接續昨天,繼續努力
下面是昨天在使用 requests、 BeautifulSoup 的起手式處理
import requests
from bs4 import BeautifulSoup
url = "爬的網址"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
從這裡繼續走下去
已把原來題目的動態網頁,改了一個靜態頁面
"https://astro.5xruby.tw/testimony/"
題目為:查看裏頭分享文的作者有哪些
是說要如何去分辨動態靜態勒?
首先爬蟲需要搭配的人類行為(麻瓜學習中)
通常會需要查看網頁的原始代碼(HTML)來決定如何編寫爬蟲代碼。
以下是一些步驟:
1.在想要爬取的網頁右鍵 ⇒ 檢視網頁原始碼
2.點選後便會開啟瀏覽器,即可查看網頁的原始代碼( HTML )。
接下來操作:
- 查找需要數據的 HTML 元素:瀏覽源代碼,以查找感興趣數據的 HTML 元素,例如文章內容、鏈接、標題等。
- 確定標識元素的屬性:有時,HTML 元素具有特定的屬性,如 class 或 id,可以更容易地找到它們。
目前我也只會這樣操作,就是在網頁點右鍵去 檢視原始碼
在這圖的左上角有個自動換行,勾選起來方便閱讀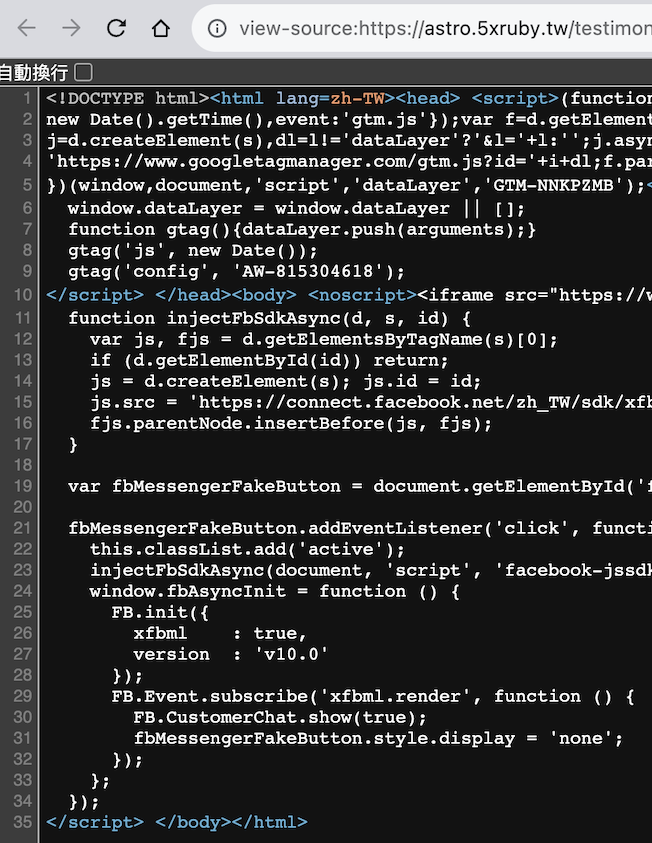
就可以從這裡跟網頁上看到資訊幾乎是一樣的,沒有東西藏起來
但也只是我需要的資訊比較單純,這不是一個妥妥的判別方式
接下來就是要,提取數據並創建數據結構
這邊意思就是說,我們已經把網址內的東西抓一大包出來,
現在就依照我們的需球把資訊整理出來
如何編寫內容呢
先來個簡易範本好了,請 GPT 寫個範本
# 設一個空間來存儲數據
data = {}
# 找到所有文章區域
article_sections = soup.find_all("div", class_="article")
for article_section in article_sections:
author = article_section.find("span", class_="author").text.strip()
# 在這個示例中,我們將文章分享者的名字作為鍵,將相關數據(例如文章內容等)作為值
data[author] = {
"content": article_section.find("p", class_="content").text.strip(),
# 還可以提取其他相關數據
}
就從上面範本來做異動改成符合我們需求的
# 設一個空間來存儲數據
data = {}
# 找到所有作者資訊
author_infos = soup.find_all("h4", class_="is-author")
這裡要提一下 soup.find_all()
所以說soup.find_all() 並不是自己創立的寫法,而是 Beautiful Soup 提供了很多屬性和方法
至於從哪邊去抓到標籤位置,
初步觀察網頁,我要的作者 前面都有"By"做開頭,當我搜尋"By"可以看到下圖,
我撈到我要的標籤了,這就是上面程式碼的由來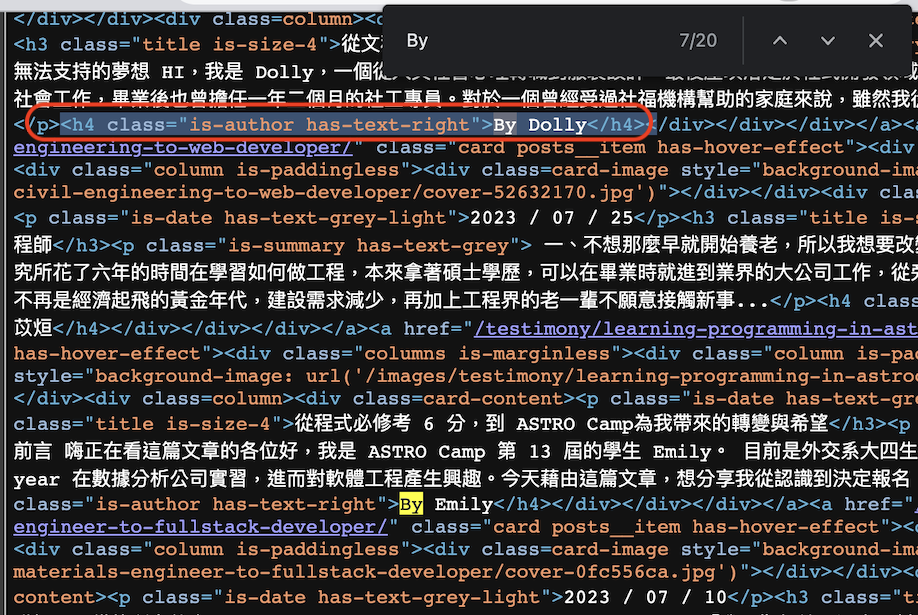
整理一下現階段完成度
import requests
from bs4 import BeautifulSoup
url = "https://astro.5xruby.tw/testimony/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
# 設一個空間來存儲數據
data = {}
# 找到所有作者資訊
author_infos = soup.find_all("h4", class_="is-author")
緊接著我們需要去跑迴圈
網頁上有多個作者資訊需要提取,那麼使用迴圈可以有效地處理它們。
通過 for 循環遍歷 author_infos 列表,將每個"作者"提取出並印出。
Python 中的 for 迴圈採用的是 for ... in ... 的語法,來個範例吧
# 使用 for 迴圈遍歷列表中的元素
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit)
接下來套用我們要的東西實作
for author in (author_infos):
print(author.text)
看看完整組合在一起以及效果如何
import requests
from bs4 import BeautifulSoup
url = "https://astro.5xruby.tw/testimony/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
data = {}
author_infos = soup.find_all("h4", class_="is-author")
for author in (author_infos):
print(author.text)
咦奇怪
沒想要印出的是一堆亂碼
By 許å±æ´
By Dolly
By èè¡ç
By Emily
By é
å±é³´é¸ç¾¤
By å¼µè²æ¨
By é³ç»ç¾©
By 謿åº
By æå å¦%
因為從網頁獲取的文本可能會顯示為亂碼或錯誤的字符。
通過將 response.encoding = "utf-8" 設置為正確的字符編碼,可以確保文本數據正確地解釋和顯示。
最終來檢視一下程式碼,這個 data = {}目前看起來沒用到,我就先把它移除
整理完畢如下!
import requests
from bs4 import BeautifulSoup
url = "https://astro.5xruby.tw/testimony/"
response = requests.get(url)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "html.parser")
data = {}
author_infos = soup.find_all("h4", class_="is-author")
for author in (author_infos):
print(author.text)
終於成功顯示中文啦~~~~~
這次使用到 py 迴圈基礎寫法
response.encoding = "utf-8 的矯正亂碼還原中文
以及初步認識 Beautiful Soup 屬性和方法
看起來好像結束但其實尚未...
因為上面只出現十筆資料,但這網頁有七頁的樣子 :)
明天繼續處理有分頁這部分

