書接上文,我們談論到在單一的 .sql file 內,良好的 CTE naming convention,對於 code as doc 有很好的幫助。然而,當需要共用的前置處理變多時, .sql file 之間的耦合問題,就會讓人抓狂。
換句話說,我們其實可以用堆疊積木的方式來思考。如果用主題 / 基礎款式的積木來分類:
主題式樂高積木組合與傳統無特定主題樂高積木之間的差異:前者會提供能打造一艘海盜船、並讓船上站滿海盜所需的零組件,而你可以選擇需要安裝幾支桅桿、幾門大砲,以及要幾個海盜。我個人可能會喜歡無主題樂高積木,因為能隨心所欲地拼出任何一種東西,但海盜主題的積木組以及盒子上印的參考設計,加快了把積木組合成玩具的時間。
其實,這樣就能很好的理解「一個 200 行以上的 .sql file」 與被拆解開許多中繼表的差別。
你寫好的 SQL code,是否具備在不同場景下,透過拼裝的方式,重現特定架構 / 功能的效果?
阿華炒麵店也認為,比起每天準備 6 種麵團,不如換個思路好了:我始終都只準備 2 種麵團,再依照當天所需的訂單分類,再決定要將上述兩種麵團,特製成訂單所需的狀態。這不只減少了成本損耗(因為 2 種麵團可以互相支援)提升利潤,更讓阿華在招實習生的時候(交接文件),非常輕鬆的說明備料工作該如何進行。
回到技術端,我們先不進入 dbt 具體的架構是什麼(how to do),而是先聚焦在他解決了什麼問題(what it solved)。
參考下圖,每一個框框就是一個 .sql file 建立的 view,彼此之間用 { ref() } 的方式互相引用。所謂的 view,是指將 sql code 暫時儲存起來。當該 view 被叫用的時候,才會消耗對應的 query 運算資源。跟 stored procedure 最大的差別(雖然兩者都被用來封裝 sql),就在於 procedure 具有更多複雜的功能(可以封裝 DML,執行 CRUD),但 view 相對單純,可以被視作單一的資料來源(就是 CTEs,XD)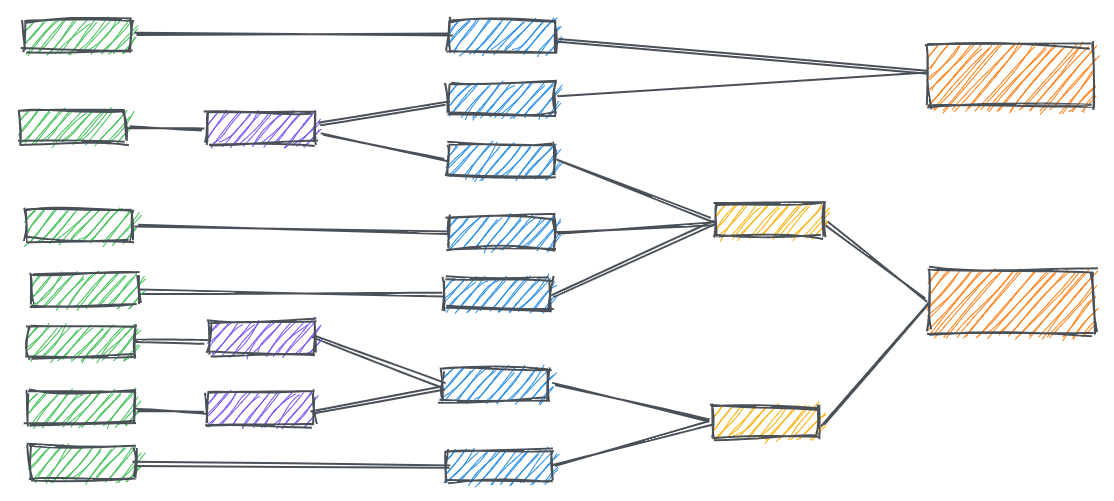
在 dbt 的系統中,會將不同的 view 做分類:
阿華炒麵得以復活,需要 s/o to @stacy_lo,以及 Data modeling techniques for more modularity 的靈感支援,以及 lego modularization 中極好的例子。
明天讓我們回到阿華炒麵店的例子,來看看 dbt model 的外觀具體是如何運作的吧!


 iThome鐵人賽
iThome鐵人賽