。


