使用瀏覽器擴充套件是最簡單的方式,例如: Web Scraper - Free Web Scraping
或是選擇下載安裝 Parsehub、Octoparse、Webscraper.io 等軟體工具。
彈性大、可控性高!
The best Node.js web scrapers for your use case 整理出 Web scraping 常用到的 library
Axios 發送 HTTP 請求、抓取網站的 HTML。
Puppeteer 爬取 SPA 網站資料,也可對 SSR 網站進行 pre-renderedX-Ray 專門設計用來做 Web scraping 的 Node.js library,簡化一般在 Puppeteer 和 Axios 的操作Osmosis 和 X-Ray 類似Superagent 和 Axios 類似,用來處理 HTTP 請求,用法較簡單,常用在 Web scraping 中。Playwright 支援多家瀏覽器,可模擬瀏覽器的操作來取得動態內容。也可控制瀏覽器中的 cookie、事件、網路請求...等—> 先確認網站是否有提供開發者使用的 API 以及 API 文件說明
—> 再觀察想要取得的資料,網站是不是透過呼叫 API 取得
—> 以上都沒有,再來觀察網站是 Single-Page-Application 架構還是 Server-Side-Rendering
由 Server 產生完整的 HTML,才回傳給 Client 端。
可使用 Axios + Cheerio:Axios: 發送 HTTP 請求Cheerio: 解析 HTML 成 Cheerio 物件,可進行類似 jQuery 的操作。
安裝 Cheerio
npm install cheerio
載入 cheerio
import * as cheerio from 'cheerio';
使用 load 函式,傳入 HTML
// $ 為 cheerio 物件,可用於遍歷 DOM 取得資料
const $ = cheerio.load('<h2 class="title">Hello world</h2>');
選取元素
// 利用 class 名稱選取元素,並取得文字內容
$('h2.title').text(); // Hello world
// or 透過屬性名稱選取
const $selected = $('[data-selected=true]');
遍歷 DOM
const $ = cheerio.load(
`<ul>
<li>Item 1</li>
<li>Item 2</li>
</ul>`
);
// 使用 find
const listItems = $('ul').find('li');
// 使用 children
const listItems = $('ul').children('li');
操作元素
// 選取 h2 且 class 為 title 的元素,修改文字為 Hello there!
$('h2.title').text('Hello there!');
// 在 h2 之後插入 <h3>How are you?</h3> 元素
$('h2').after('<h3>How are you?</h3>');
以取得 Fake Python-Fake Jobs for Your Web Scraping Journey 的職缺名稱為例:
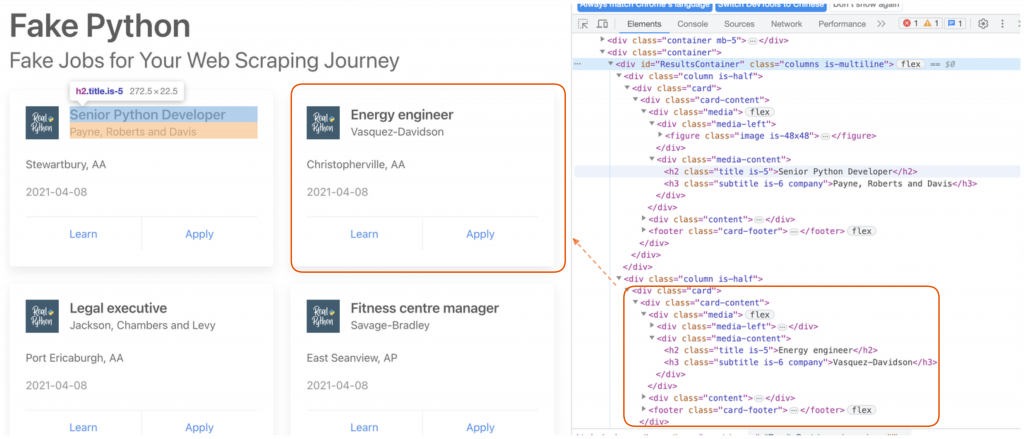
const axios = require("axios");
const cheerio = require("cheerio");
const url = "https://realpython.github.io/fake-jobs/";
(async() => {
let res = await axios.get(url);
let $ = cheerio.load(res.data);
let titles = []
$("#ResultsContainer .card-content").each(function(i, elem) {
let title = $(this).find(".media-content > .title").text();
titles.push(title);
});
console.log(titles);
})()
*補充: THE 8 BEST Websites to Practice Web Scraping 有列出幾個可做 Web scraping 練習的網站
檢視網站原始碼只有基本的 HTML,沒有資料內容。資料是動態載入 js,取得資料後再更新到頁面上的。
可使用 puppeteer。( puppeteer 由 Chrome DevTools team 開發維護。)
載入 puppeteer
import puppeteer from 'puppeteer';
Launch browser (啟動瀏覽器)
const browser = await puppeteer.launch();
// 範例
const browser = await puppeteer.launch({
headless: false,
defaultViewport: null,
slowMo: 10,
});
launch 常使用的 option
| 屬性 | 值 | 說明 |
|---|---|---|
| headless | boolean | 使用 headless mode |
| slowMo | number | 放慢 Puppeteer 操作 (單位: ms) |
| defaultViewport | Viewport/null | 設定每一頁的 viewport |
*補充:Headless mode 代表不使用顯示介面操作。若需要看到 puppeteer 操作的畫面過程,可將 headless 設為 false。
建立頁面
const page = await browser.newPage(); // 回傳 Page 物件
結束瀏覽器並關閉所有頁面
browser.close();
造訪網頁
await page.goto(url, option?); // 回傳包含 HTTPResponse 的 Promise 物件
goto 常使用的 options:
| 屬性 | 值 | 說明 |
|---|---|---|
| timeout | number | 可等待的最長時間 (單位: ms) |
| waitUntil | event strings | load/domcontentloaded/networkidle0/networkidle2 |
load:頁面 load 事件觸發時domcontentloaded:頁面 DOMContentLoaded 事件觸發時networkidle0:當頁面 500 ms 內沒有網路請求networkidle2:當頁面 500 ms 內沒有兩個以上網路請求
等待導至新頁面或是等待頁面重整完成。
page.waitForNavigation(options?);
// 範例
await Promise.all([
page.waitForNavigation(), // The promise resolves after navigation has finished
page.click('a.my-link'), // Clicking the link will indirectly cause a navigation
]);
選取元素
page.$(selector); // 等同於 document.querySelector
page.$$(selector); // 等同於 document.querySelectorAll
對選取的元素執行 function
page.$eval(selector, pageFunction);
page.$$eval(selector, pageFunction);
// 範例
// 取得 link[rel=preload] 元素的 href 值
const preloadHref = await page.$eval('link[rel=preload]', el => el.href);
// 取得頁面上所有 div 的總數
const divCount = await page.$$eval('div', divs => divs.length);
// 取得所有 .options 中的文字內容
const options = await page.$$eval('div > span.options', options => {
return options.map(option => option.textContent);
});
等待 timeout 時間過後,檢查傳入的selector 是否已出現在頁面上。
const element = await page.waitForSelector(selector, options?);
// options 包含 visible、hidden、timeout 設定
點擊元素
await element.click()
以取得 Oscar Winning Films: AJAX and Javascript 網站中,2015 年得獎片名為例:
var puppeteer = require("puppeteer");
const getWinning = async () => {
// 啟動瀏覽器
const browser = await puppeteer.launch({
headless: false,
defaultViewport: null,
slowMo: 100,
});
// 開新頁面
const page = await browser.newPage();
// 造訪目標網站
await page.goto("https://www.scrapethissite.com/pages/ajax-javascript/", {
waitUntil: "domcontentloaded",
});
// 2015 年
const year = await page.$('.year-link:nth-child(2)');
const res = await Promise.all([
page.waitForNavigation(),
page.click('.year-link'),
]);
await page.waitForSelector('.film-title');
const filmTitles = await page.$$eval('.film-title', titles => {
return titles.map(title => title.textContent);
});
console.log(filmTitles);
// Close browser.
await browser.close();
};
// Start the scraping
getWinning();
cheerio 官方文件
Puppeteer 官方文件
tutorialspoint - Puppeteer Tutorial
Simple guide to Web Scraping with NodeJS


 iThome鐵人賽
iThome鐵人賽