
前面提到 Synchronous Features 和 Asynchronous Features 的差異,換句話說也就是 Realtime 和 Batch Features 的差異,為了區分 Spark RDD 來實現 Near Realtime 和 Flink 完全使用 Streaming 的架構,這一篇文章我會用 Streaming 來表示 Realtime Features,今天要來講一下為什麼一個特徵我在 Experiment 時和我在 Serving 時,會有計算上的差異
首先如果今天是一些不用複雜的 Aggregation 的特徵,如"用戶最後的登入時間"這一類的特徵就比較不會有差異,可以用 Two Streaming Join 來做聚合,下面是一個 Two Streaming Join 在 Flink 中的範例:
如果一個用戶的提款 ip 位置突然從美國變成了一個高風險國家,並且該用戶最近沒有瀏覽過任何與旅行相關的網站,那麼這筆提款就有很高的可能是一個ATO 案例
DataStream<Transaction> transactionStream = ...
DataStream<Customer> customerStream = ...
DataStream<JoinedData> joinedStream = transactionStream
.join(customerStream)
.where(new TransactionKeySelector())
.equalTo(new CustomerKeySelector())
.window(TumblingEventTimeWindows.of(Time.seconds(30)))
.apply (new JoinFunction());
事實上上面的 Join 本身是透過 State Management 來達到,也就是說 Flink 內部有一個 Internal State 來幫你計算 user id 為 k, 相關資訊為 v 的 KV Storage,並幫你管理了這個 k-v instance 的生命週期 (多久後 expired),這一個包裝再塗上範例中的 .window() 內被實踐,你也可以透過 Redis 來作為 external state 做到一樣的效果
上述 Flink 程式碼雖然看起來很像 SQL 的 Join,但其實他帶出了一個很重要的觀念就是 Asynchronous:
下圖想計算的特徵是"提款時檢查提款的裝置在過去一小時內被使用的次數"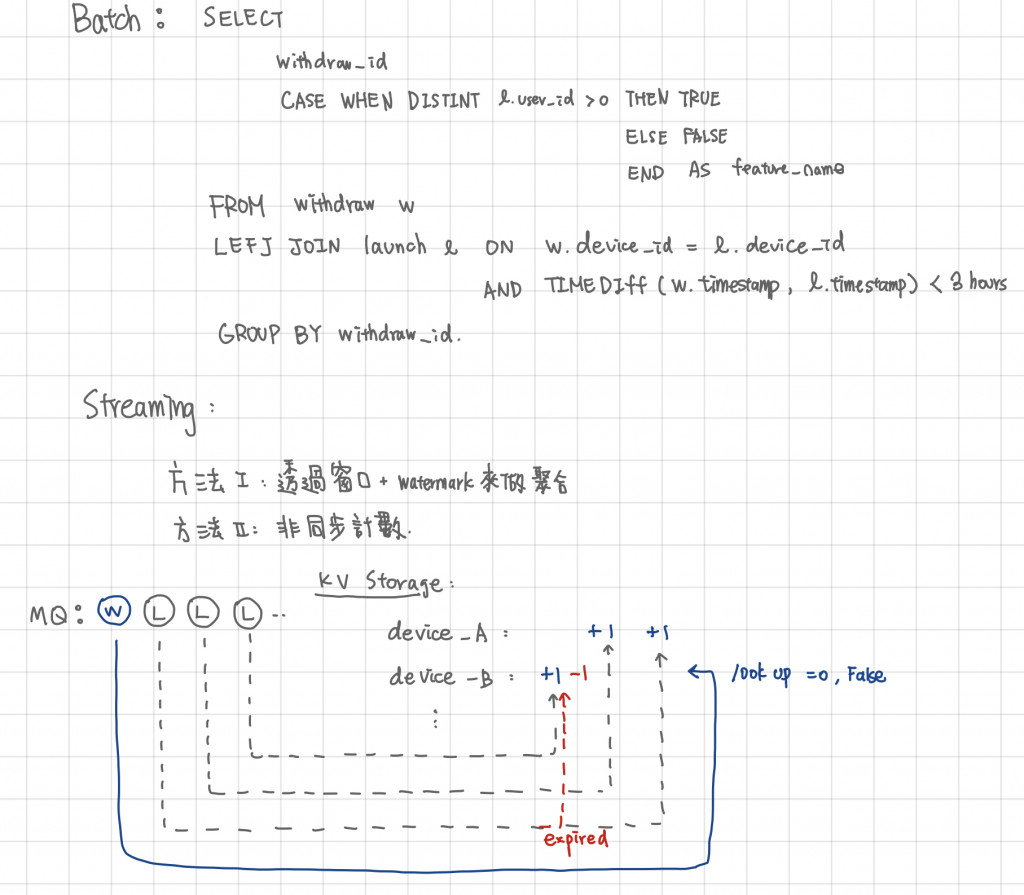
Batch Feature 時很單純,就是一個 LEFT JOIN
Steaming 時,不管你是用 Flink 內建的 Window Function 或是自己的 External State,在做的事情都是:
這時會有一個問題,如果上面我們說的特徵"提款時檢查提款的裝置在過去一小時內被使用的次數"想要改為“提款時檢查用戶提款的裝置在過去一小時內被不同用戶使用的次數"這該怎麼做?
直觀地想,原本的 k 是 Device ID, v 是一個整數的 counting (或是一個 timestamp 更好做到 expire 機制),現在 v 會需要是一個 Pair,包含 user_id 以及 timestamp,這樣才能做到如 sql 中 Distinct user_id 的效果,而這個也可以很好的透過 Redis ZSet 去做實踐
上面的例子就是一個 Two Streaming Join 常見的 Pattern,我自己稱它為 "Counting Feature",這就算是比較複查的 Aggregation (聚合) Features 特徵呢,很快的我們會發現這類特徵隨的 Feature Space 越來越大,很容易會遇到空間瓶頸,這部分可以用到 Cardinality Estimation 相關 Algorithm如 LogLog or HyperLogLog 等演算法來做到近似值,這種方式雖然降低的 Space Complexity 但是因近似值特性會導致 Serving 和 Experiment 的數值有一些差異
