我目前的公司用的數據倉庫主要是 Amazon Redshift 和 AWS S3。作為前端用戶(目前擔任數據分析師),我想總結一下我對 Redshift 以及S3的 運作方式的理解。
**什麼是 AWS S3? **
被稱為 Amazon S3 或 Amazon Simple Storage Service,由 Amazon Web Services(AWS)運營。是一個物件儲存服務即可以在任何時間和任何地點存儲以及檢索任何數據。它的特點如下:
我覺得 S3 最特別的是,所有數據都存儲在“存儲桶”中,因此你可以通過其存儲桶識別特定表的輸入源數據,並將數據文件按照自定義類別進行排序(取決於你的公司運營結構),就像在電腦操作系統中的文件夾裡的組織數據文件一樣。其次,存儲在這些存儲桶中的數據文件無法直接修改。你可以下載、上傳、替換現有文件並刪除文件,但不能直接打開文件並更新其中的數據。
什麼是 AWS Redshift?
它是一個數據倉庫,擁有一組稱為節點(nodes)的計算資源(這些節點組織在一個集群(cluster)中),並在雲中運行 SQL 分析。它與 AWS 數據庫集成,並具有大規模並行處理(MPP)引擎,有助於處理查詢速度,特別是涉及多個表和大型數據集。它的設計不僅用於檢索數據,還可進行分析。 你可以創建集群,設定哪一組人或Team可以優先查詢以及設定速度分配給特定群組(例如:數據倉庫團隊),而不是其他群組(例如 BI 團隊)。
它的特點如下:
AWS S3 如何與 Amazon Redshift 一起使用?
由於 S3 和 Redshift 都是由 AWS 提供的服務/平台,因此有許多方法可以將數據從 S3 移動到 Redshift :
其一:COPY 命令
這是Command命令,你需要手動的去運行.以大規模資料轉移以及需要定時轉移資料的人來說,這非常的費時間。
其二:AWS 的服務,如 AWS Glue 和 AWS Data Pipeline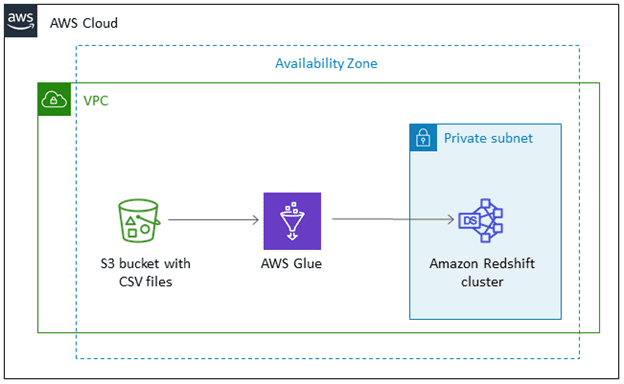
我們現在就是使用 AWS Glue,因為可以在設定的時間間隔內安排加載(創建作業),但需要使用 Python 或 Scala 編寫自己的轉換(Transformation)
如果需要在現有數據集中進行更改,它可以設定更新數據的頻率。像現在我只需登錄 S3,下載所選存儲桶中的數據文件,更新文件,然後重新上傳更新過後的文件回到同一存儲桶,它就會把原始文件替換成我剛上傳的文件。記得要用一個文件名,不然會出現兩個文件都被載入的情況,並導致重複數據發生。
Amazon Redshift 與其他工具一起使用:Python 和 GAS
Python: 可能是因為我轉行第一個學的就是Python,到現在我還是最喜歡用Python 來進行數據清理、編譯和分析.使用 Redshift 時,我會用 Python 設計query,進行分析並將分析結果輸出到 Google Sheets。我嘗試用過 psycopg 和 SQLAlchemy,對於初學者來說,我發現 psycopy 模塊更容易上手。我發現或許是因為API call還是運用第三方工具的關係,query的速度時好時壞,甚至會timed out。
Google AppScript(GAS): 我最近喜歡上了 GAS,讓我試著探索看能否從GAS直接query Redshift。如果你的公司使用 VPN 並且有可接受 IP 的白名單,你需要跟公司申請將 Google IP 加入白名單。由於我的公司對 IP 訪問相當嚴格,我是還沒使用 GAS 直接query Redshift。
總結來說,我喜歡 S3 友好簡單的用戶界面以及 Redshift 的效率和靈活性。我希望未來能使用 AWS 的其他的服務來進行更多的query自動化。
References:
https://aws.amazon.com/
https://en.wikipedia.org/wiki/Amazon_S3
https://www.astera.com/type/blog/amazon-s3-to-redshift/#:~:text=Move%20Data%20from%20Amazon%20S3%20to%20Redshift%20with%20AWS%20Glue&text=AWS%20Glue%20is%20a%20server,commands%20to%20achieve%20maximum%20throughput


 iThome鐵人賽
iThome鐵人賽