前面我們也有提到滿多次Tokens的概念,中文又叫分詞
像是GPT模型會看到GPT-3.5 turbo 16K、gpt-4 32k
這裡的16K就是支援的Tokens數量,就是一次可以輸入+輸出 16000Token數量的長度
我們再用ChatGPT時候一定常遇到,too long 輸入太長請重新再試一次這種問題,就是跟token相關
還有前面提到擁有1750億參數,這裡的單位也是Tokens
可能還會常看到一些開源模型寫什麼 7B、13B、70B這裡的B是Billion,也是只模型用多少參數訓練
那1 token = 1個字嗎
答案是看情況,有時候可能會是一個單字有時候可能會是一個單詞
像是 台灣科技大學 可能分成
台灣 / 科技 / 大學
台灣 / 科技大學
台灣科技 / 大學
中文又比英文更複雜,具體如何分要看它在訓練模型時用什麼方法
這邊再來看一些例子
這個圖片同色塊代表同token
這邊我們看lollipop,我們今天想把它翻轉,聽起來是很簡單的任務對吧
但對它來說要預測下一個token是很困難的
就會出現這種情況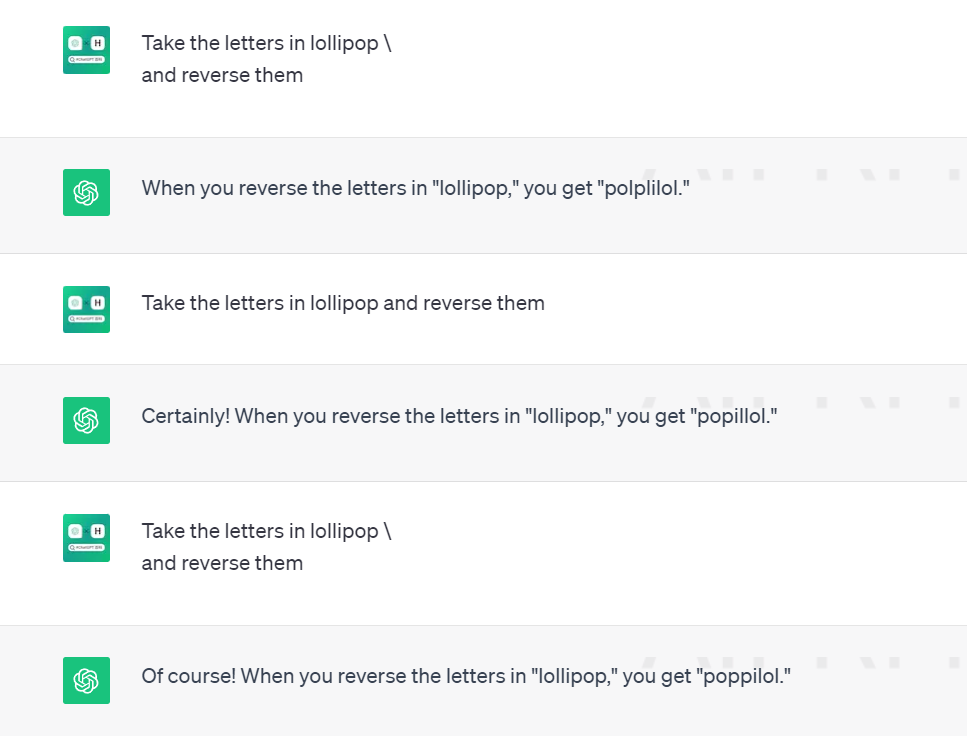
但如果我們在每個字母間加上 "-"
它就可以很好的作翻轉
Take the letters in
l-o-l-l-i-p-o-p and reverse them
每次都不會出錯
Token是文本的基本元素,可以是單詞、子詞、字符或者更小的單位,具體取決於模型的Tokenization策略
Token是模型理解和生成文本的基本單位。模型會將文本轉換為token序列,並根據這些tokens進行計算、生成、理解和回應文本。
還有很重要的就是我們之後要使用API要計算費用,而這費用也是用token計算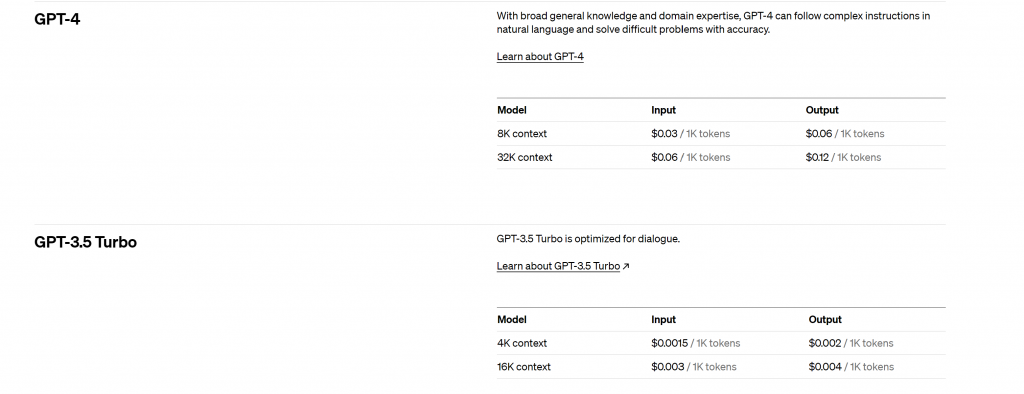
或是之後設計prompt(提示)也不能太長不然會超過它的上限
之後也會介紹套件來計算
喜歡或有疑問的話歡迎留言或來群組討論
https://discord.gg/sFDuct738y
參考
https://easyai.tech/ai-definition/tokenization/
https://learn.deeplearning.ai/chatgpt-building-system?_gl=1lzp3vr_gaNjYzODQzNDU3LjE2OTUxMzA3NzA._ga_PZF1GBS1R1*MTY5NTEzMDc3MC4xLjEuMTY5NTEzMDgyMy43LjAuMA

