前面所說的 Sync Features 又可以再細分為 Streaming Features 和 Realtime Features
Streaming Features 的特點是,處理連續到來的數據,一般就是指 Message Queue 來的 Event,資源使用上需要有近實時的反應
Realtime Features 通常是指在 ms 或是更短時間就"做出反應",但反應這一詞其實涉及 Model Inference 甚至是整個 Decision Engine,所以一般在討論 Features 時,我不會用 Streaming or Realtime 來區分,我比要傾向於用 Realtime 和 Near Realtime 來區分
Realtime 指的是:Feature Pipeline 的邏輯可以一定程度保證只有毫秒集的落差,也是就是計算出來 Feature 值一定是最新的,舉例來說,最後一筆交易的時間這樣的特徵,是不允許有任何一筆落差的,因為交易可能會在一秒內發生多次,有分鐘集的落差就會有很大的影響
Near Realtime 指的是: Feature 的邏輯可以接受分鐘集的落差,舉例來說,最後一次接收到 郵箱認證碼的時間,由於郵箱認證碼每一分鐘才能發送一次,所以她沒有這麼實時的需求
常常我們使用 Apache Flink 或是 Spark Streaming 來處理這類的實時的需求,其中若是對 Latency 要求很嚴格,通常我們會更輕像使用 Apache Flink
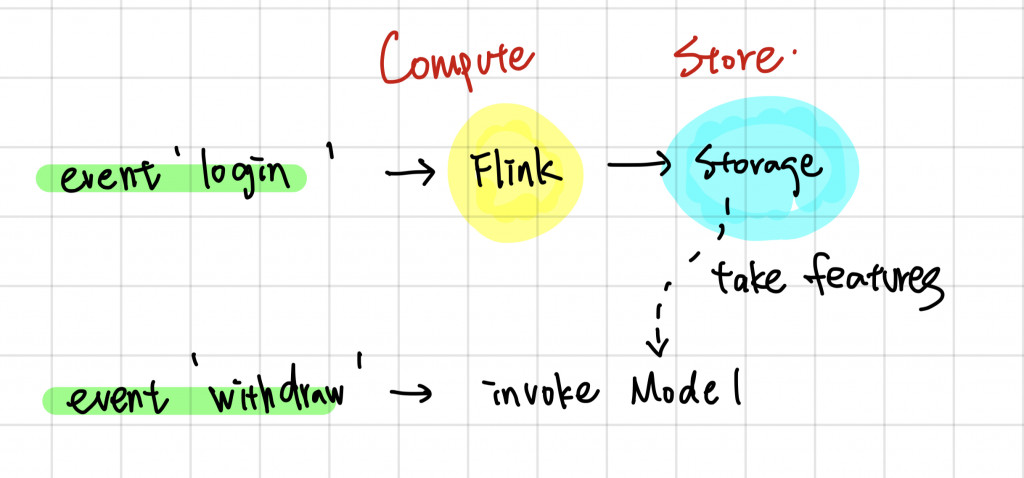
計算與儲存分離是不管在哪一類型 Feature 都需要納入的設計模式,舉上圖為例,有一個特徵是"最後登入時間",當有登的 Event 發生時,就會有一個 Flink 的計算任務 Pipeline 去萃取 Event 的資訊並且放到一個 Storage,在這例子這 Storage 可以是一個 Key Value Paire Storage, 像是 Redis,而這裡個 Key 就是 User ID而 Value 就是最後登入時間
這時當我們的 Account Takeover Model 要被調用時,他就可以透過 user id 直接去這個 Storage 特徵值並坐後面的計算,這樣的好處有
但這裡有一個要注意的是在實時計算的 Pipeline 中,有些計算行為並不是 Stateless 的,舉例來說: "過去一分鐘的登入次數",你可能會需要用一個移動窗口來計算,這時候會有一個 KV Store 存的是每個 user 在窗口內的登入次數或說每次的登入時間,這類的 "State" 我並不建議放到 Storage 中,而是使用額外的 State Control Component,這在明天的內容會再展開延伸
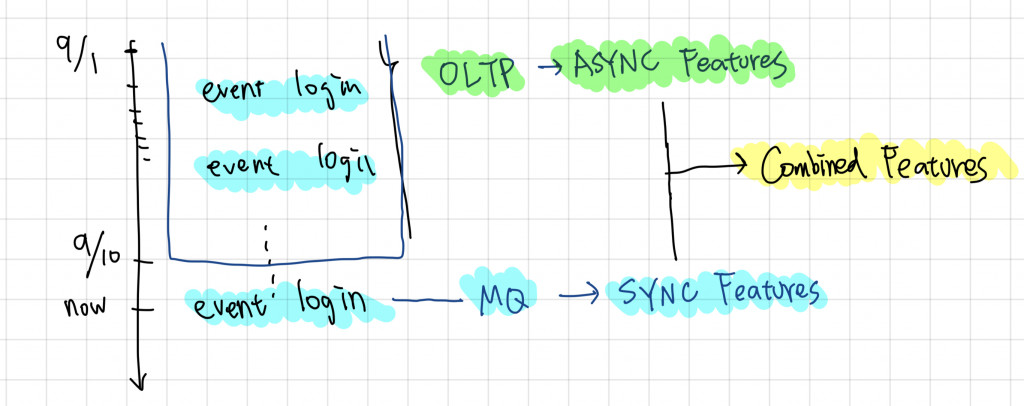
另外有些特徵是透過 Sync 和 Async 做組合的,舉例來說你"想觀察一個用戶今天的行為跟他之前的行為有什麼不一樣",之前的行為你可以用它過去一年的行為來做基準,然而一年行為的計算量是非常高的,如果全部都用 Sync Feature 計算,你會需要存下非常多的 State,這樣會消耗大量昂貴的 State Resource,所以這類特徵常會用拼接的方式
舉例來說我想看一個用戶"這一次登入的 IP 是否是他過去常用的 IP"這特徵,我們就可以透過以下兩個特徵組合:
這裡可以很明顯地看到這些 Sync Feature Pipeline 有一個問題,在實驗階段,我們都是透過一個對 OLAP 資料庫的資料寫 Query 而得到特徵,然而在轉換成 Sync Pipeline 時,我們只移植了"邏輯",但很多時候沒有完全復科,這樣的差異就會建立了一個新的 "Bias" 或用更正確的說法建立了一個 Drift,然而這個 Drift 在 Sync Feature 是無法避免的 (在 Async 可以,因為同樣是 Query OLTP),特別是在不同 Streaming 事件的計算中會更明顯
從我們上面的例子來看如果我在 Withdraw Event 去查看 Login Event 計算出來的特徵,很有可能 Login Event 剛好沒有計算的 Resource 或是出現 Error 導致沒計算出最新的資料,而這時 Withdraw Event 就去 Storage 查找,因此拿到了空值或是舊的資料,這雖然也有解決方法,但常常付出的成本遠高於帶來的效益,因此通常我們會直接計算這些 Drift 帶來的影響是什麼,甚至直接在模型中做修正
明天我們會在深入講一下這種 Realtime Pipeline 資料 Join 的問題

